Computer Architecture¶
resources¶
https://chi_gitbook.gitbooks.io/personal-note/content/instruction_set_architecture.html
Ch1 Computer Abstractions & Technology¶
- chip
- 台積電 pricing 較高但良率很高
- wafer
- 晶圓
- die
- wafer 切出來的一小片一小片
- 晶粒/裸晶
- cost

- 經驗公式
- 台積電工程師提出的
- wafer cost & area
- fixed
- defect rate
- determined by manufacturing process
- die rate
- determined by disign
- throughput = total work done per unit time
- performance = execution time 倒數
execution time¶
- CPU time
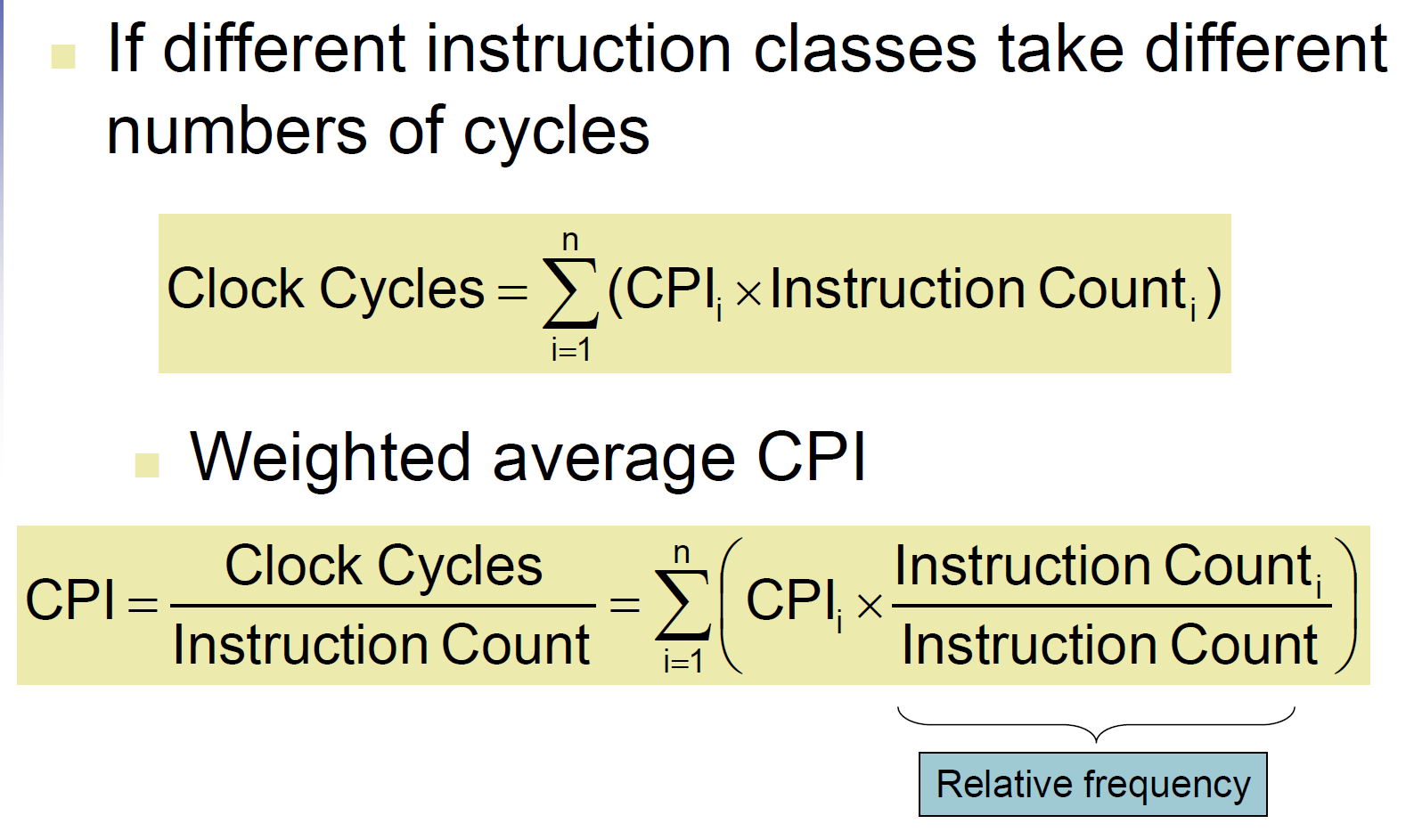
- CPU time = clock cycles x cycle time = cycles / clock rate
- trade-off: clock rate vs. cycle count
- clock cycles = instruction count (IC) x cycles per instruction (CPI)
- CPU time = IC x CPI x cycle time = IC x CPI / clock rate

- 愈高階的語言 CPI 愈高
- \(T_c\), clock period = seconds/cycle-
- ISA, instruction set architecture
- improvement
- improvement factor \(n\)
- \(T_{improved}=\dfrac{T_{affected}}{n}+T_{unaffected}\)
- power
- \(power\propto CV^2\propto f\)
- MIPS: millions of instruction per second

- doesn't account for
- different ISAs between computers
- different complexity between instructions
Ch2 Instructions¶
- instruction set
- e.g. x86, ARM, RISC-V
RISC-V Intro¶
- 較簡單的 instruction set
- regularity → simpler implementation
- simplicity → higher performance, lower cost
- 執行邏輯
- 從上到下,該跳則跳
- 32x64-bit register file
- 32-bit data: word
- 64-bit data: doubleword

- Instructions are word-aligned
- address 一次跳 4 bytes
- little endian
- least-significant byte @ least address
- bytes 不一定要 4 or 8 or whatever 的倍數
- 一個 instruction 是 8 bytes

- 8x8=64
- 12x8=96
- load A[8] to x9
- add x9 & h, store to x9
- x21 在 register 裡面所以可以直接 access
- store x9 to A[12]
b/h/w/d¶
- byte = 8 bits
- halfword = 16 bits
- word = 32 bits
- doubleword = 64 bits
2s complement¶
- 1s complement: negation
- e.g. 0110 → 1001
- 2s complement: 1s complement +1
- e.g. 6 = 0110 → -6 = 1001+1 = 1010
- 要算 8-D → 算 8+2s(D) = 8+2s(1101) = 8+0011 = 8+3 = 11 = B





signed & unsigned¶
- signed
- 有正負
- 表示負數方法
- 最左邊 1 → 負
- complement (1s 2s etc.)
- unsigned
- 只有正數
sign extension¶
多加幾個 bits

offset¶

array¶
-

-
e.g.

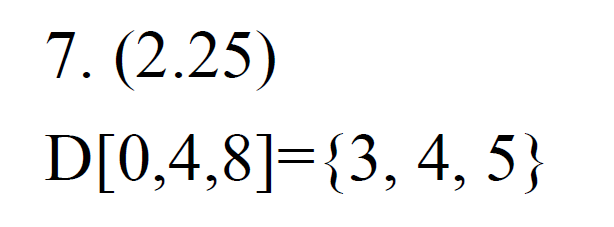
- x30 = x10 是 array D 的指標
- addi x30, x30, 32 代表跳 32 bytes i.e. 跳 4 doublewords → array index +4
- 若 x30 = 8,0(x30) 代表 D[2],4(x30) 代表 D[3]
- 前面是 offset,加上括號 除以 8 (for doubleword) → array 的 index
- 像這個是 word = 4 bytes

- 像這個是 word = 4 bytes
- see #array vs pointer
- 前面是 offset,加上括號 除以 8 (for doubleword) → array 的 index
- 題目中會一直蓋掉 D[0:3] 的值,直到 x7 >= x5 = 4
encoding¶
overall¶
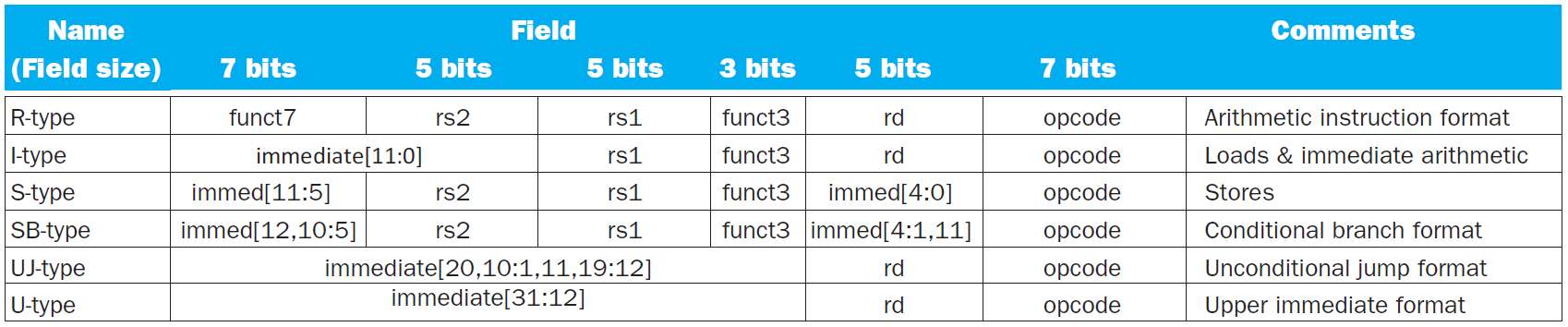
- I SB UJ 的 10:5 位置都一樣
- 都是 32 bits
- major opcode in bits 0-6
- destination register in bits 7-11
- first source register in bits 15-19
- second source register in bits 20-24
- https://stackoverflow.com/a/39450410/15493213
binary representation¶
- 15 → 0xF
- 整個 32-bit format,4 bits 一單位,寫成 8 個 16 進位數字,前面加 0x
R-format¶

- Register-format
add rd, rs1, rs2- funct7 & funct3 & opcode 決定哪一個 operation
- e.g.
- funct7 & funct3 & opcode 決定哪一個 operation


I-format¶
- Immediate-format
operation rd, imm(rs1)
- opcode & func3 告訴電腦要做什麼 instruction (arithmetic OR load)
- immediate: constant OR offset for base address
jalrjalr rd imm(rs1)will jump to the address2imm+rs1&& save the address of next line (i.e. current address + 4) tord- e.g. let x10 = 0x14, and
jalr x10 0(x10)in address0x24, running this line will jump to address0x14&& set x10 to 0x24+4 =0x28 - use
x0asrdif don't care about return address
- e.g. let x10 = 0x14, and
- https://electronics.stackexchange.com/a/553160
SLLI= left logical shift- shift left,補 0
SLLI x10, x10, 2→ x10 shift left by 2 bits
SRLI= right logical shift- shift right,補 0
SRAI= right arithmetic shift- right shift,補 sign bit
- for signed number
- e.g. -8 = 11111000, -8/2 = -4 = 11111100, the right arithmetic shift of the former
- left arithmetic shift 則等同於 left logical shift, so no SRLI
ANDI= bit-by-bit AND operationANDI x20, x10, 3→ x20 = the result of x10 AND 3 i.e. 只保留最低兩位數 i.e. x10%4
S-format¶

- store byte/halfword/word/doubleword
- immediate: offset for base address (rs1)
sb rs1 rs2
SB-format¶
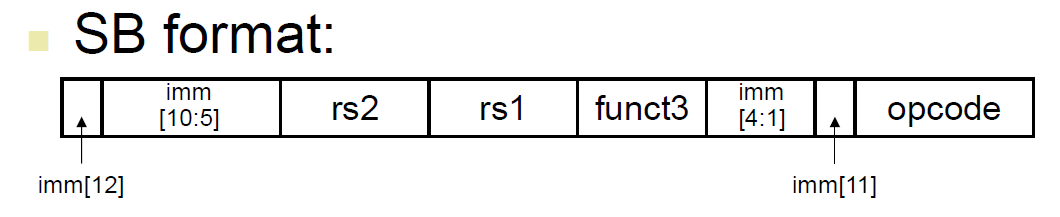
- conditional jump
- if xxxx jump to branch xxxx
- branch addressing
bltbgeetc.- immediate 沒有 0th bit
- immediate 表示要跳多少
- take the branch → go to PC + immediate x 2 (i.e. immediate 後面補回一個 0)
- bc imm omit 第 0 位 i.e. shift right
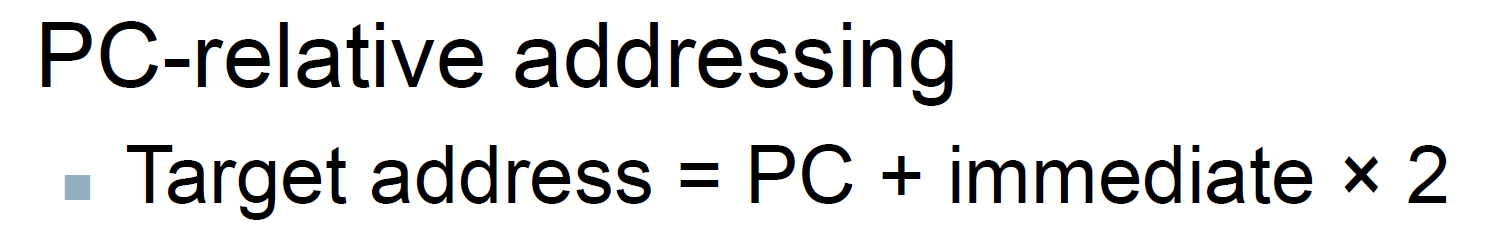
- skip → go to PC + 4 i.e. next line
- 1 instruction 4 bytes
beq rs1, rs2, imm→ jump to PC+immx2 if rs1=rs2
UJ-format (jal)¶
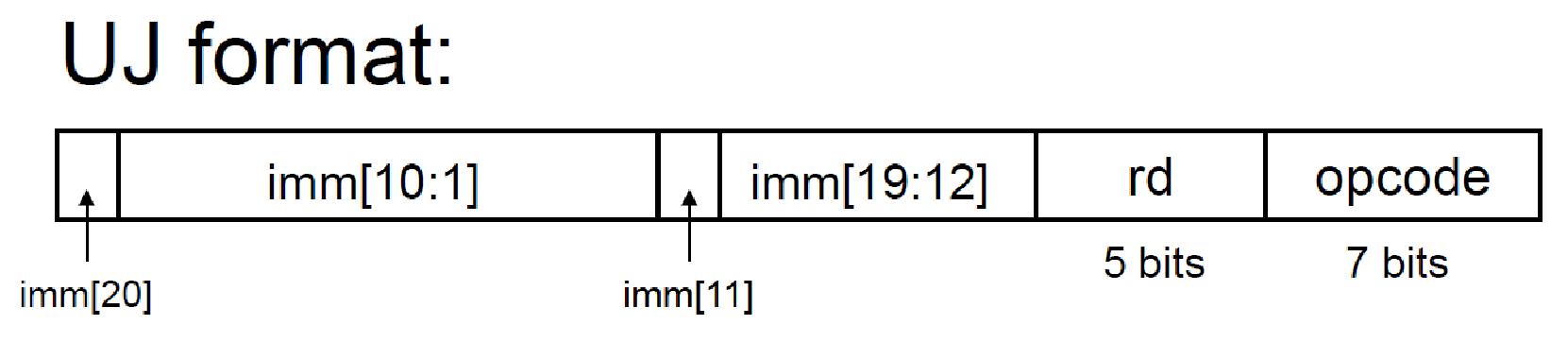
- unconditional jump
- only for
jal, unconditional jump-and-link 
- 20-bit immediate,表示要從目前位置跳多少
- 往回跳 → 負數 (2s complement)
- 1 instruction 4 bytes
- 往後跳 x 行 → immediate = 4x/2 (4x 去掉最後一位的 0)
- jump to address = PC+imm i.e. 目前位置 + imm/4 行
- e.g.

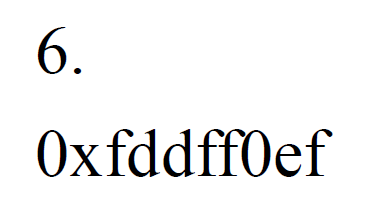
- 往回跳 9 行,每個 instruction 4 bits → imm = -36 = 2s complement of 36,再 shift right i.e. 除 2 i.e. 移掉 0th bit
- jal 的 opcode = 1101111
U-format¶

lui rd constantimm[31:12]= constant represented with 20 bits,把這 20 bits 弄到 rd[31:12]
RV32I Instruction Sets (查表)¶
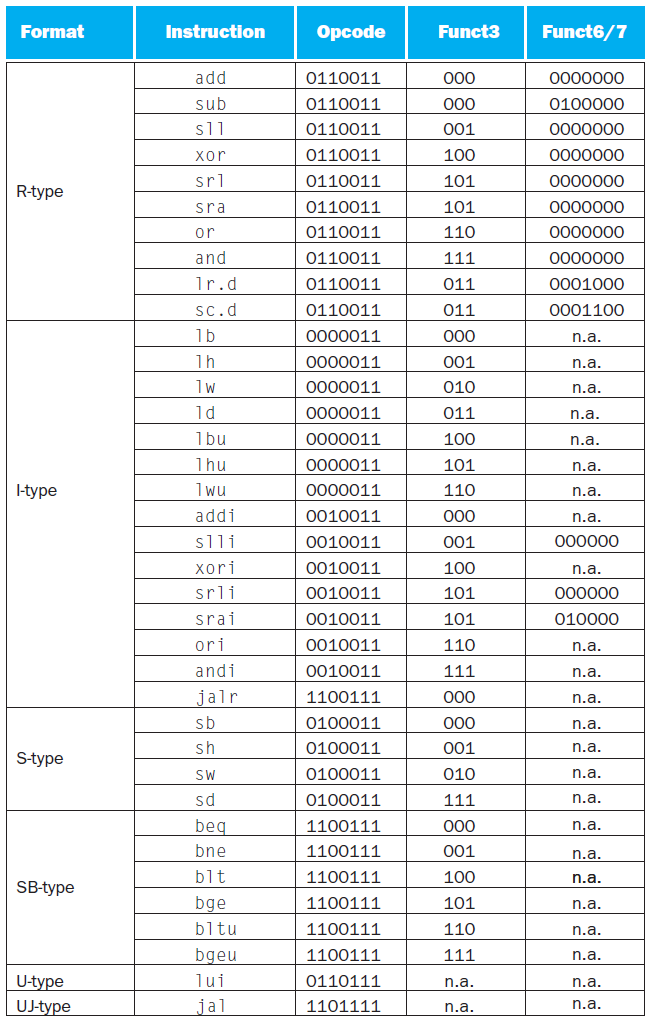
p.119
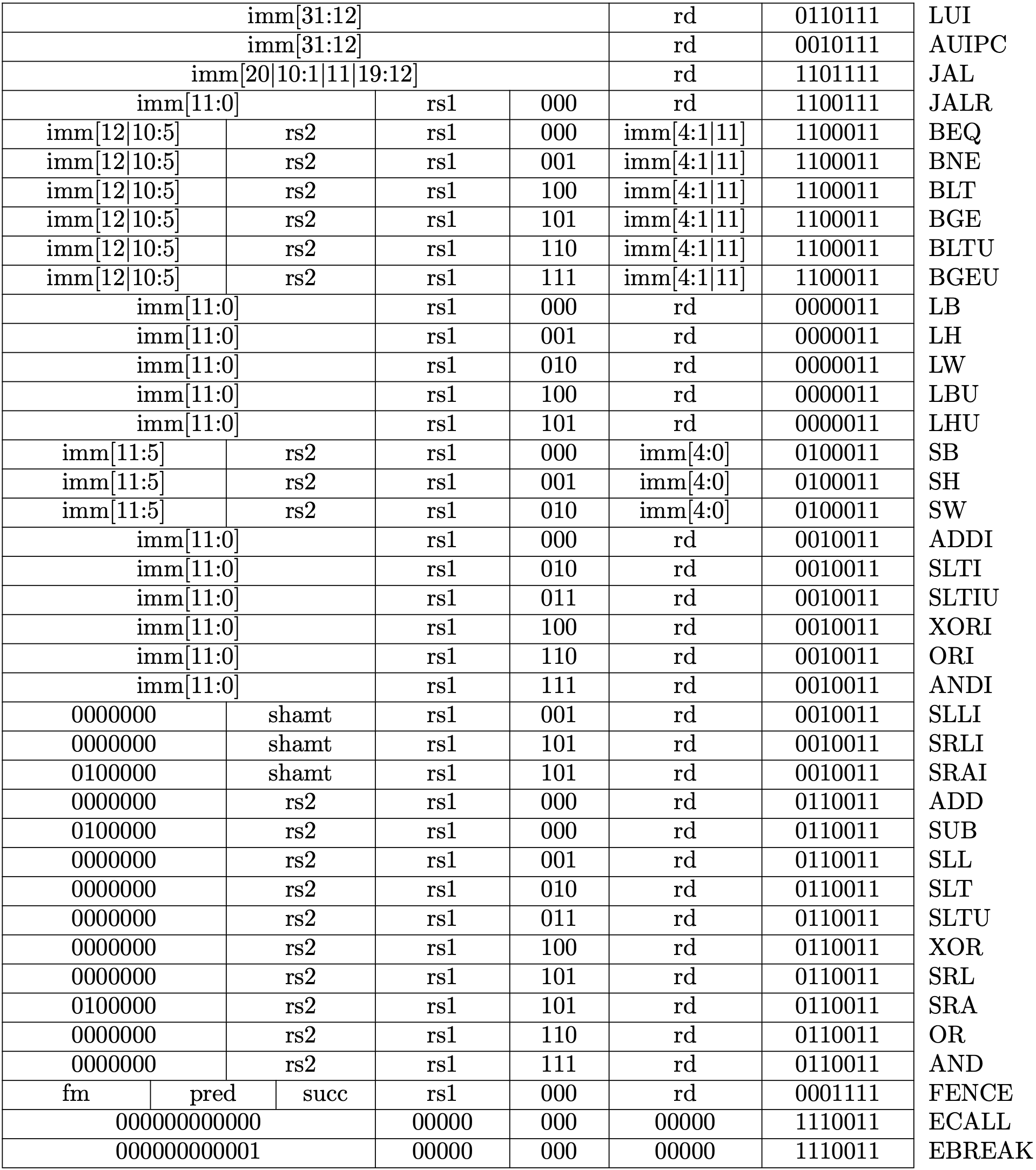
https://book.rvemu.app/instruction-set/01-rv64i.html
I-format LX 的部分,是 load byte/halfword/word/doubleword,以 funct3 值區分
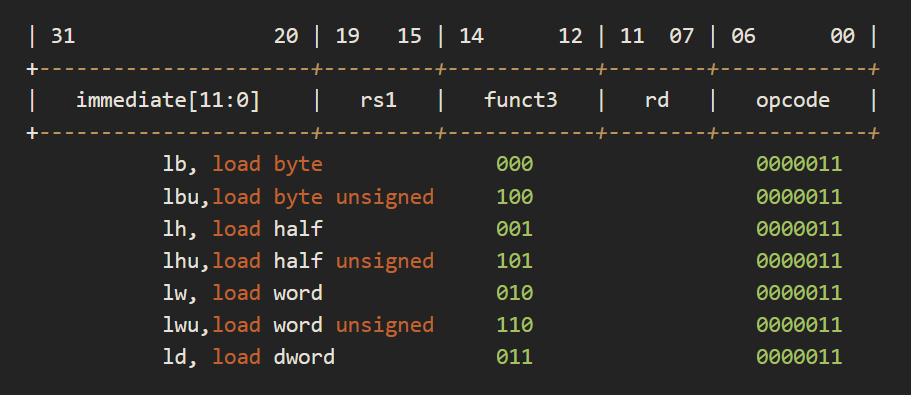
e.g.


RISC-V operations¶
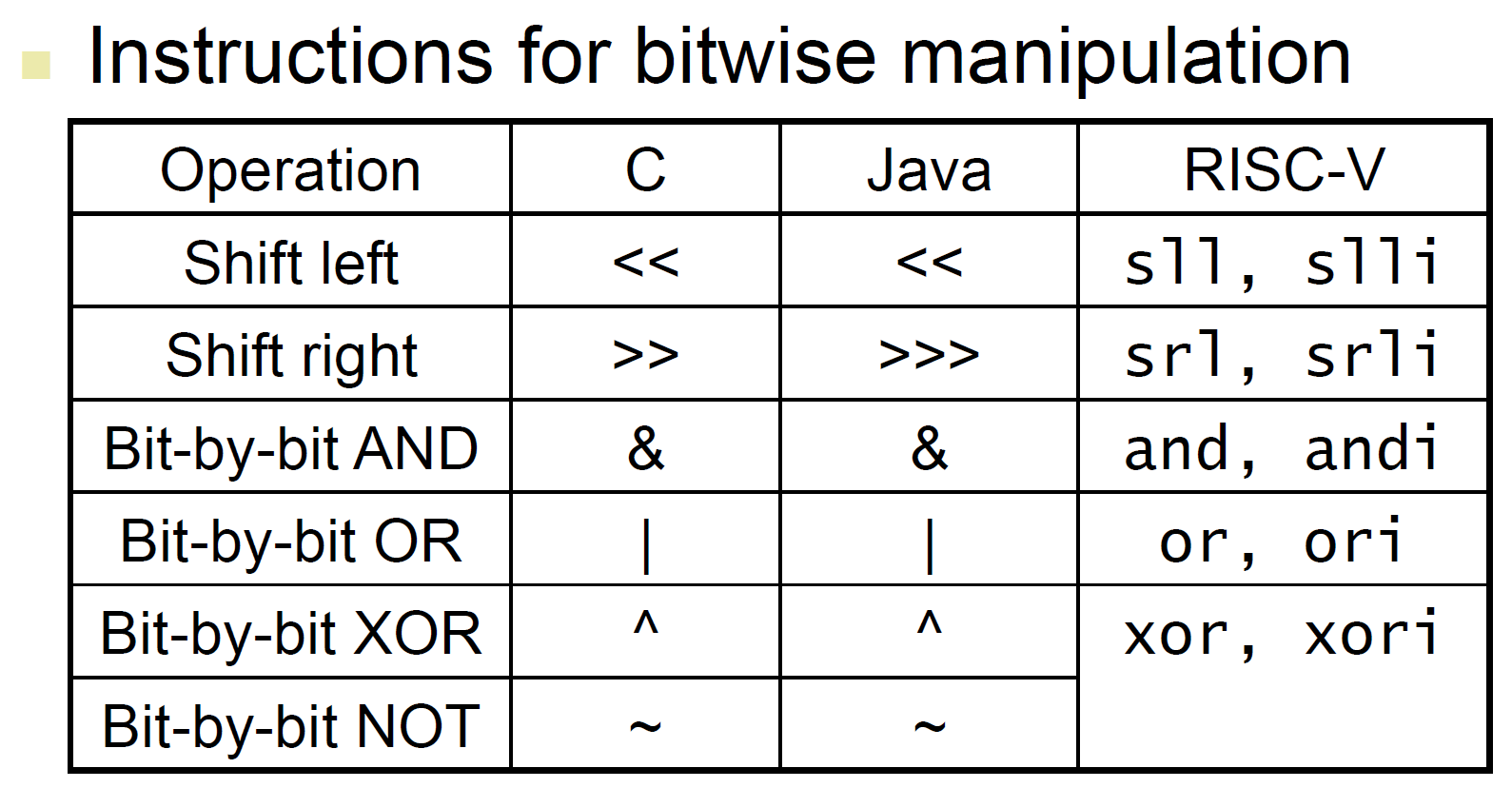
slli a, b, 1 → a = b<<1 (=2b)
addi a, b, 1 → a=b+1
if¶
beq a, b, callback → if(a\==b){callback()}
bne a, b, callback → if(a!=b){callback()}
blt a, b, callback → if(a<b)
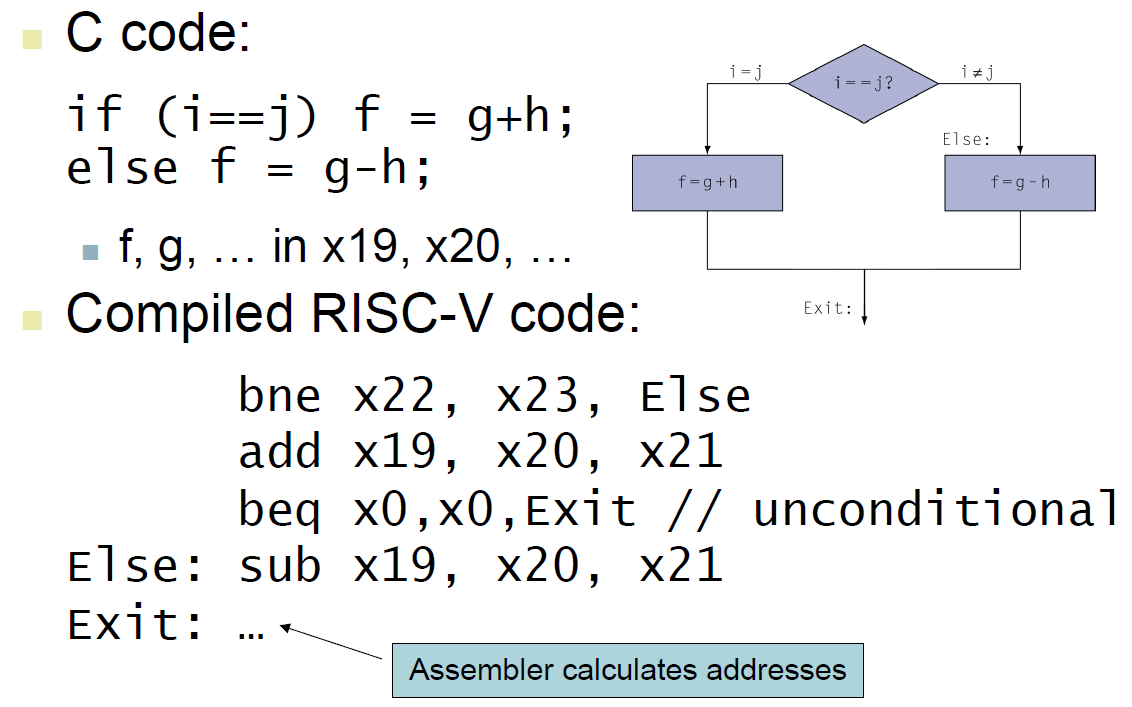
bge a, b, callback → if(a>=b)
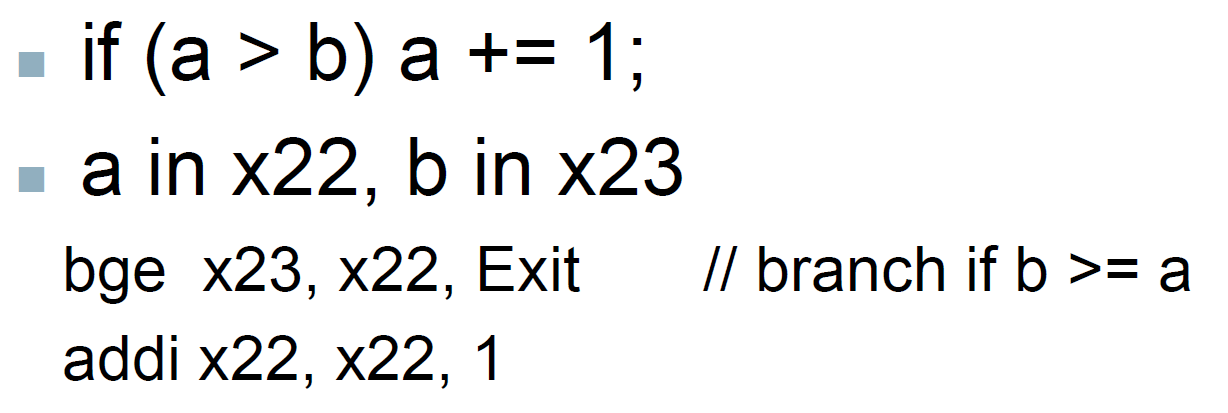
while¶

jump¶
- leaf procedure
- non-leaf procedure
- recursive?




load/store¶

lui

lui x19, 976 → 放 12 個 0 到 976 後面
example¶








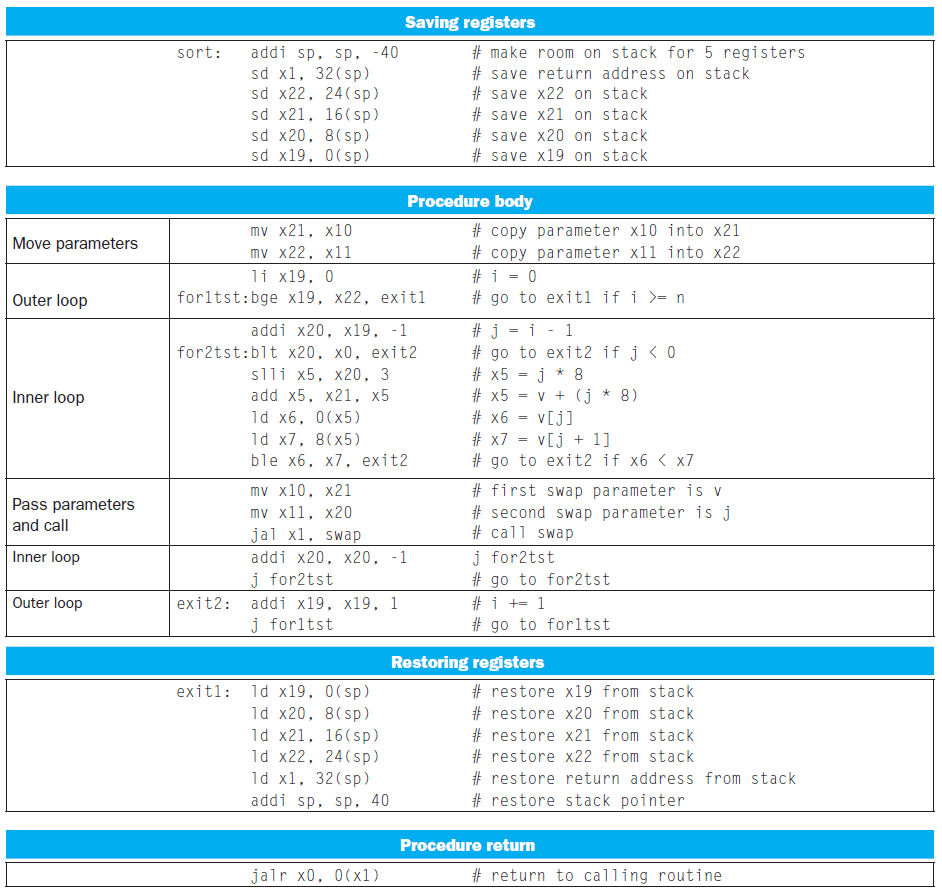
dynamic linking¶
only link/load library procedure when called
- Java just in time compiler
- 根據執行狀況做優化
performance judging¶
- IC (why?) & CPI alone 不是好的 performance indicators
- compiler optimizations are sensitive to algorithms
- Java just-in-time >> Java Virtual Machine
- 直逼 C
array vs. pointer¶
- pointer 省略 indexing 的部分
- e.g.

- x7 = size-1
- array 每次 loop 都要
slli&addslli: 算 i 的實際 indexadd🔢
MIPS¶
- successor of RISC-V

Ch3 Arithmetic¶
- for multipedia
- overflow → 留在最大值
multiplication¶
basic multiplier¶
- 每次 cycle 加一次,要很多個 cycle
- sol: #faster multiplier,空間換取時間
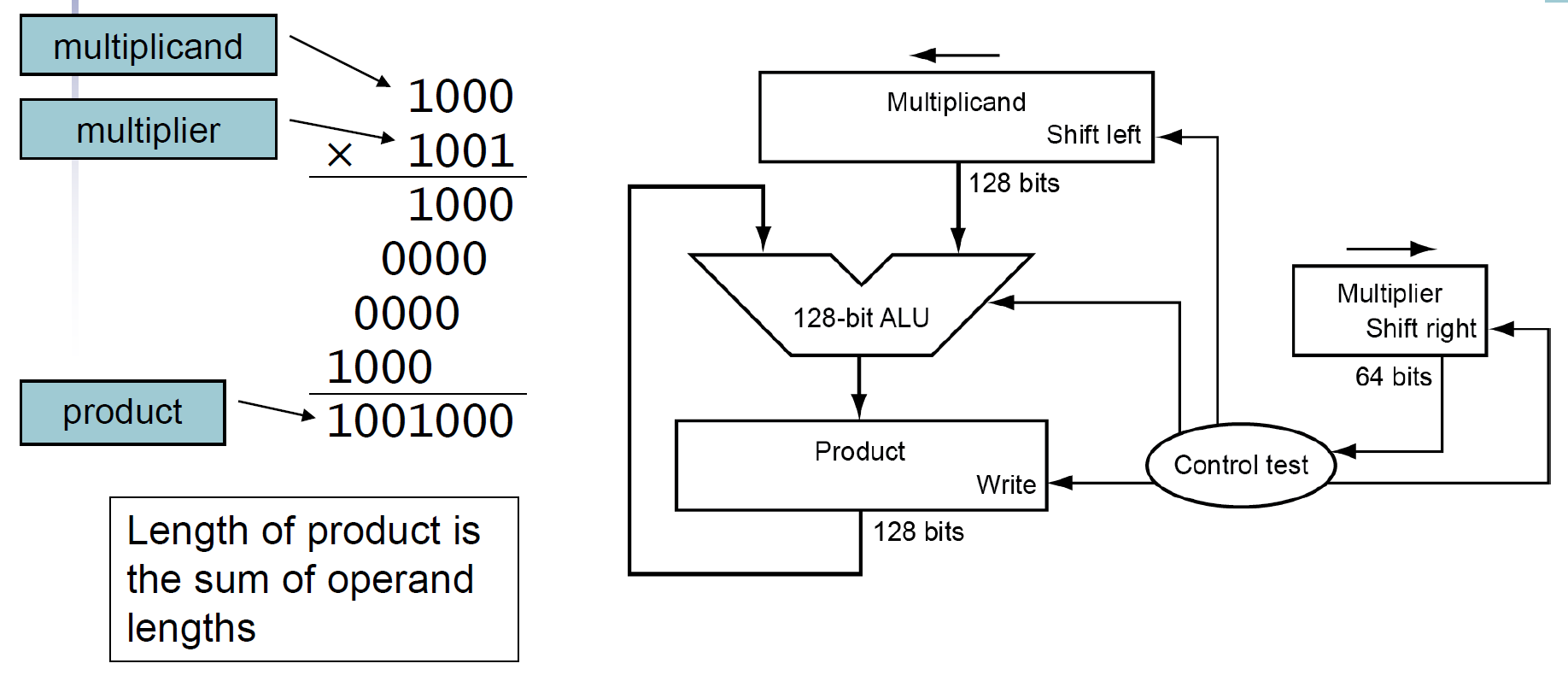
- length of product = sum of multiplicand & multiplier length, ignoring the sign bit
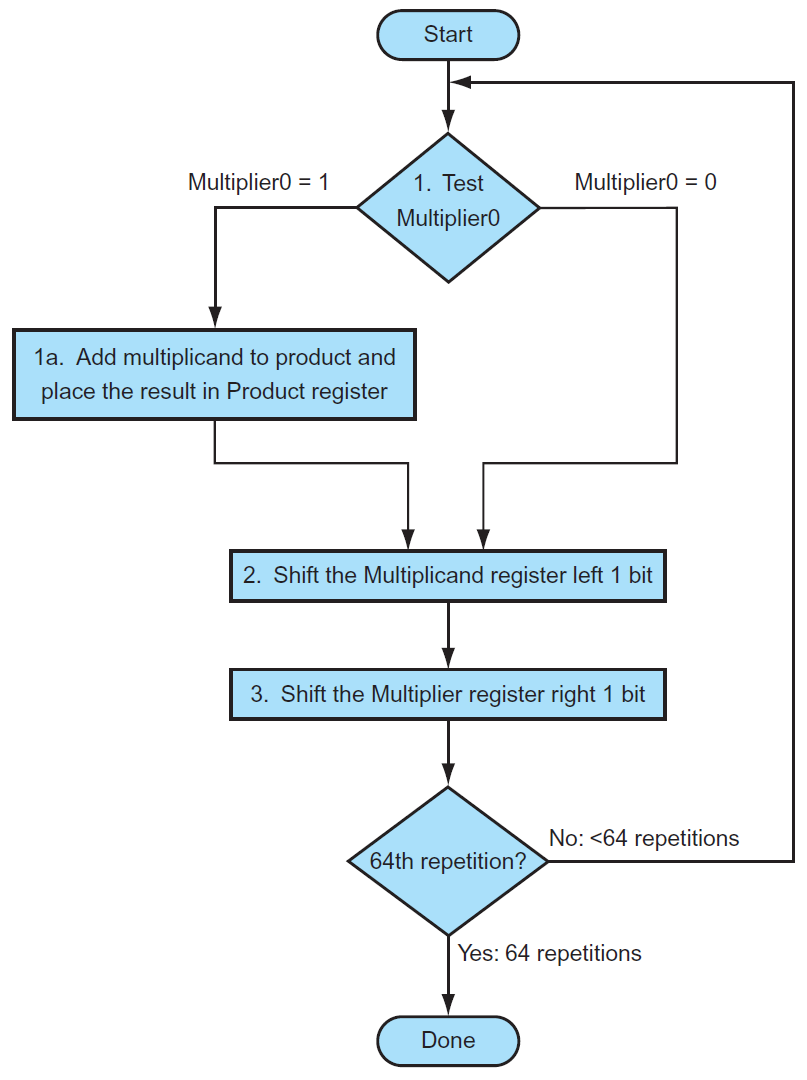
- 每輪都上面 pointer 都左移一格
- 每輪下面 pointer 都右移一格
- 指到 1 → 相加
- e.g.
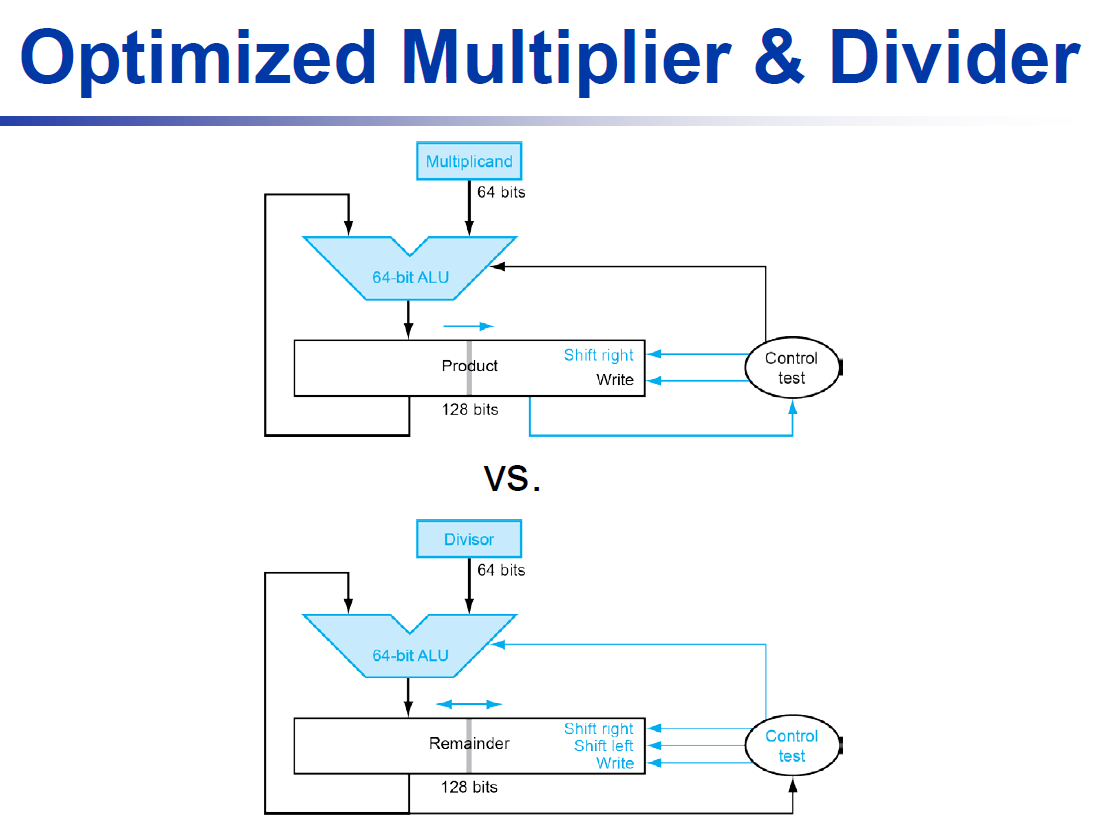
- optimized
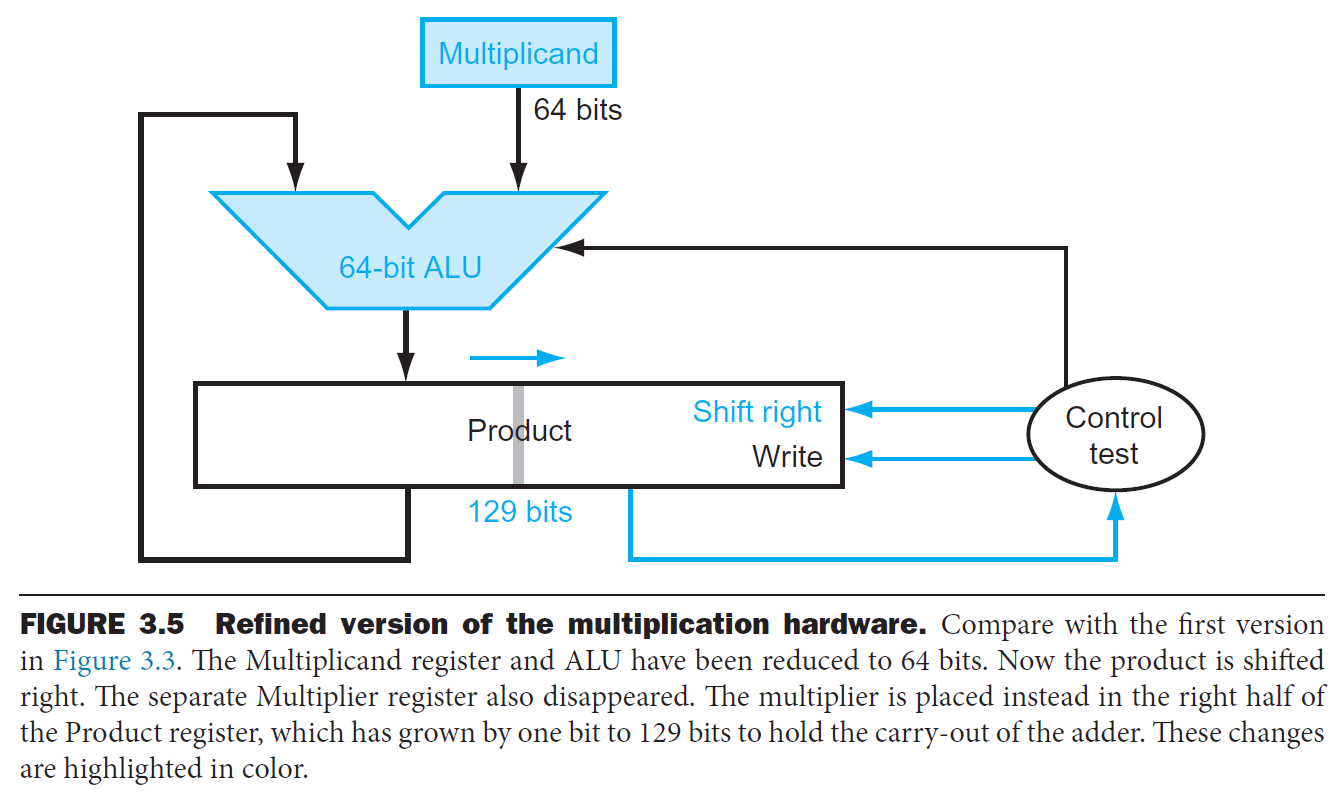
- multiplicand & ALU reduced to 64 bits
- unused portion of registers & adders
- multiplier placed in the right half of product
- e.g.
- ... 不是吧
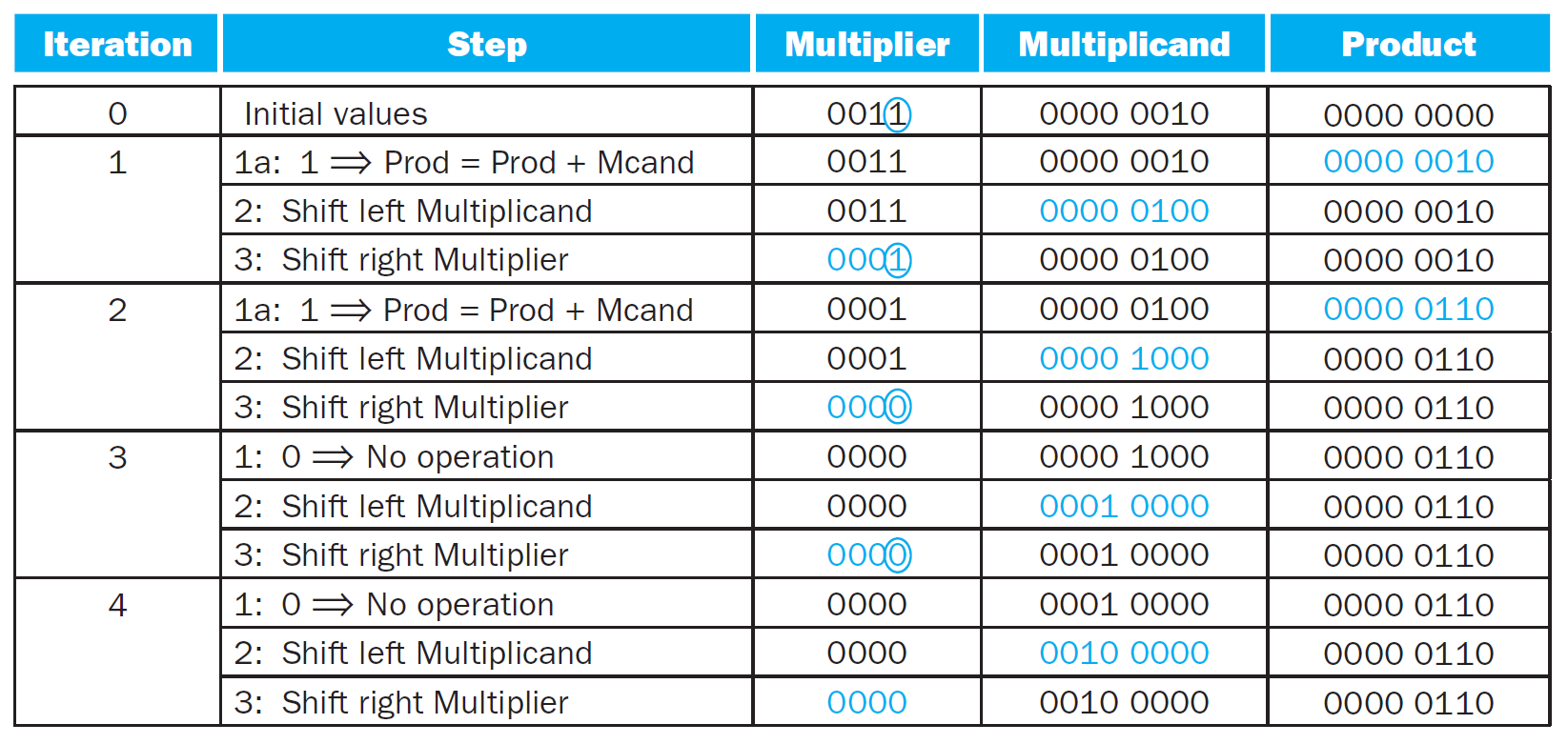
signed multiplication¶
- 先弄成正的,乘完再轉回去
faster multiplier¶
- 用多一點加法器,省下時間
- more cost, higher performance
- cost performance tradeoff
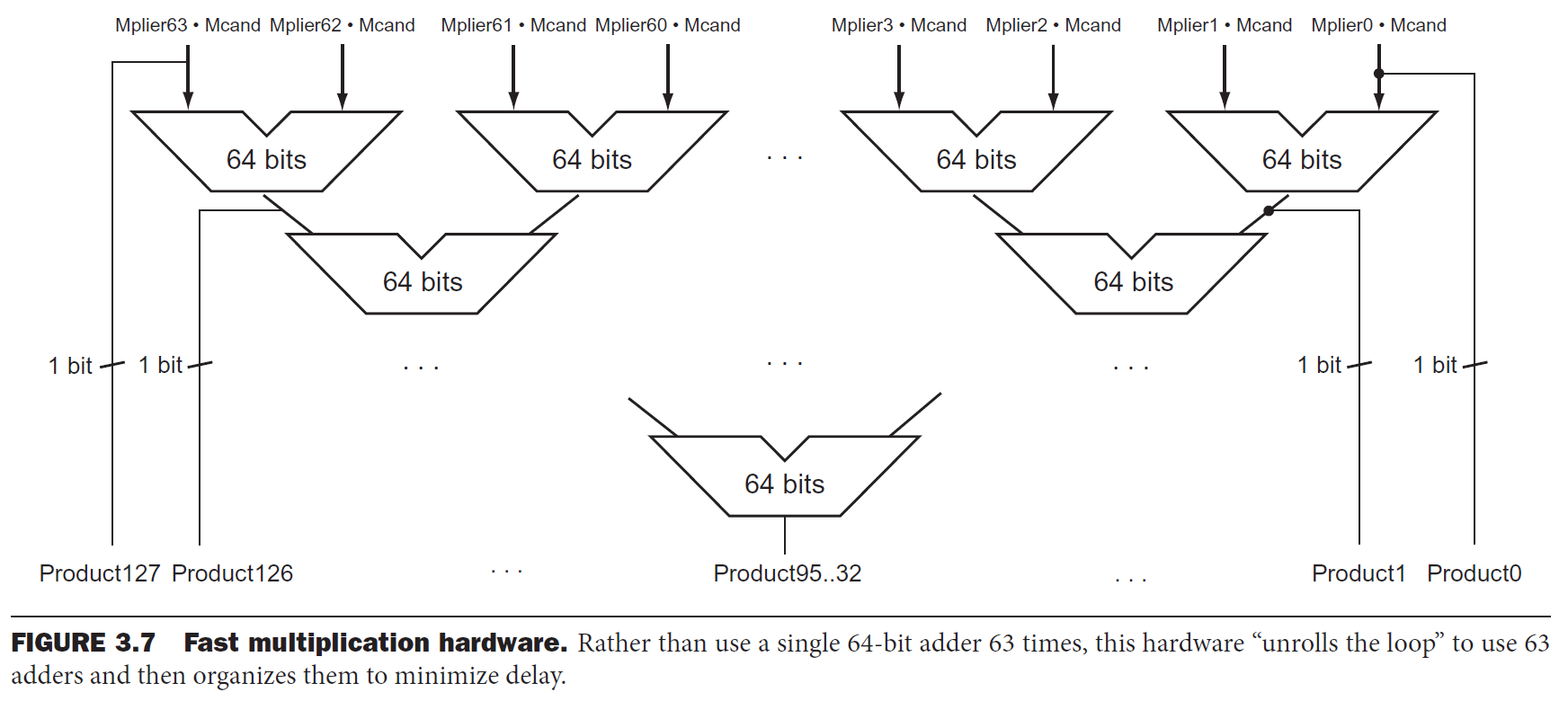
- 可以 pipeline → 可以很多 in parallel → even faster
instructions¶
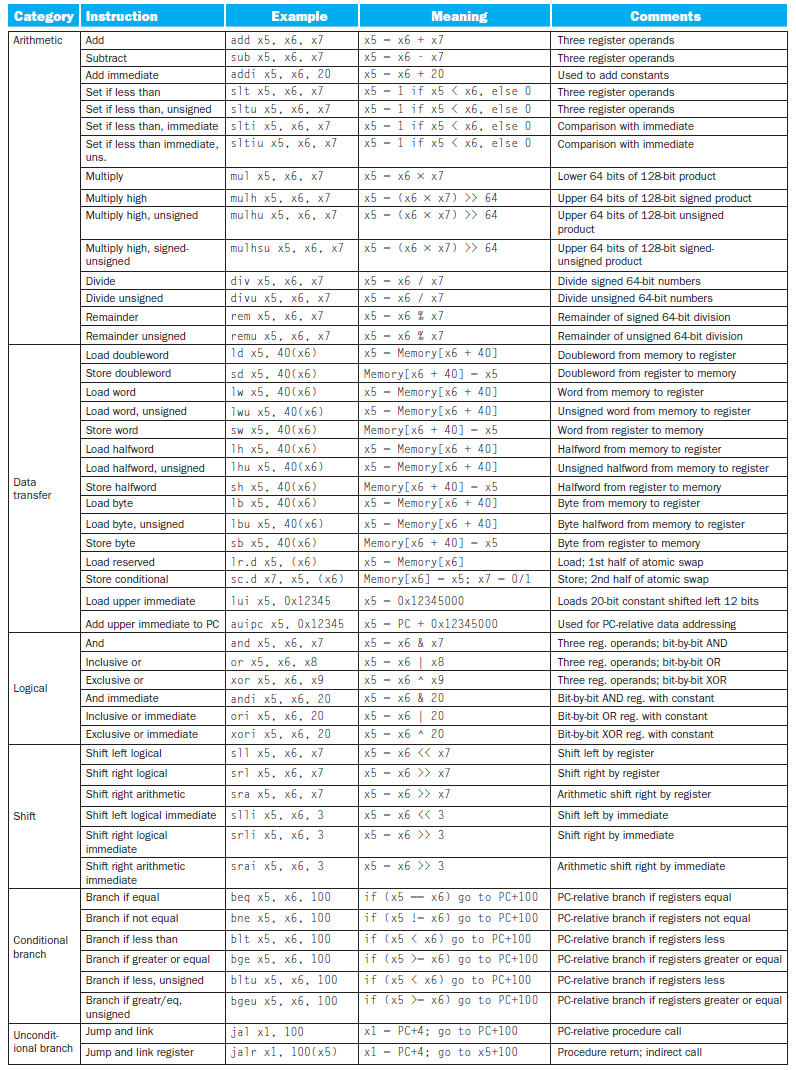
- mul
- multiply
- return lower 64 bits
- mulh
- multiply high
- return upper 64 bits
- can check 64-bit overflow
- mulhu
- multiply high unsigned
- assume unsigned, return upper 64 bits
- mulhsu
- multiply high signed/unsigned
- assume 1 signed other unsigned, return upper 64 bits
division¶
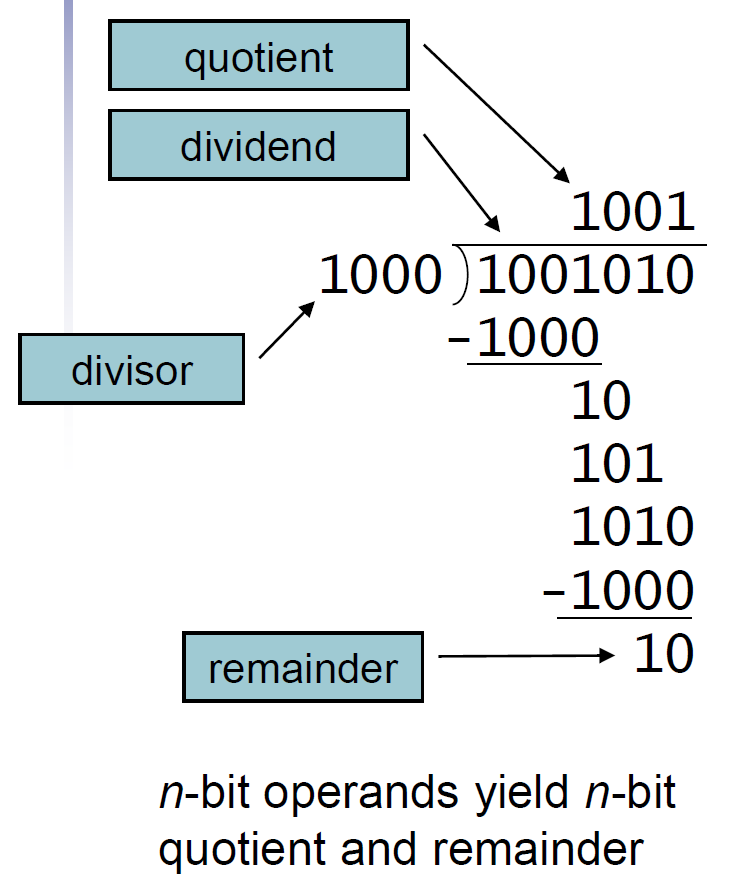
- long division
- retoring division
- 先剪,小於 0 再加回來
- signed division
- abs()
- division 後面 dependent on 前面結果 → 無法 parallel → time complexity 高
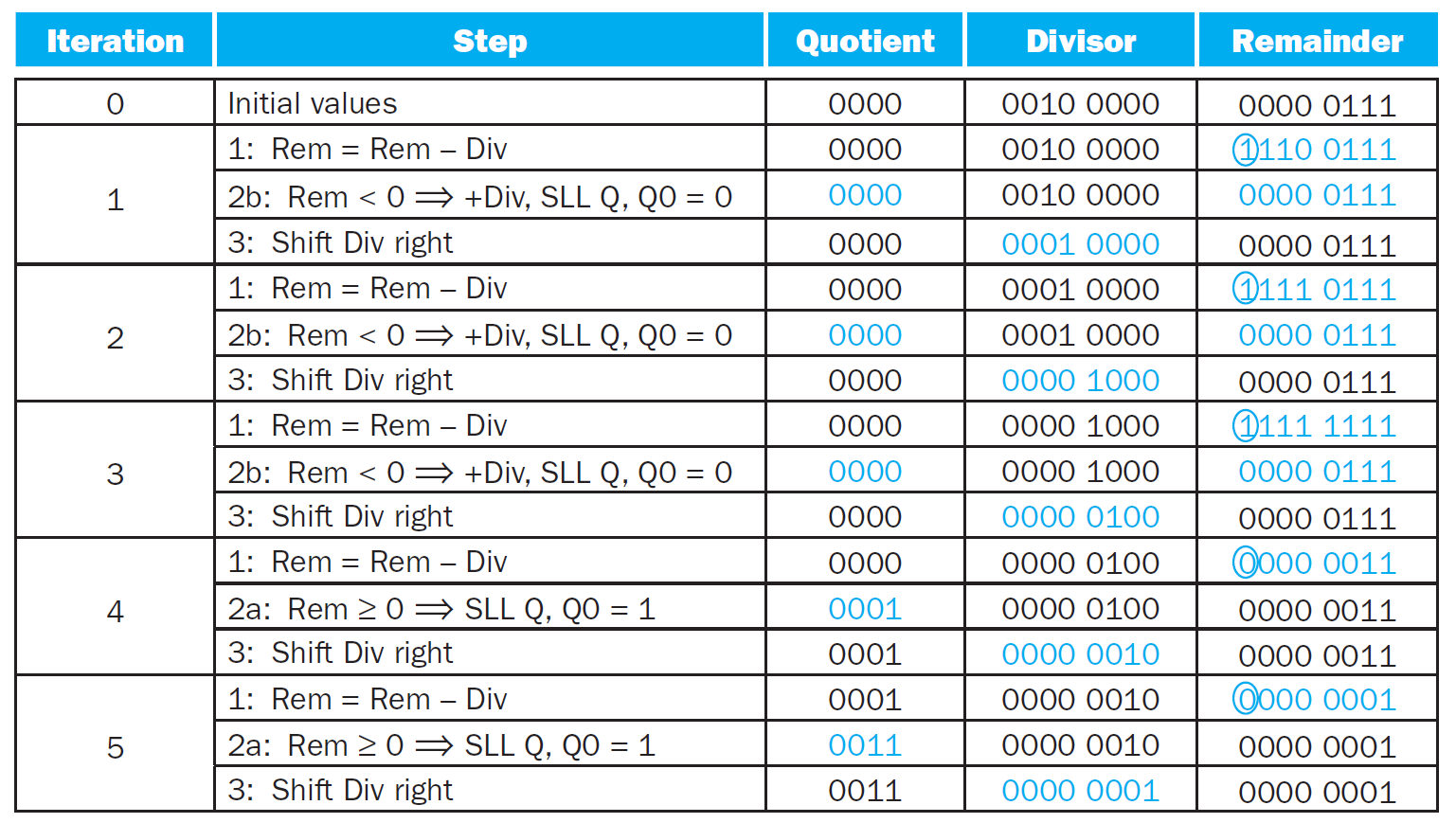
divisor¶
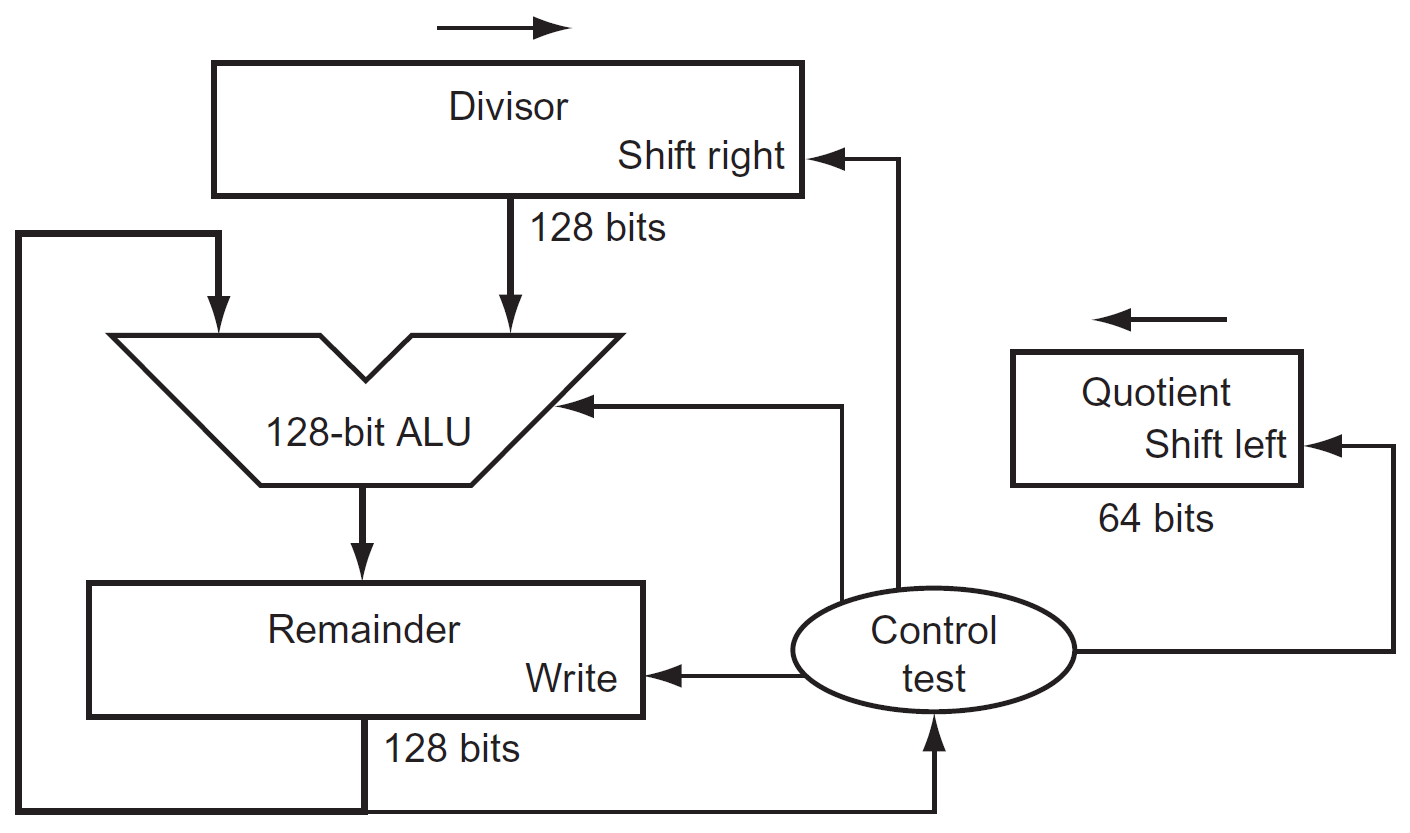
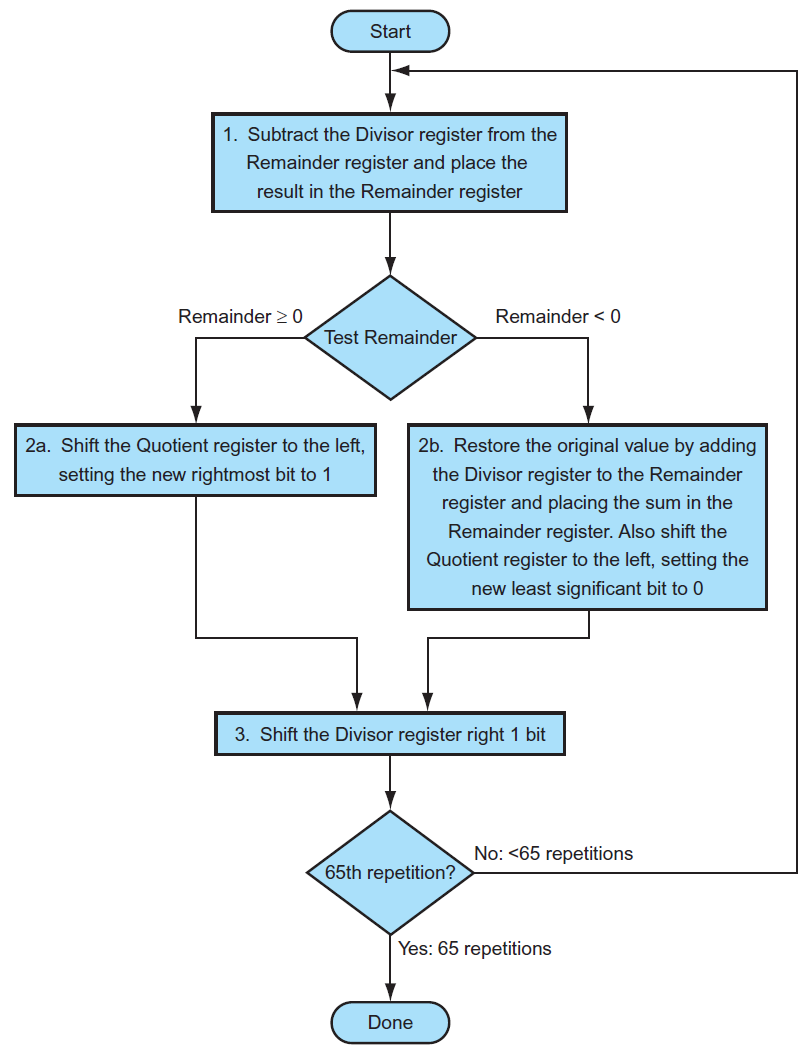
- 每輪 divisor pointer 右移一格,quotient pointer 左移一格
- e.g.
- 4-bit ver. of 7/2
- 4-bit ver. of 7/2
- 每次 cycle 減一次,要很多個 cycle
- optimized divider
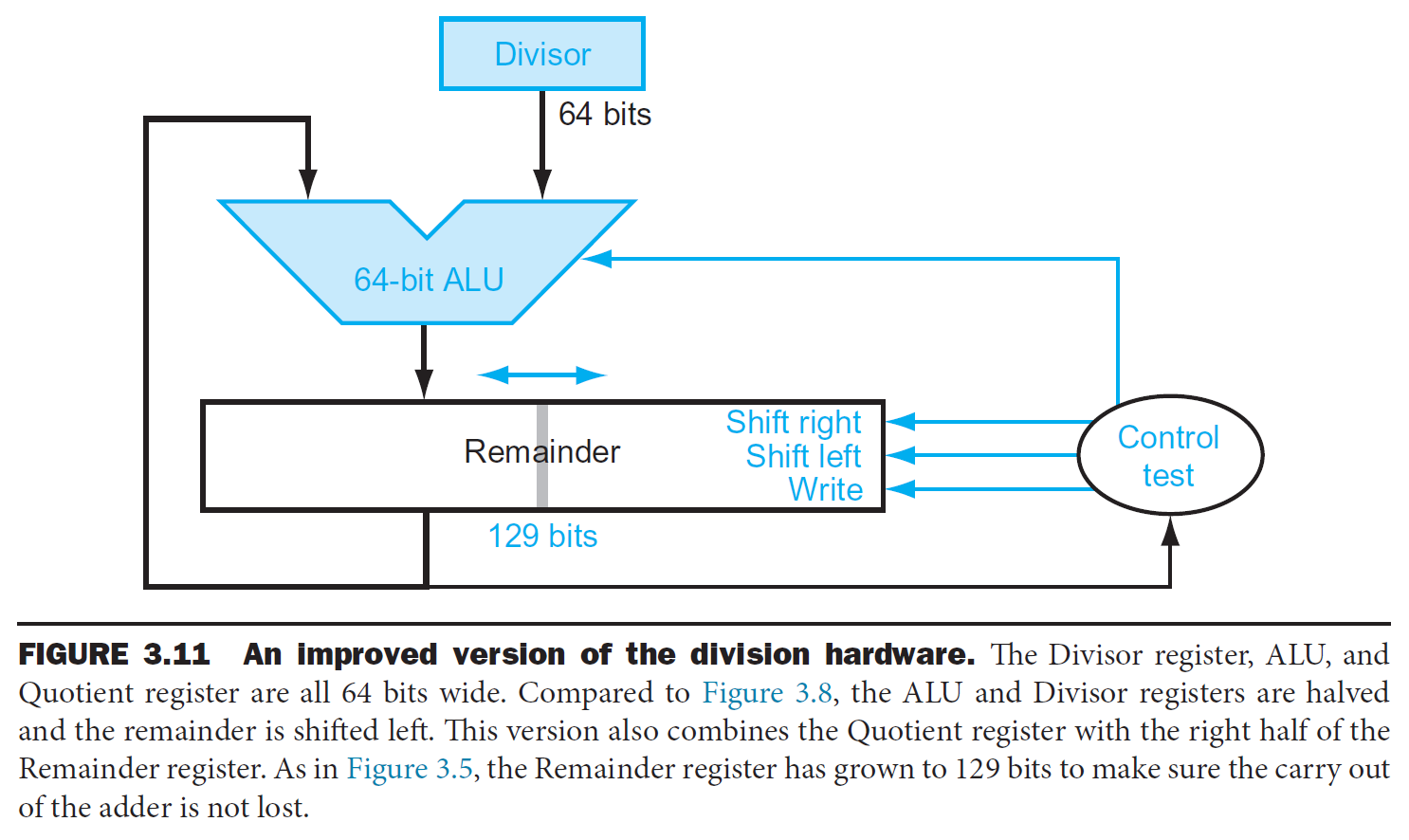
- simultaneously, subtract & shift the operands & shift the quotient
- quotient 放在 remainder 的 right half
- bc remainder 減完會 shift left,右邊會多出一格 → 給新生出的 quotient 用
- divisor register & ALU halved
- like optimized multiplier
- e.g.
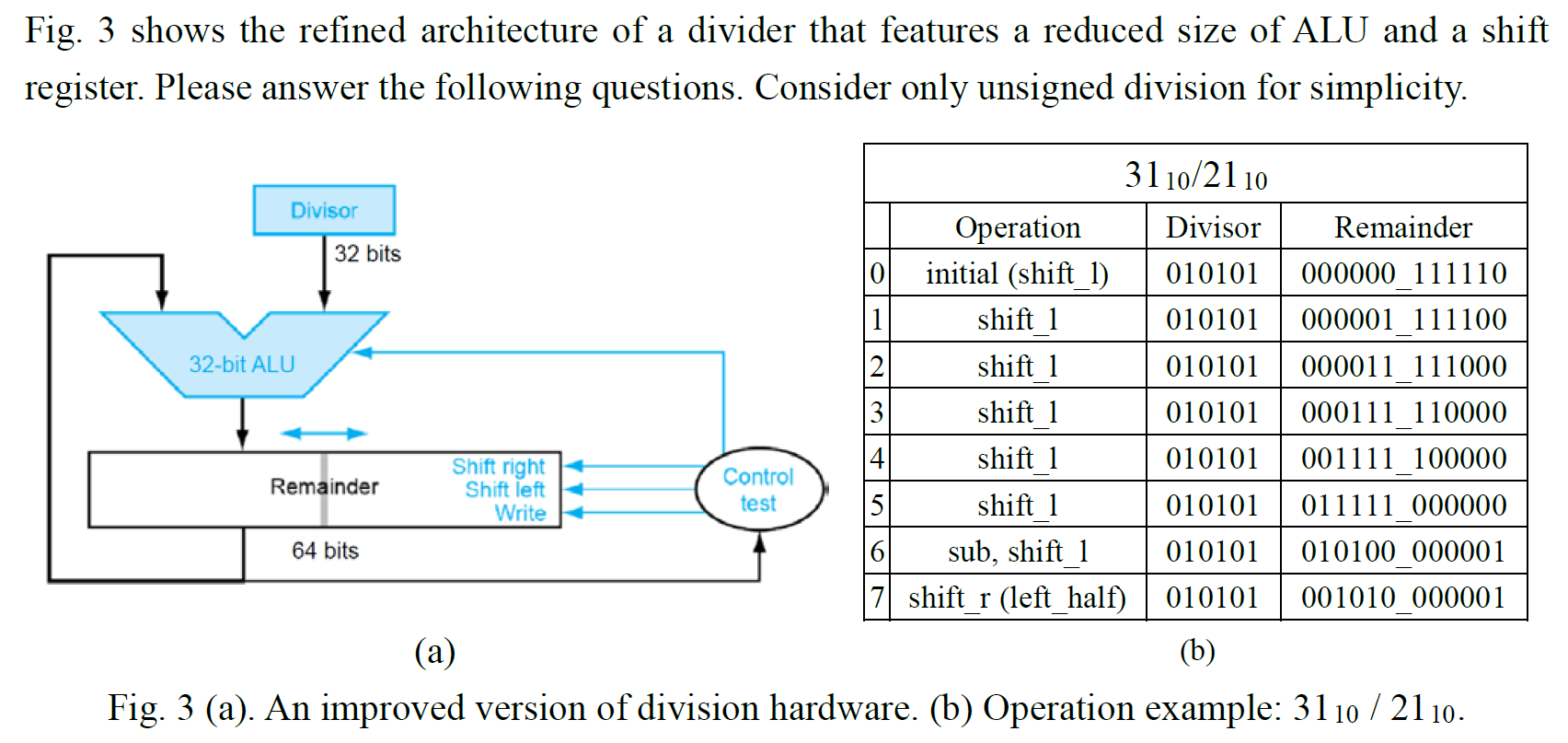
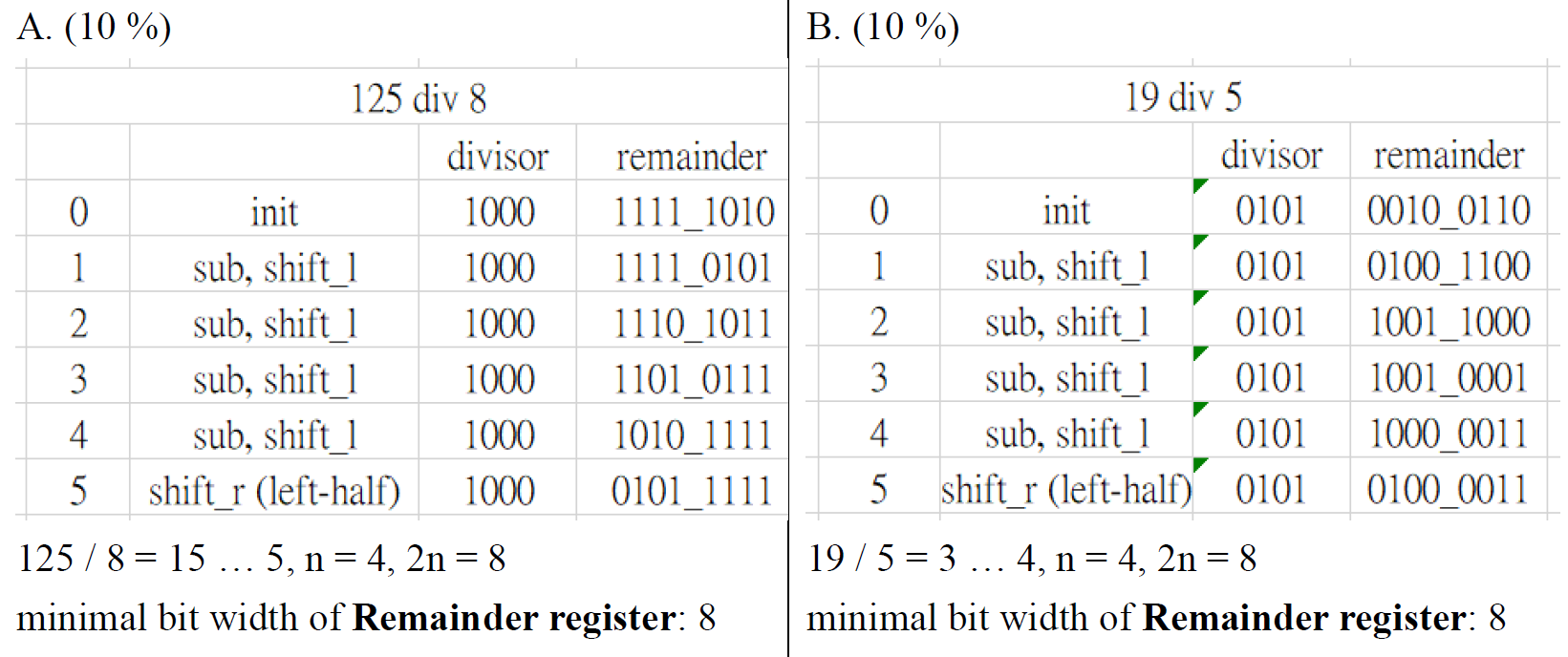
- 4-bit → shift 4 次完就終止,然後 remainder left half shift right (at 5th operation)
- 最後 remainder = remainder left half;quotient = remainder right half
signed division¶
- 正負號不應影響數字
- e.g.
- 7/2 = 3 ... 1
- -7/2 = -3 ... -1 NOT 4 ... 1
- e.g.
faster division¶
- 不能 parallel 因為需要先知道 remainder 之正負才能繼續
- if negative → remainder 要加回 divisor
- SRT division
- predict multiple quotient bits in one step, then correct errors later
- nonrestoring division
- don't add the divisor back immediately if the remainder's negative
- 1 clock cycle per step
- nonperforming division
instructions¶
- div, rem
- divu, remu
- no overflow for 除以 0 & overflow
- return 定義
instruction set with multiplication & division¶
float¶
- 之前介紹的東西都是 integer 的
- \(\pm 1.xxxxx_2\times 2^{yyyyyyyy}\)
- 2 representations
- single precision (32-bit)
- double precision (64-bit)
doublein C
format¶
- IEEE Std 754

- placed this way for sorting purpose
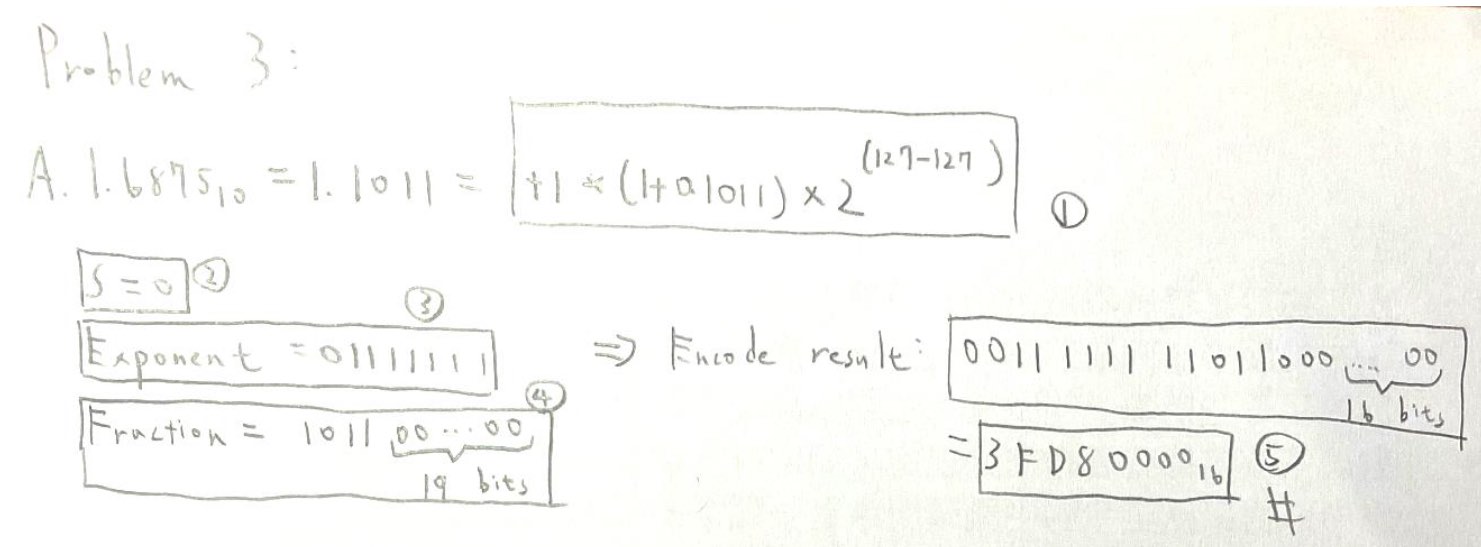
- sign → exponent → fraction
- exponent
- Bias
- 把 exponent 轉成正 → unsigned
- \(2^{-100}\) → \(2^{-100+Bias}\)
- 127 for single; 1023 for double
- simplicity for sorting
- 不然 negative 的 2s complement 看起來很大
- 000..00 & 111..11 are reserved
- single
- min real exponent = 1-127 = -126
- max real exponent = 254 - 127 = 127
- double
- min real exponent = 1-1023 = -1022
- max real exponent = 2046 - 1023 = 1023
- 但 fraction 還是可以有全 0 & 全 1
- single
- overflow: 太正
- underflow: 太負
- Bias
- fraction = 0-1
- single-precision
- min 00000001
- max 11111110
- double-precision
- min 00000000001
- max 11111111110
- e.g.


- 1.6875 to hexadicimal representation
- single encode to double

number representation¶
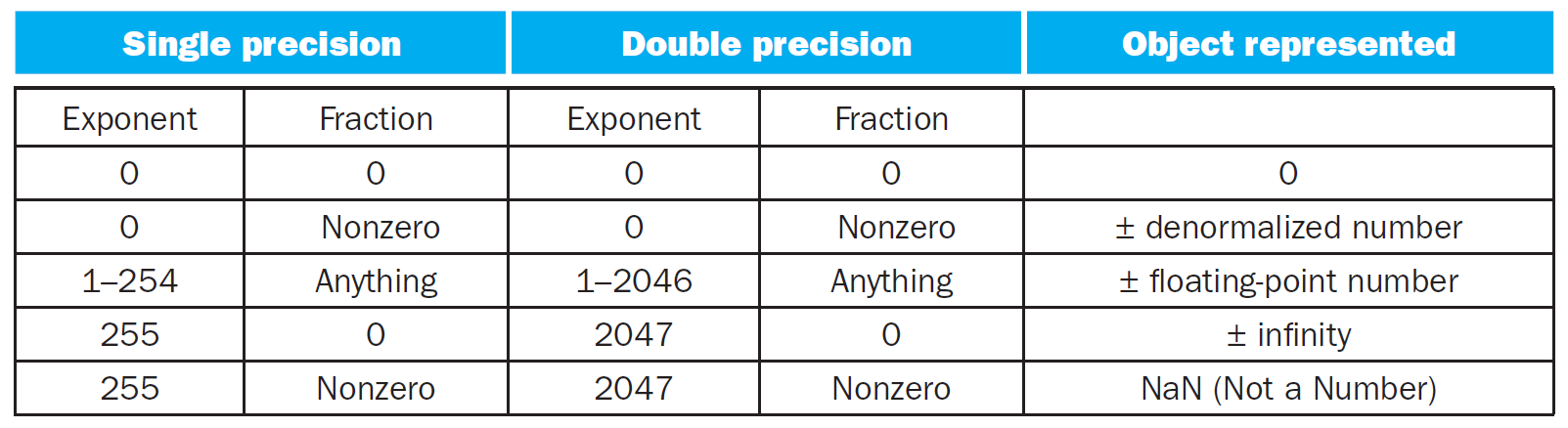
- denormalized number
- exponent = 0
- so \(fraction\times 2^{-Bias}\)
- < normal numbers
- exponent = 0
- infinity
- exponent = all 1s
- fraction = 0
- not a number (NaN)
- exponent = all 1s
- fraction != 0
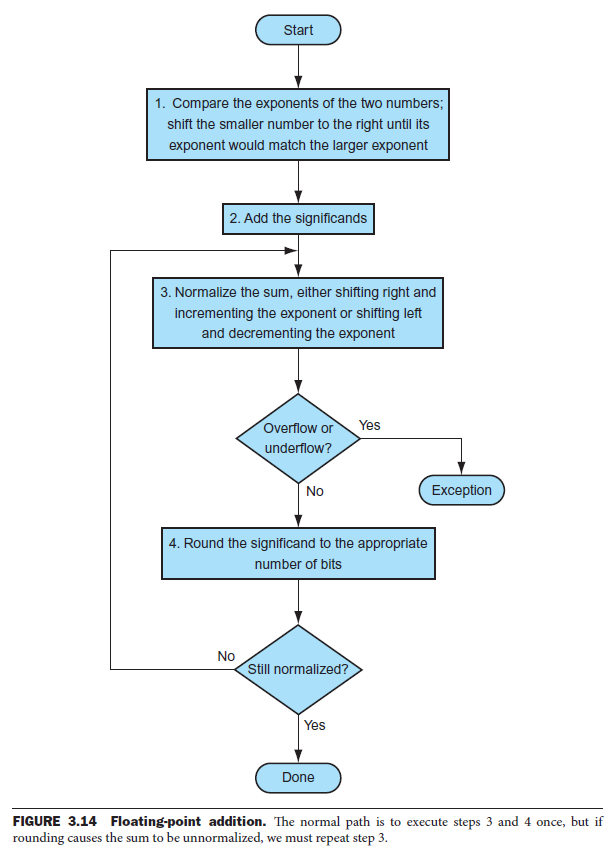
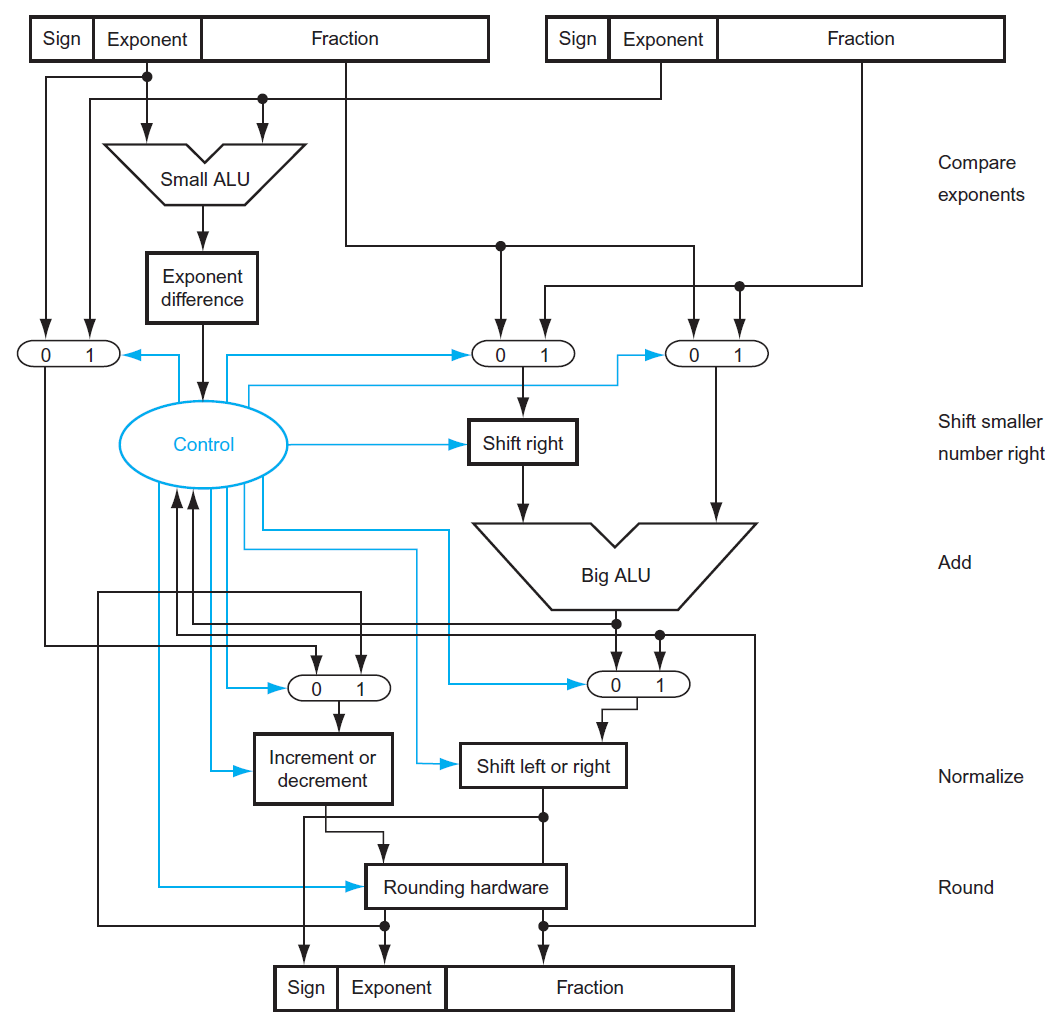
addition¶

multiplication¶

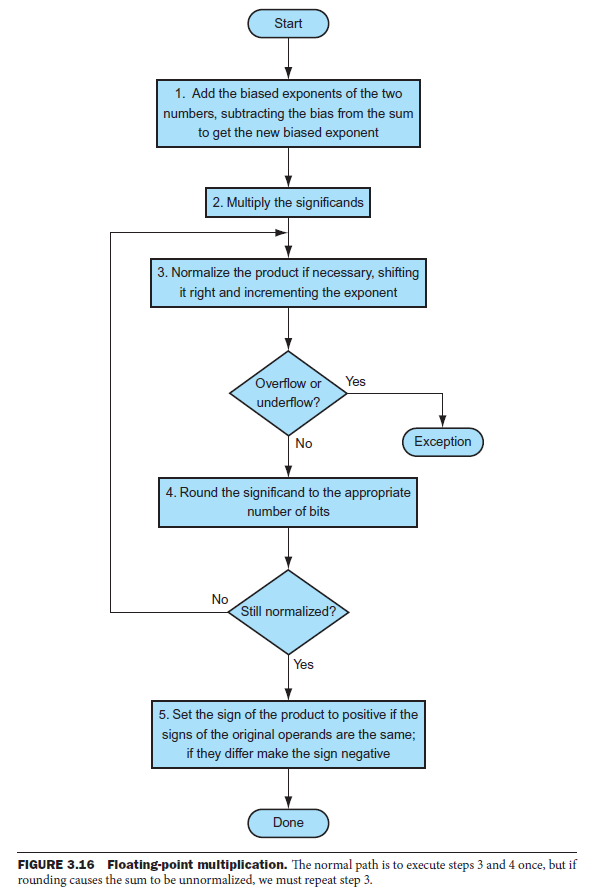
FP multiplier is FP adder but use multiplier for significands
instructions¶
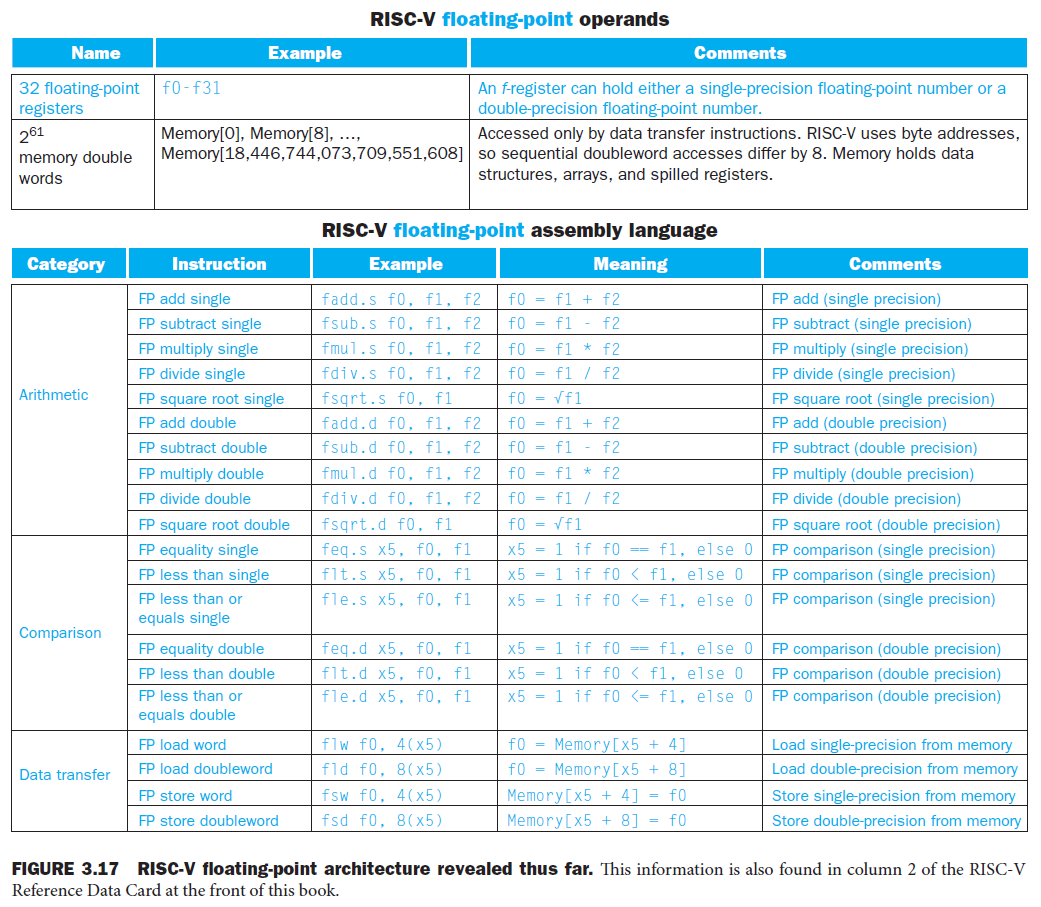
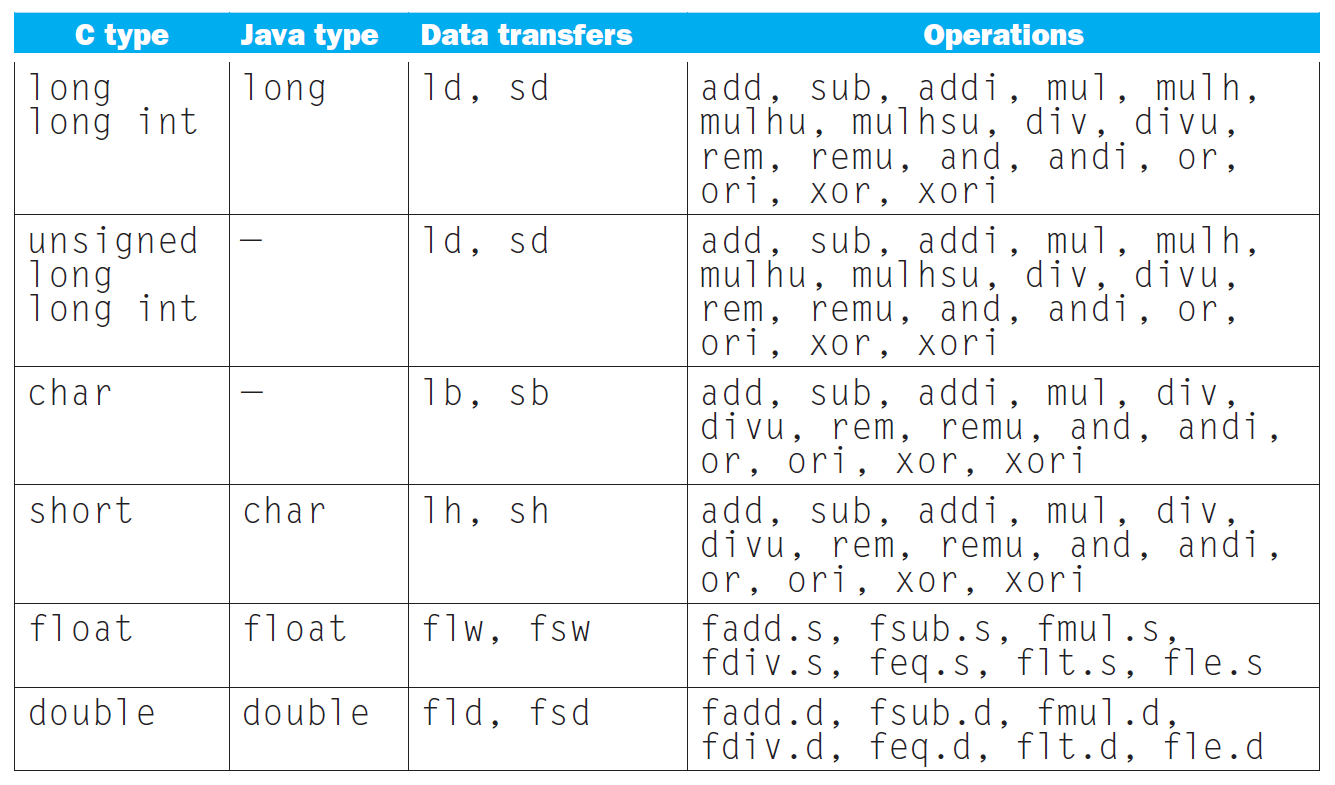
examples¶
escaping from barbaric yanks¶

flw f0, const5(x3) //f0 = 5
flw f1, const(x9) //f1 = 9
fdiv.s f0, f0, f1 //f0 = f0/f1 = 5/9
flw f1, const32(x3) //f1 = 32
fsub.s f10, f10, f1 //f10 = f10 - f1 = f10 - 32
fmul.s f10, f0, f10 //f10 = f0 x f10 = 5/9 x f10
jalr x0, 0(x1) //return
array multiplication¶


- \(a_{2,3}\) in 5x5 → 1x5+3 = 8th item (左到右,上到下)
- 64-bit → 要再 x8
slli 3

rounding¶
- extra bits of precision
- guard & round
- guard 存目標位數後 1st 位,round 存目標位數後 2nd 位,then round with 這兩位
- e.g. (round to 小數點後第二位) 1.5252 → 1.53 bc \(52\in [51,99]\)
- without these 2,則永遠只保留目標位數

- guard 存目標位數後 1st 位,round 存目標位數後 2nd 位,then round with 這兩位
- sticky
- guard & round bit 右邊有非 0 位數 → set to 1,append as 3rd bit
- 0.500000...000001 → 0.501
- guard & round
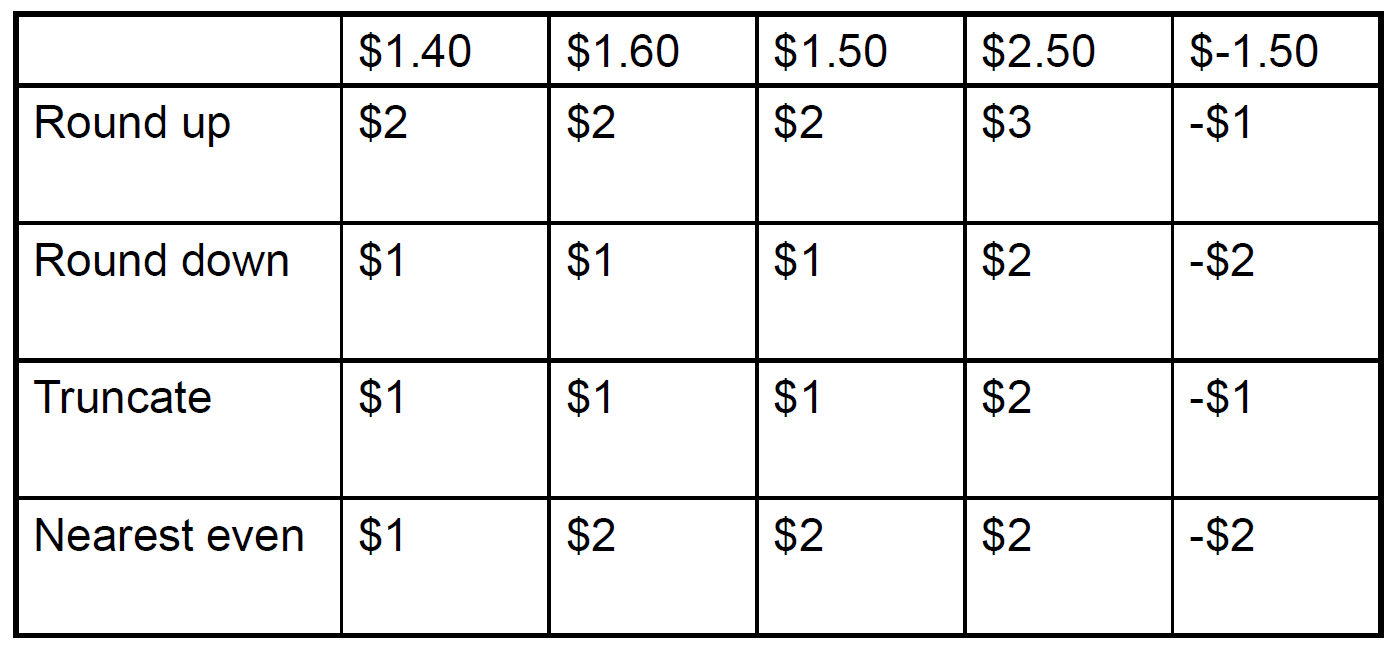
- nearest even
- tie (剛好一半) → round to even
- tie 時 round 完 last bit 絕對是 0
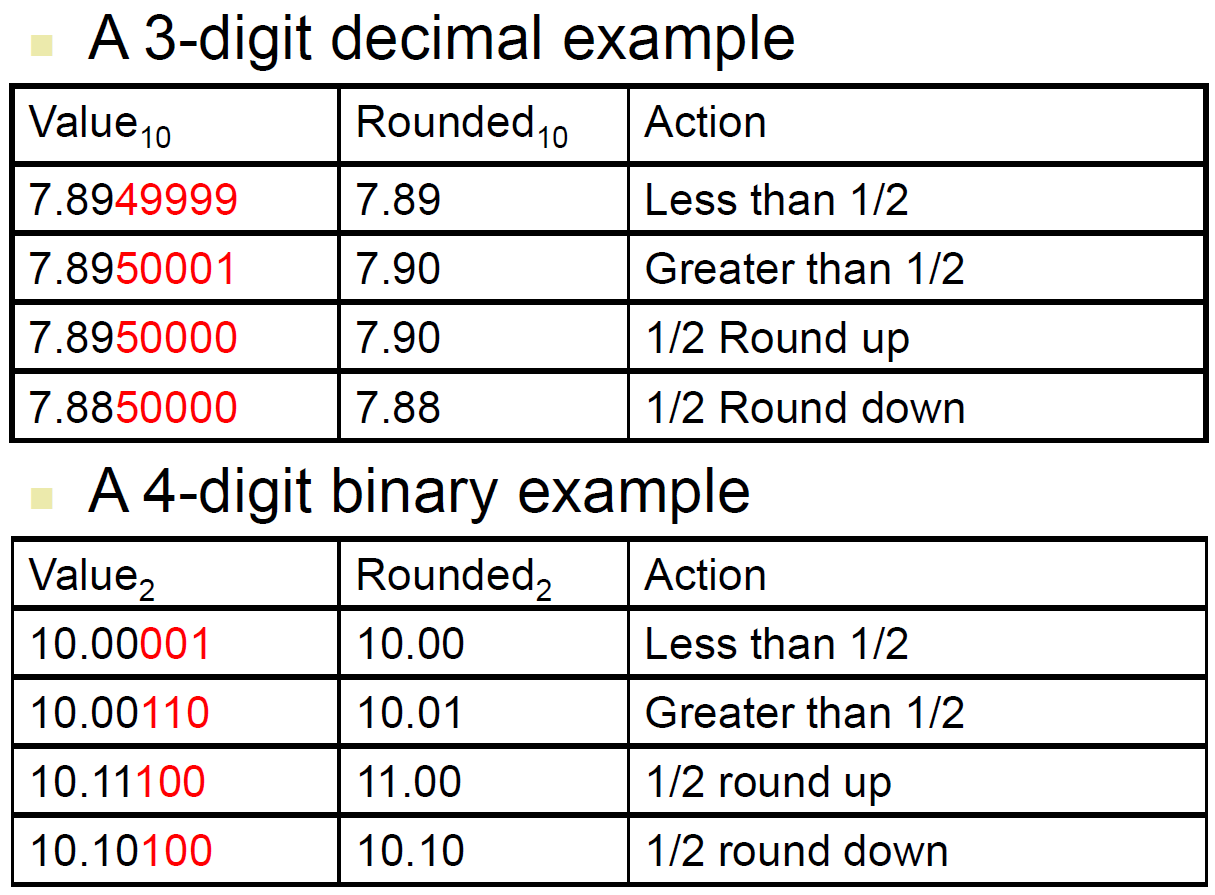
- nearest even
- e.g.



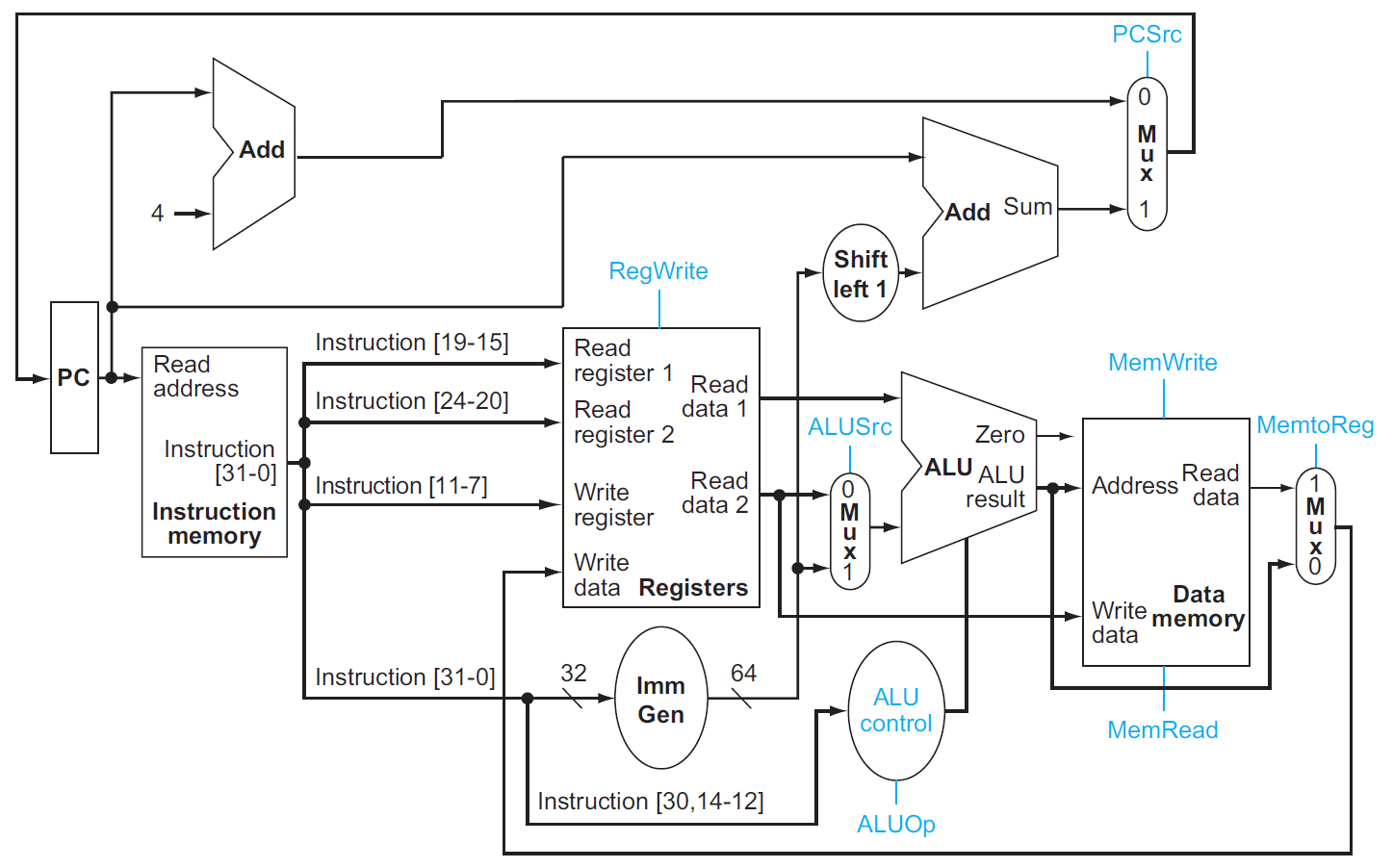
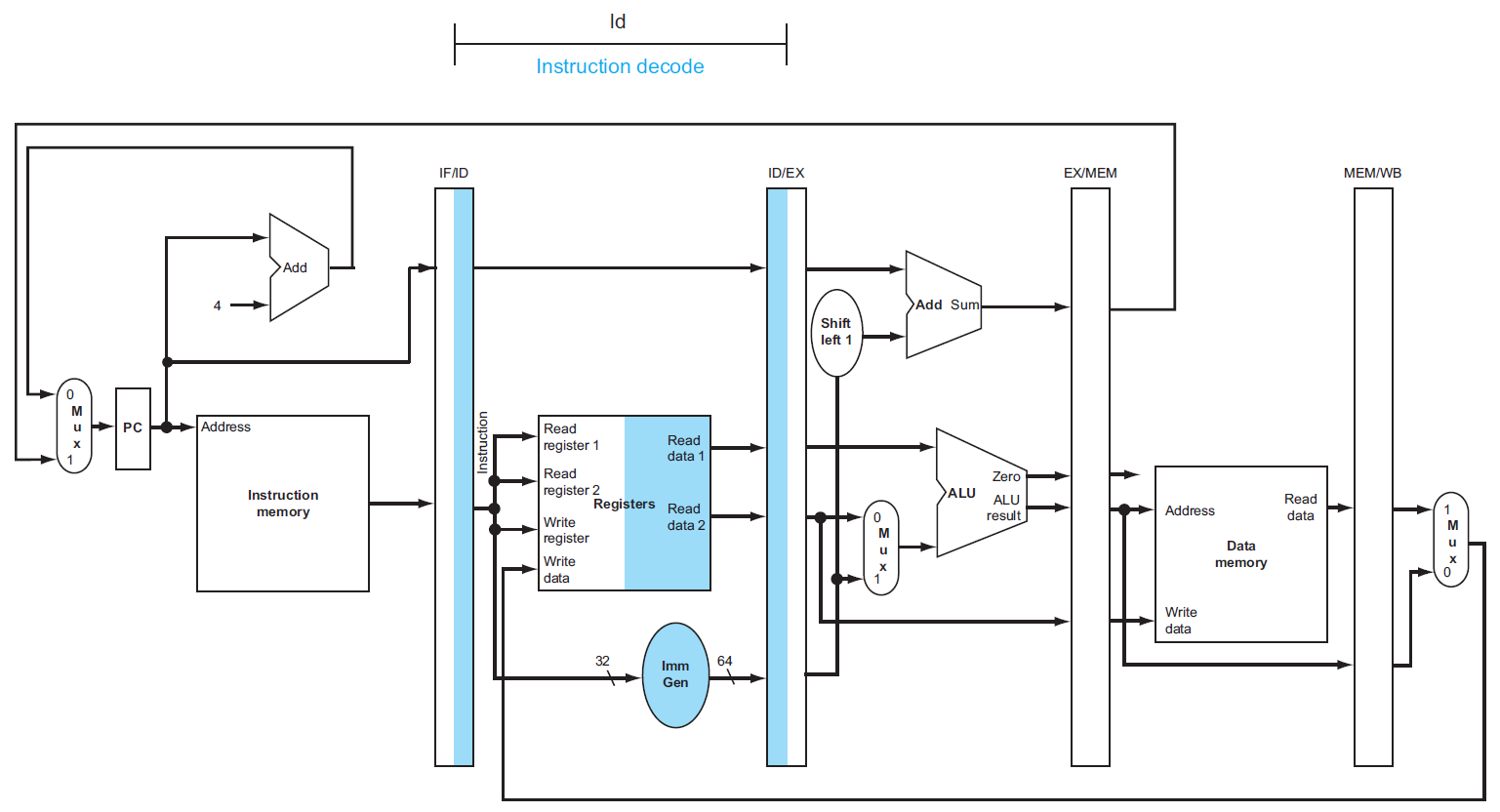
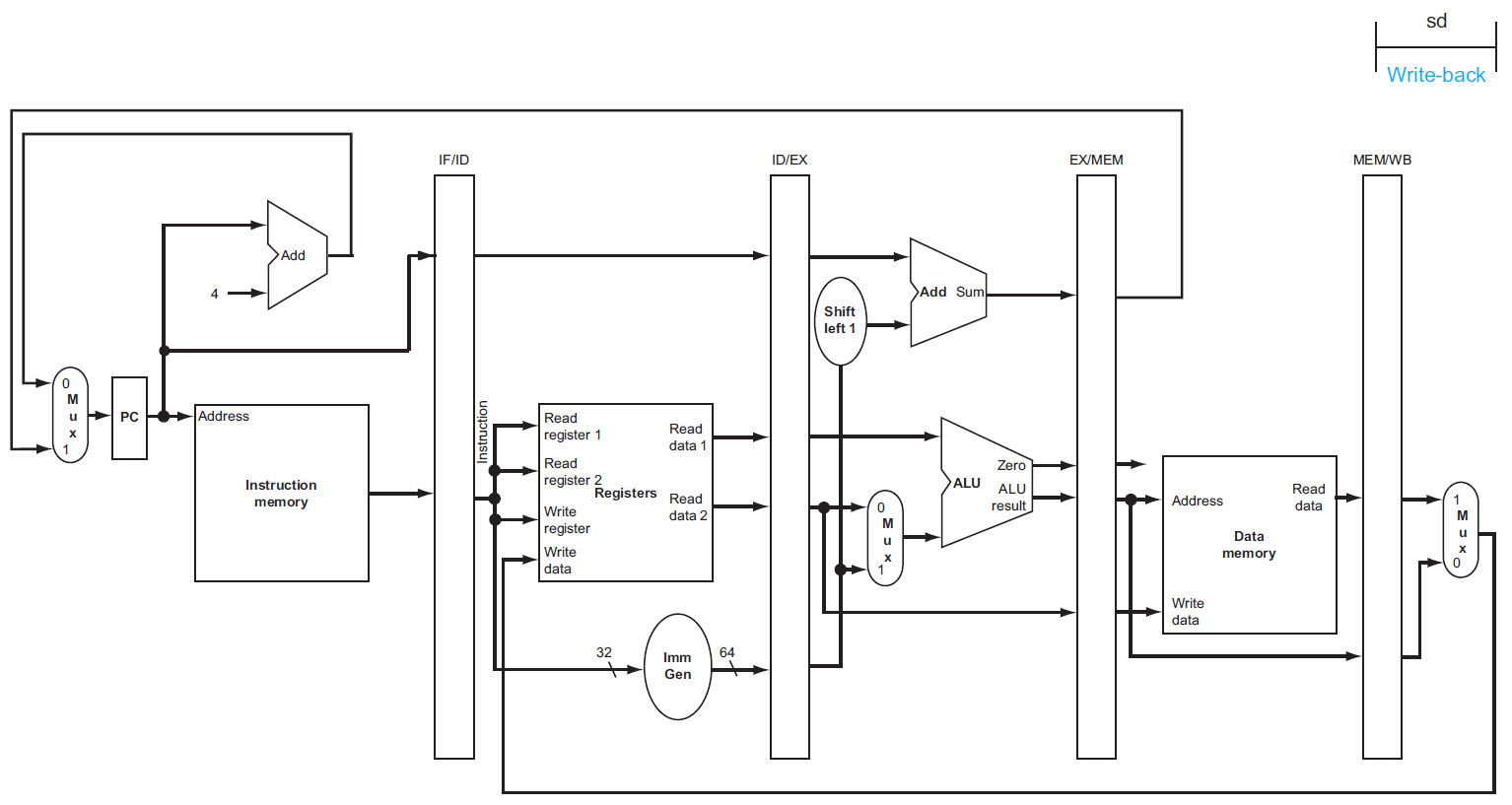
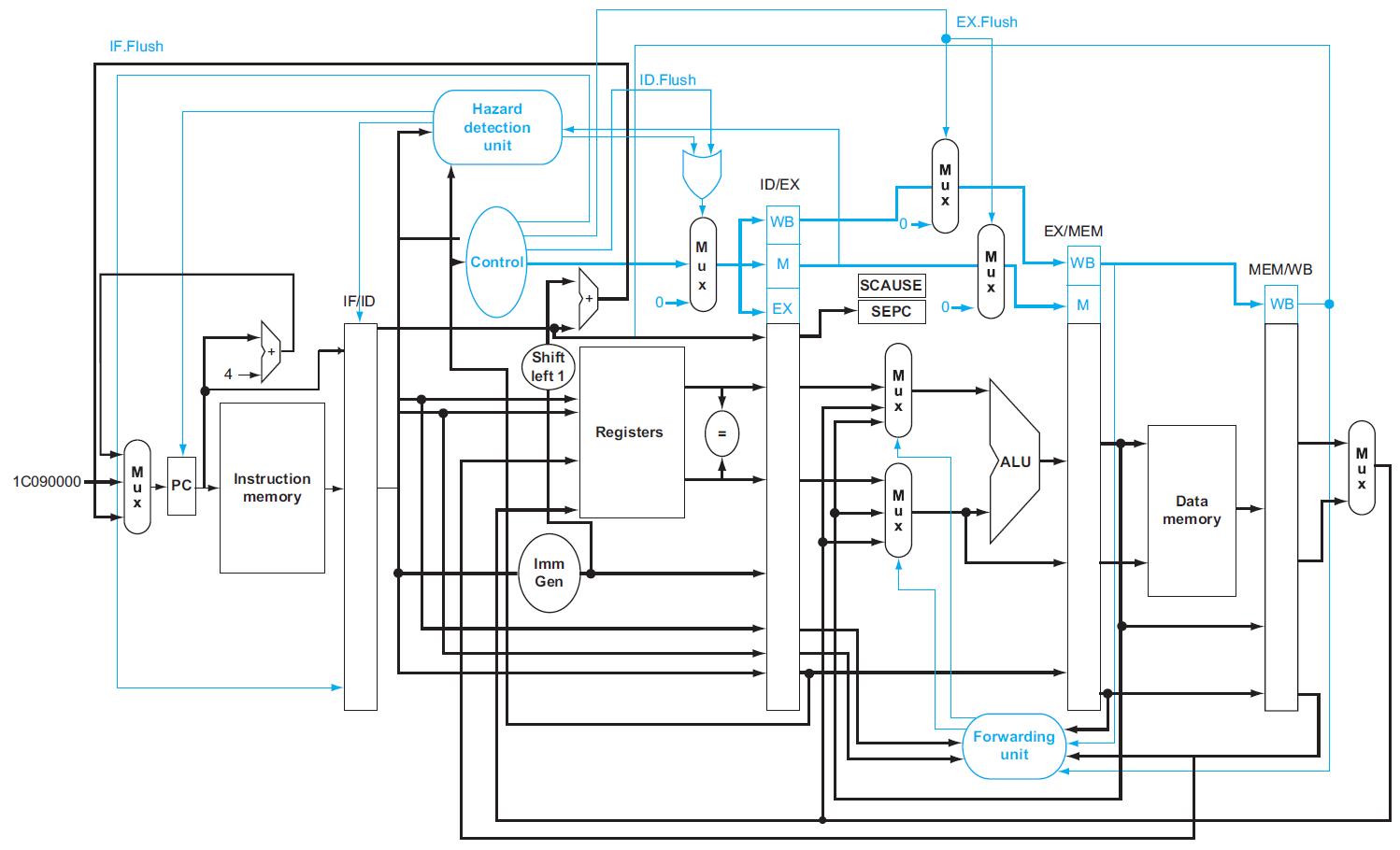
Ch4 Processor¶
CPU¶
- implementation of the RISC-V subset
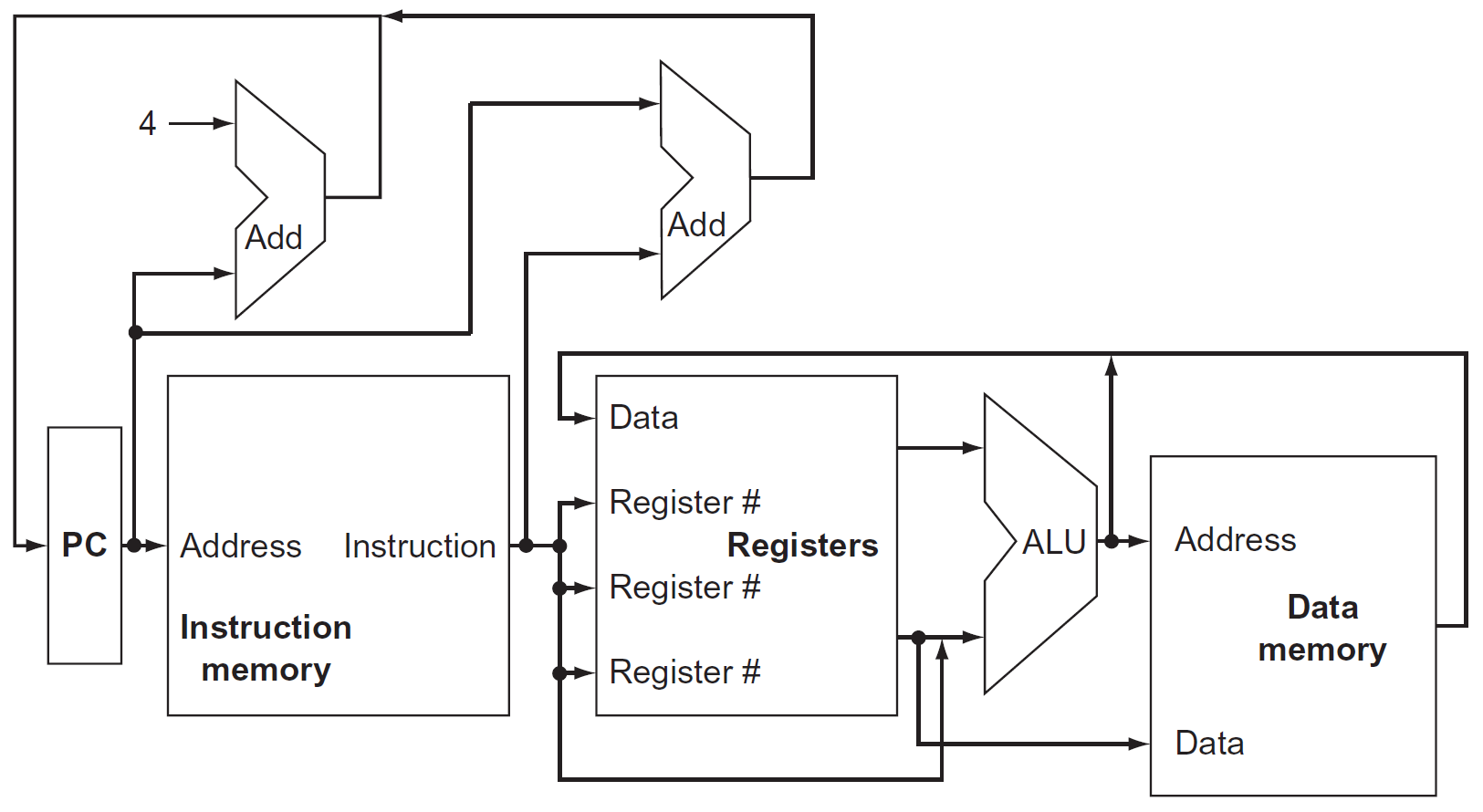
- with multiplexers & control lines
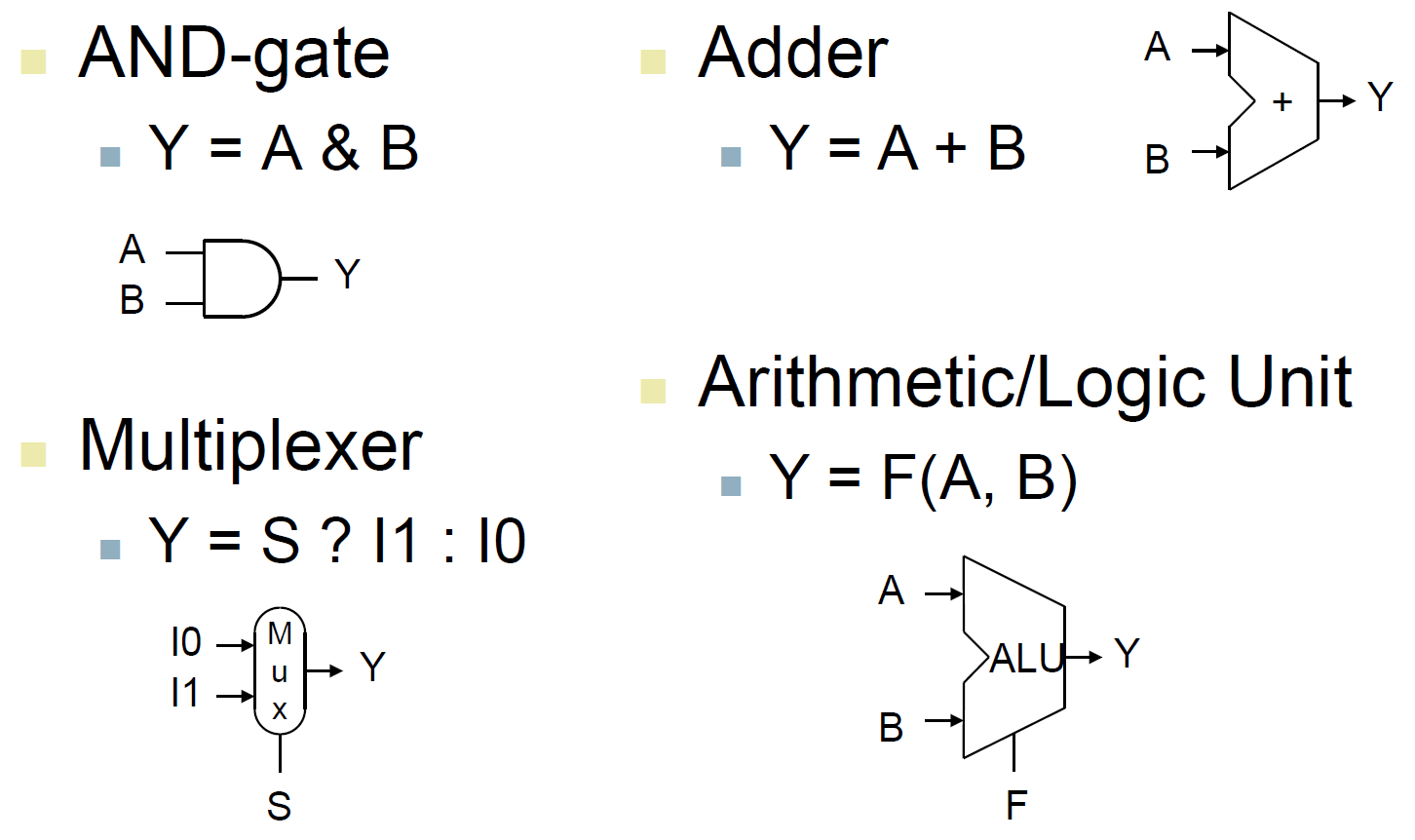
logic design¶
- 1 wire 1 bit
- multiple wire → bus
- multiplexer (mux)
- 多個 input,選擇一個 output
building a datapath¶
fetching instruction¶
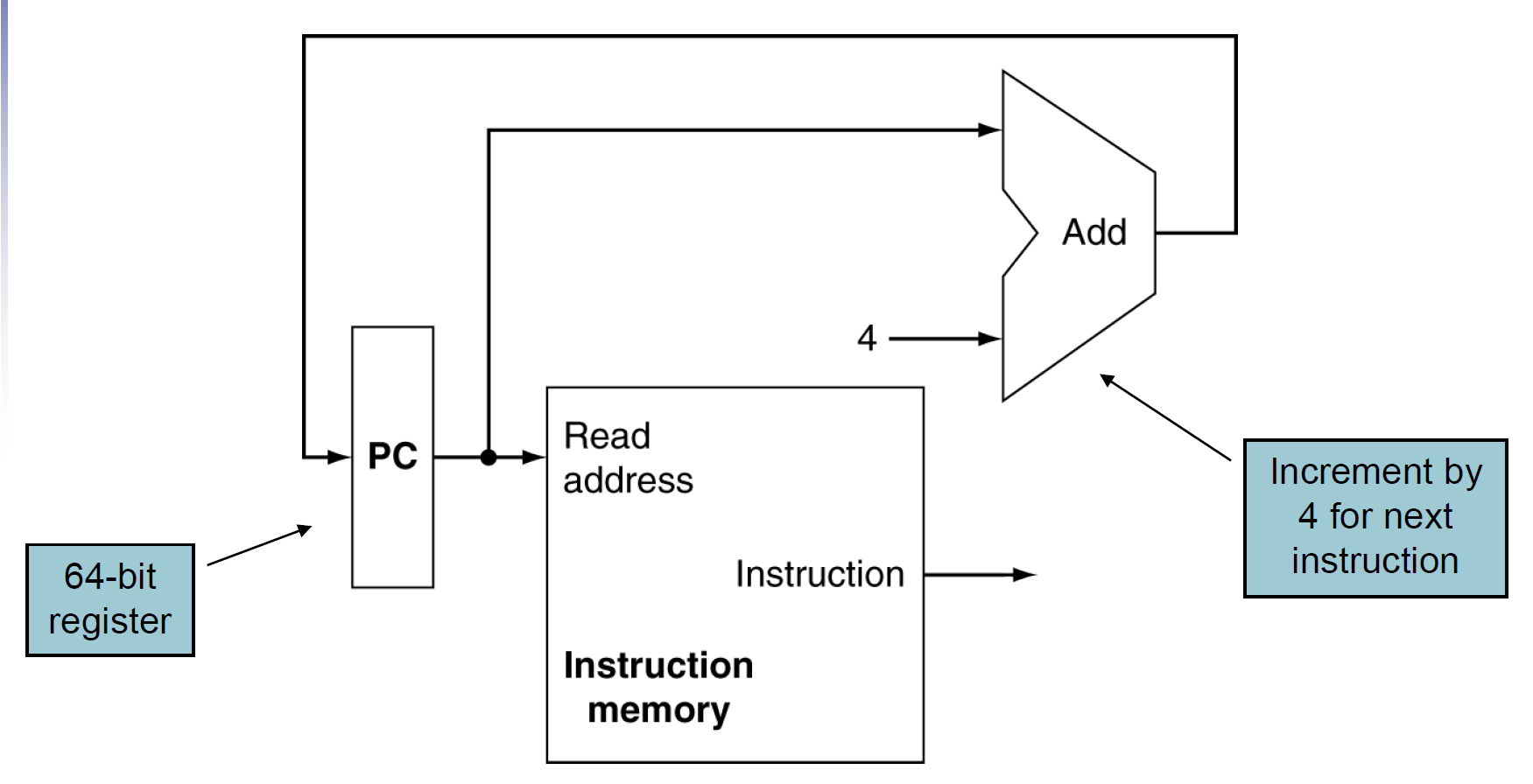
- 用寫死做 Add 的 ALU,每次 PC +4
- instruction memory 用 combinational logic
R-type instructions¶
- arithmetic-logical instructions
- don't use sign extender (P4.3.3)
- read 2 registers → perform an ALU operation (arithmetic or logical operation) → write result to register
load/store¶
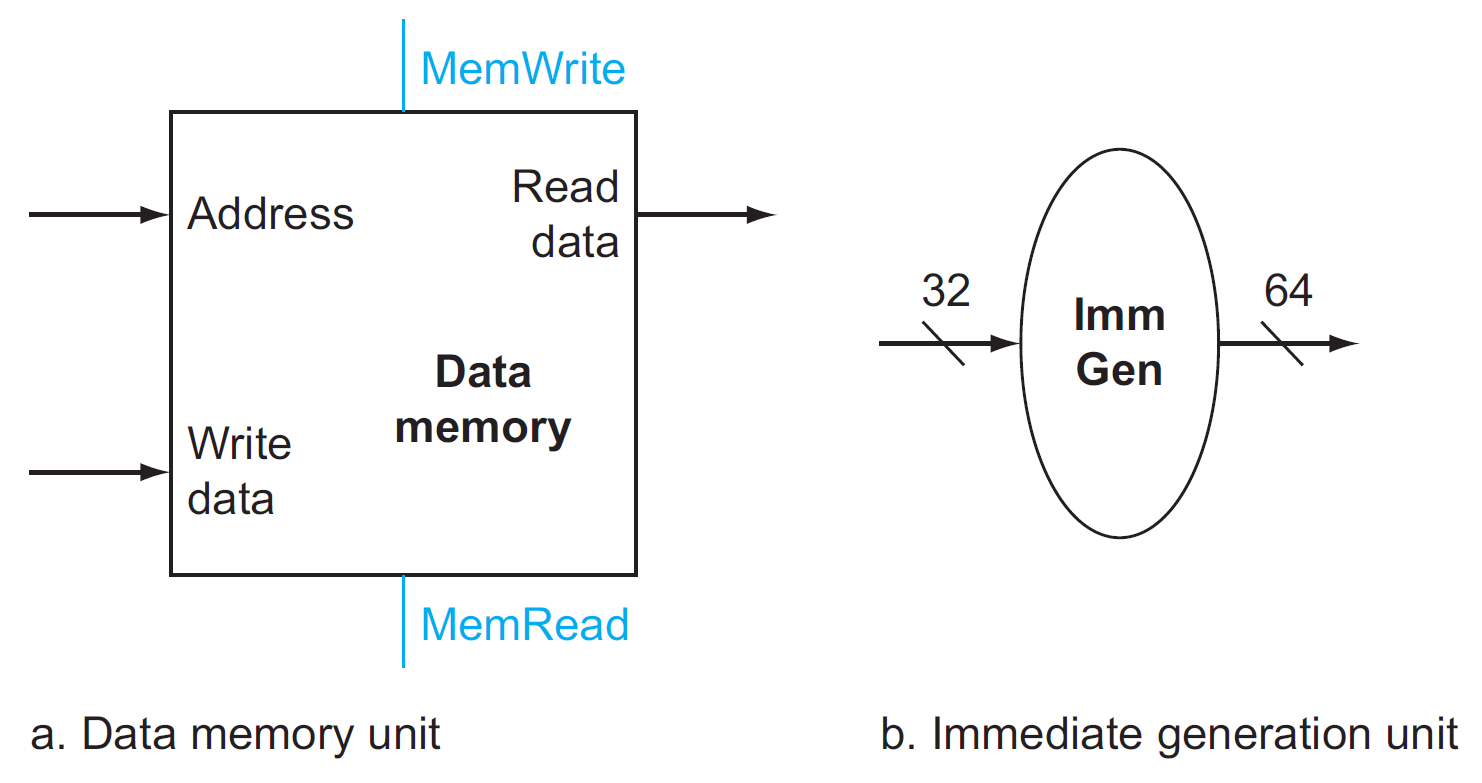
- only load & store use data memory (P4.3.1)
- immediate generation: convert 成 ALU 所需的格式
- 32-bit instruction as input
- selects a 12-bit field for load, store, and branch if equal that is sign-extended into a 64-bit result appearing on the output (?)
branch instructions (beq)¶
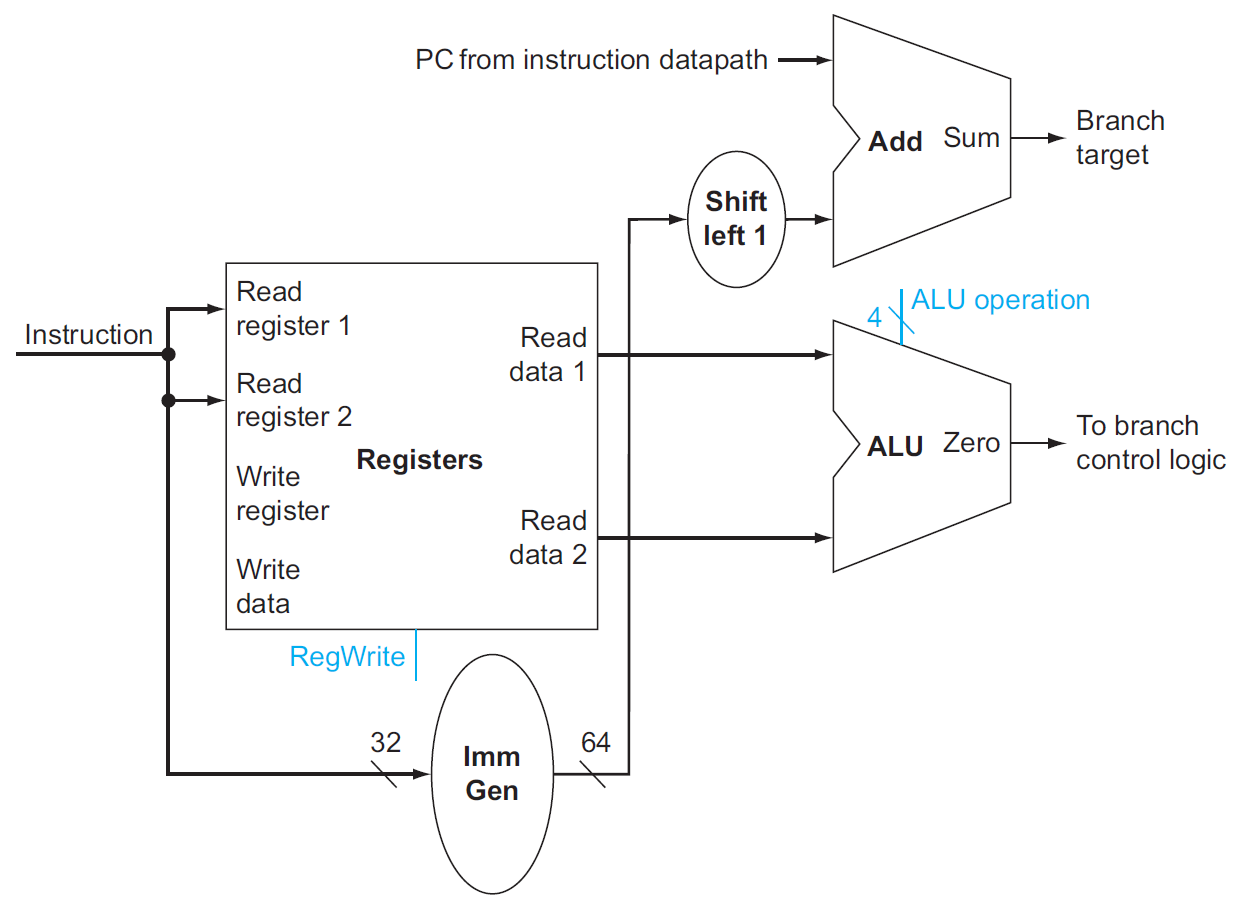
- shift left 是加 0 到 sign-extended offset field 的後面,丟掉 sign bit
- 之前 x2 的部分
- branch target = PC + imm slli 1
- 用 ALU 做 rs1-rs2,若為 0 則 PC = branch target,otherwise PC = PC+4
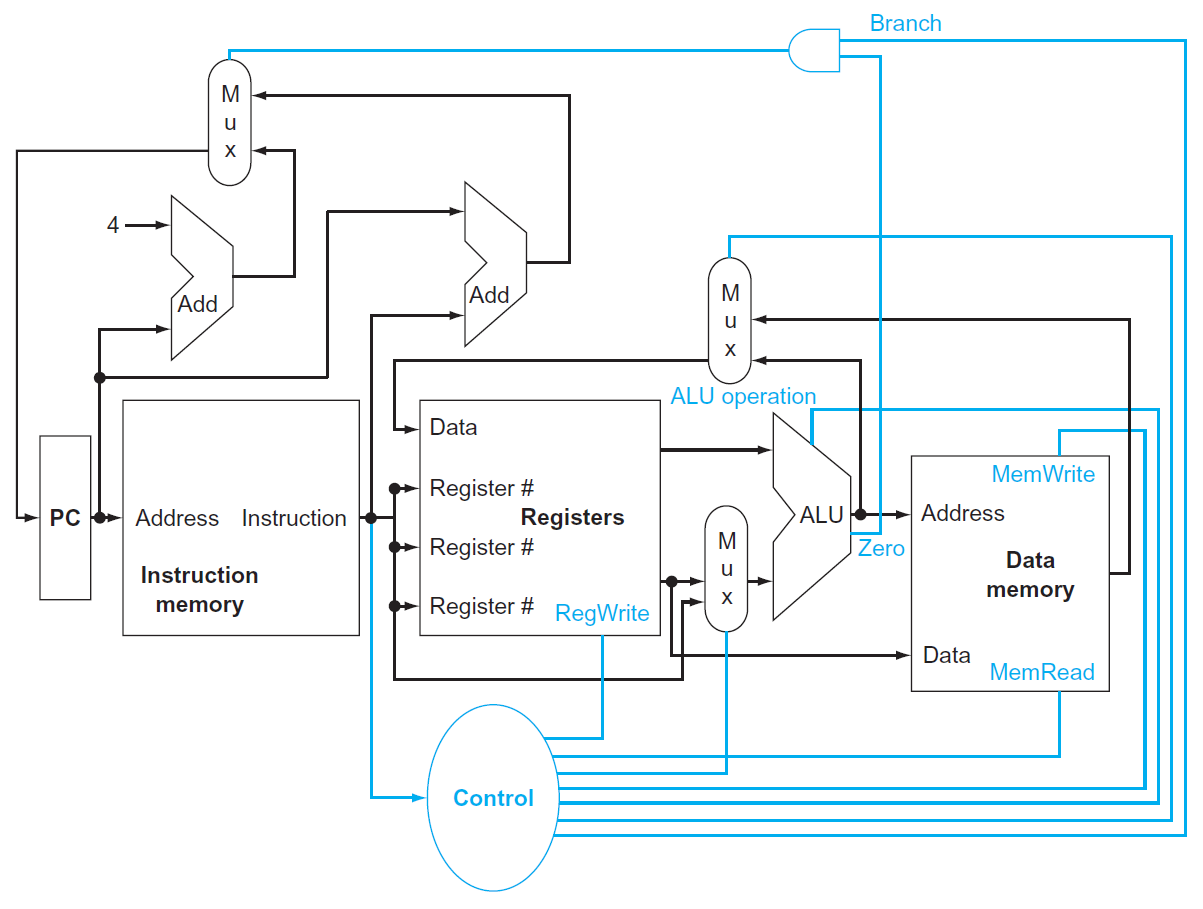
合起來¶
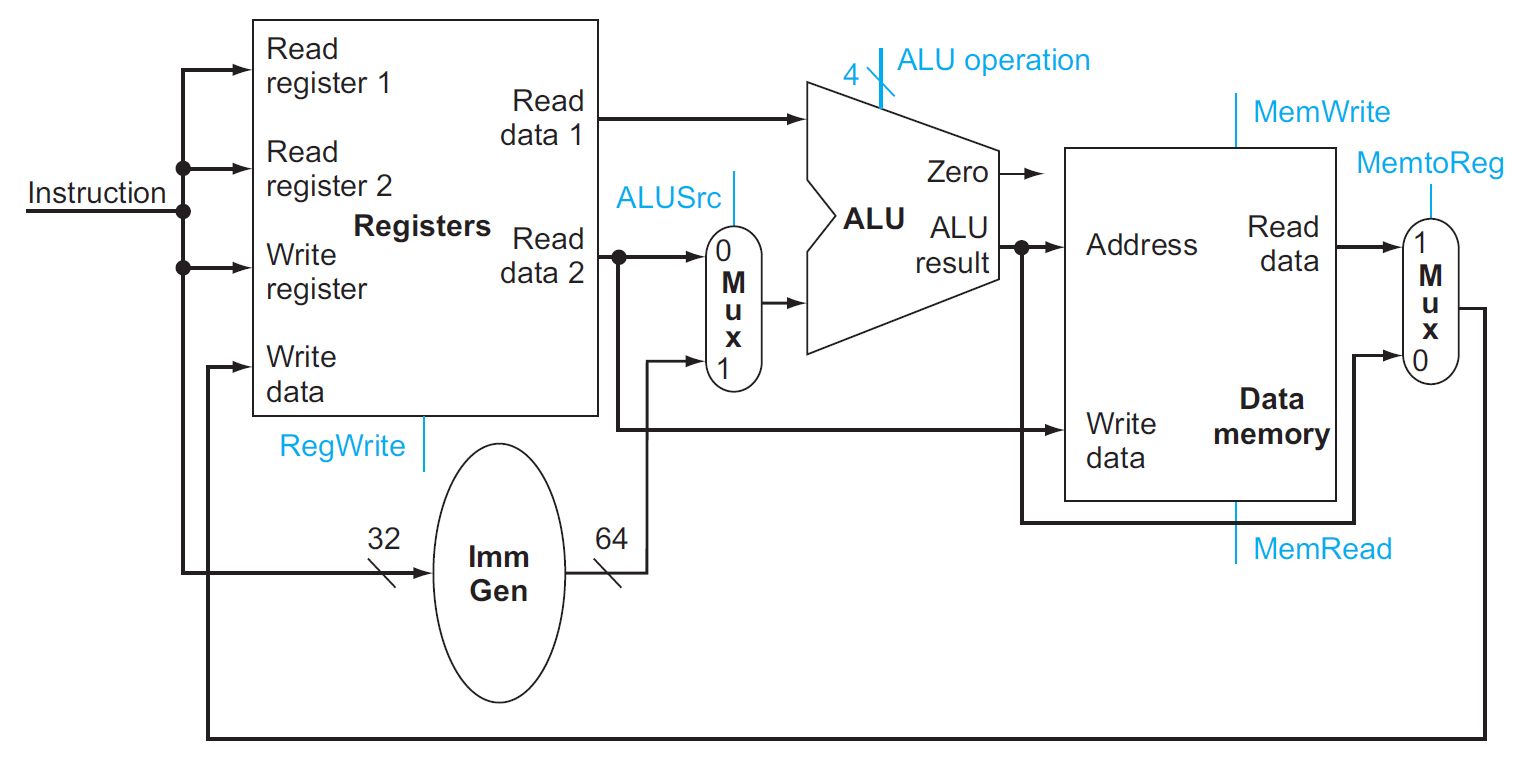
- 加上 mux 來連接&控制不同 instruction class
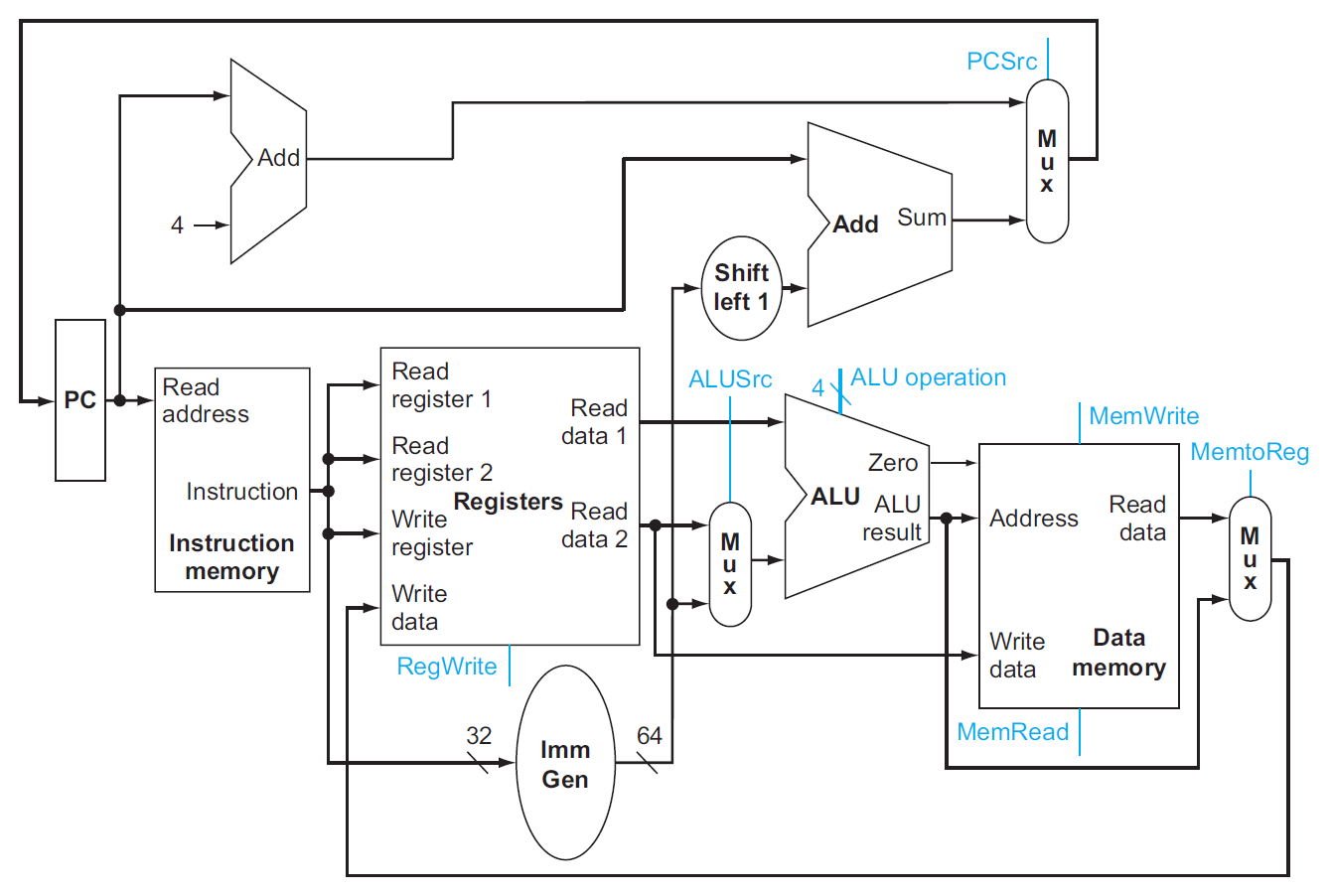
single-cycle implementation¶
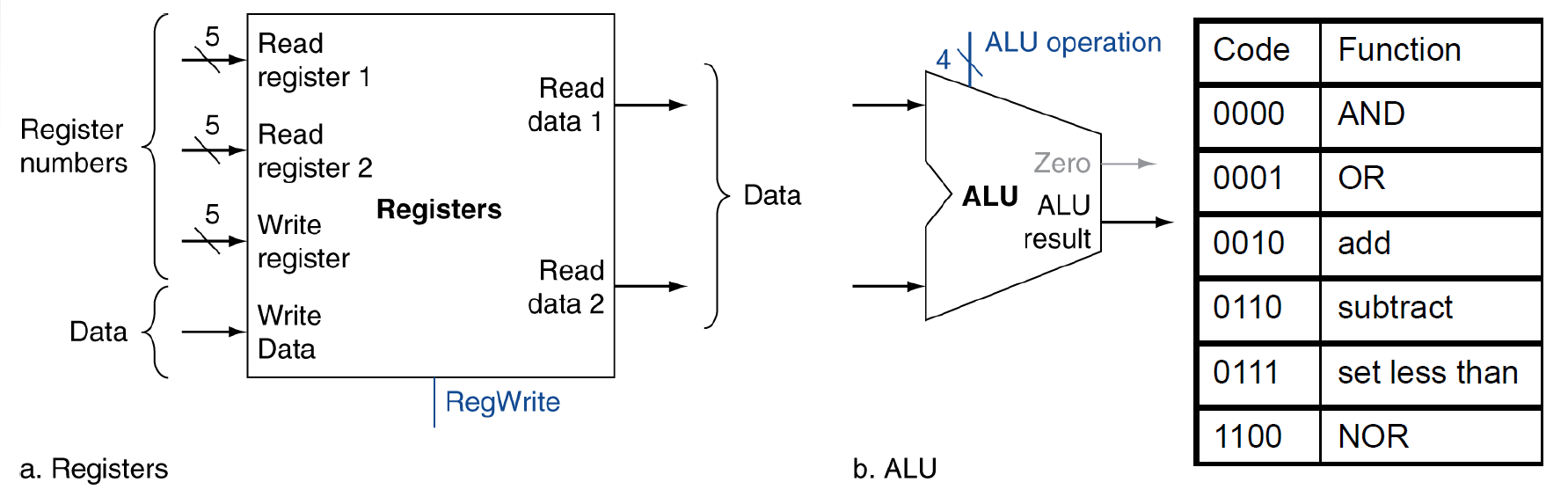
ALU¶
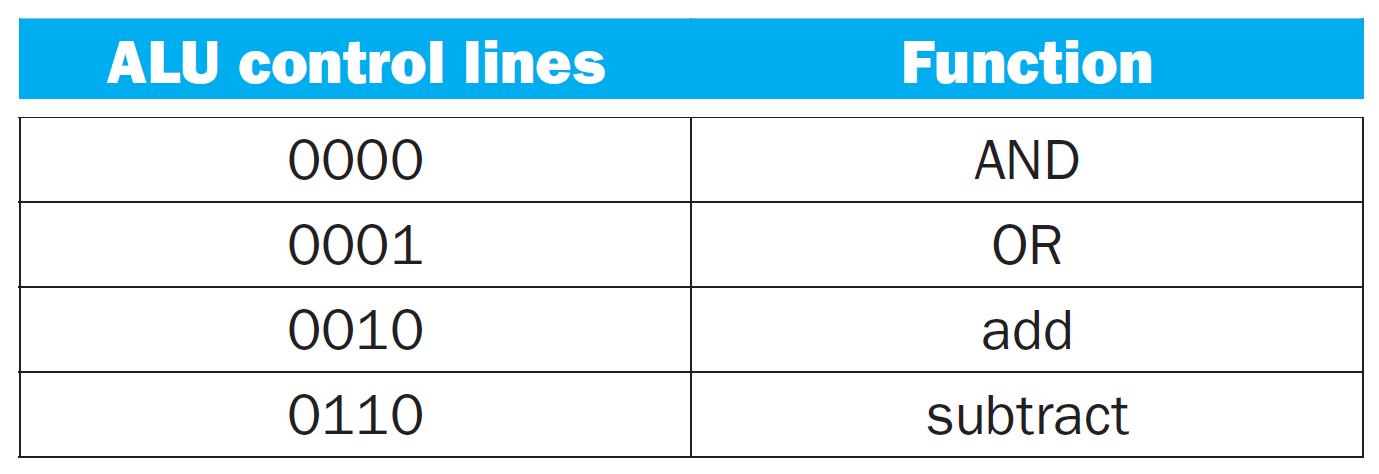
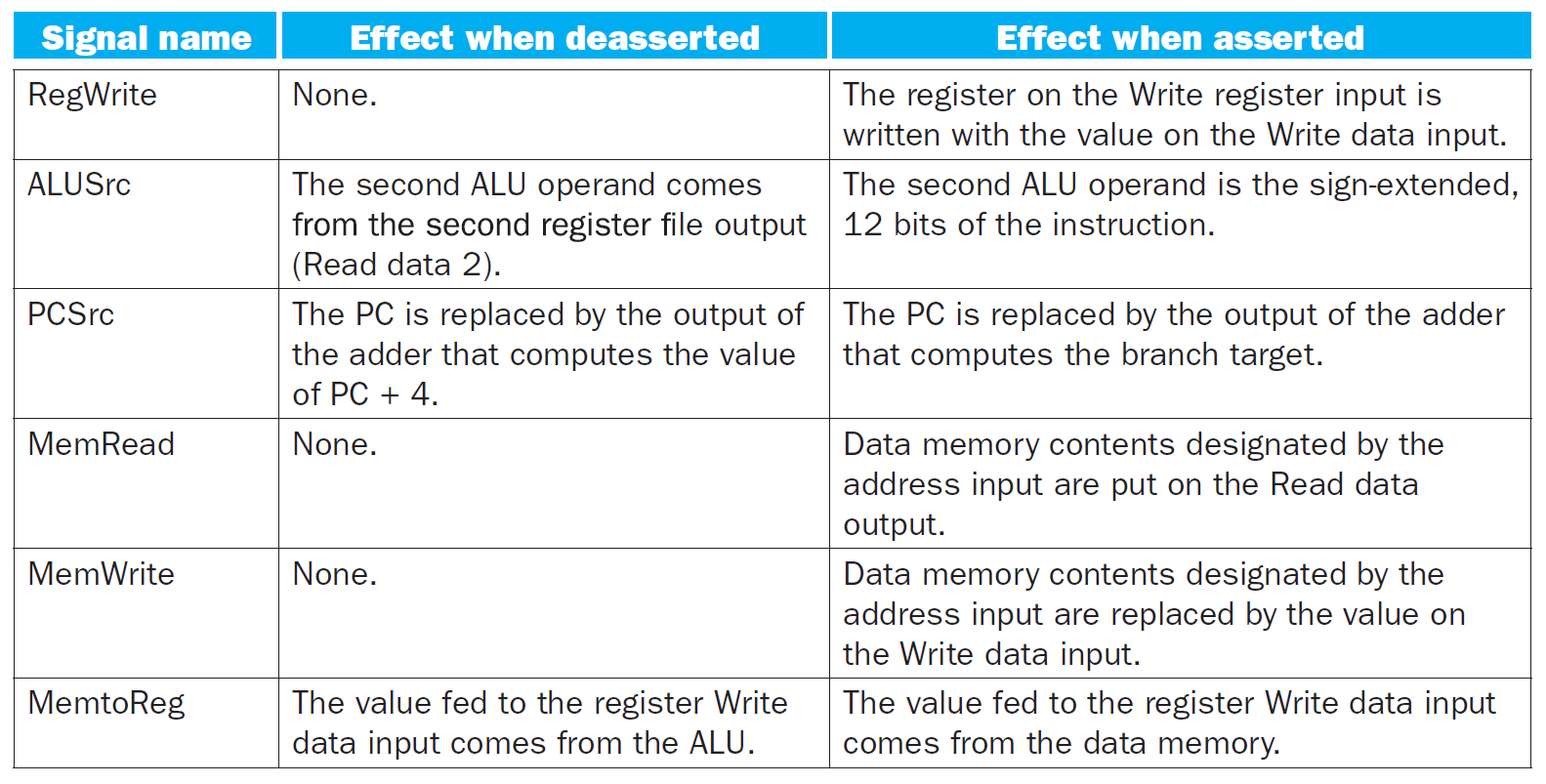
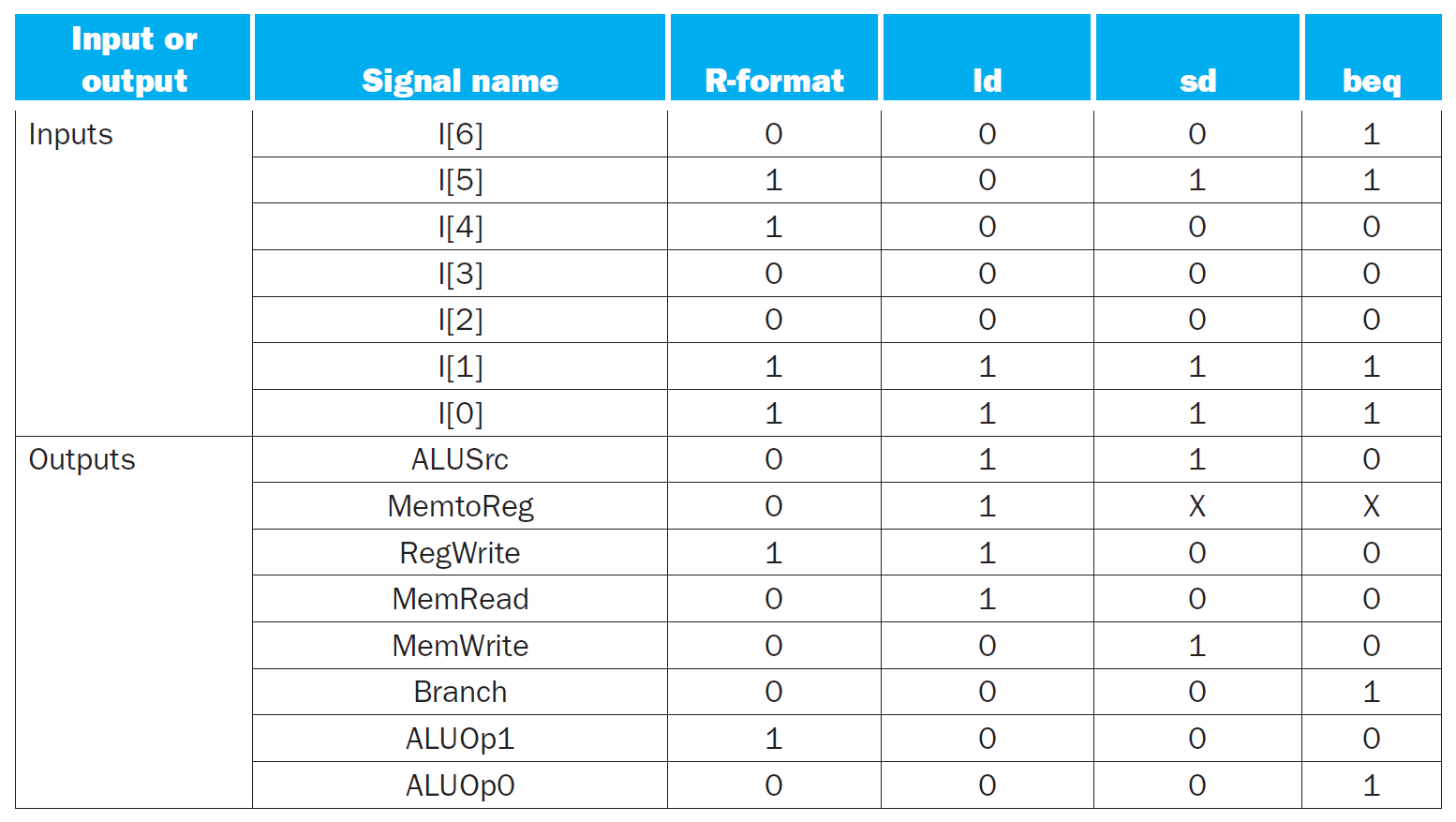
main control unit¶
- truth table
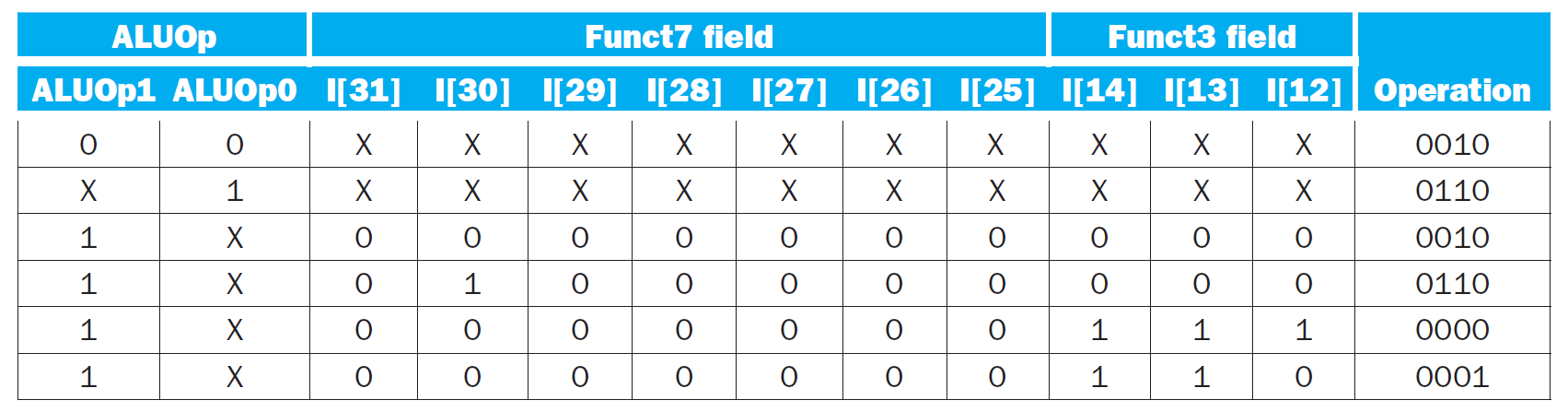
- 愈多 don't care 愈好
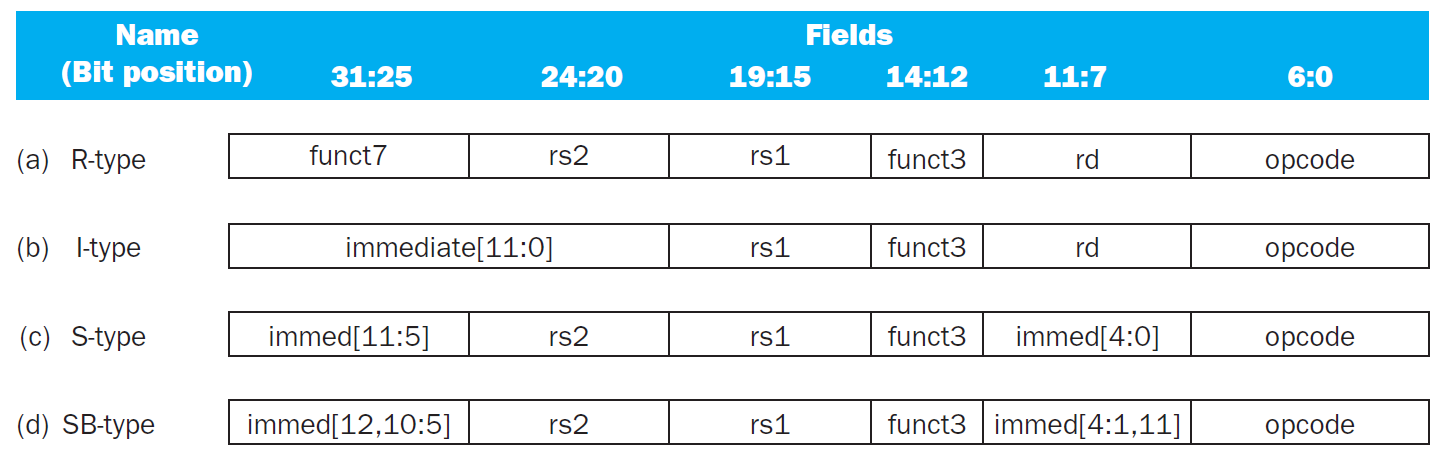
- rs1 = read register 1
- rs2 = read register 2
- rd = write register
- control signals
operation of datapath¶
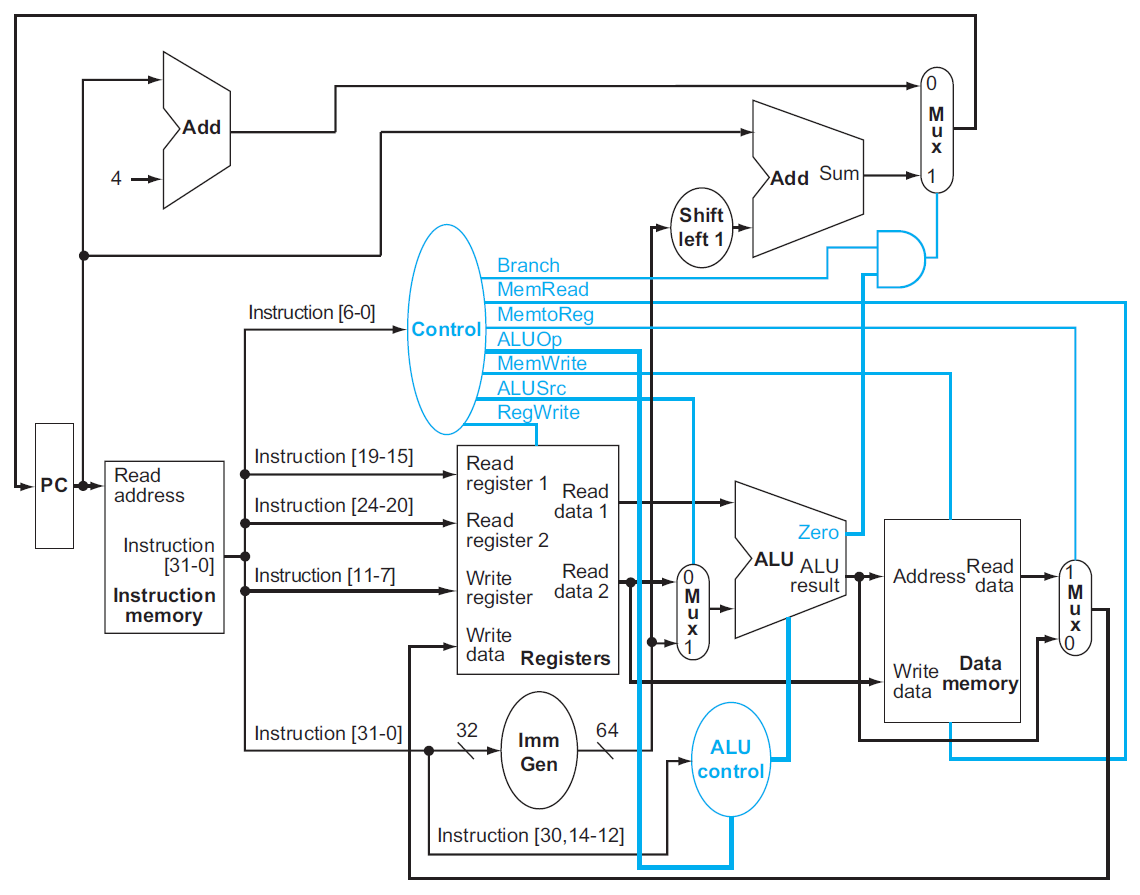
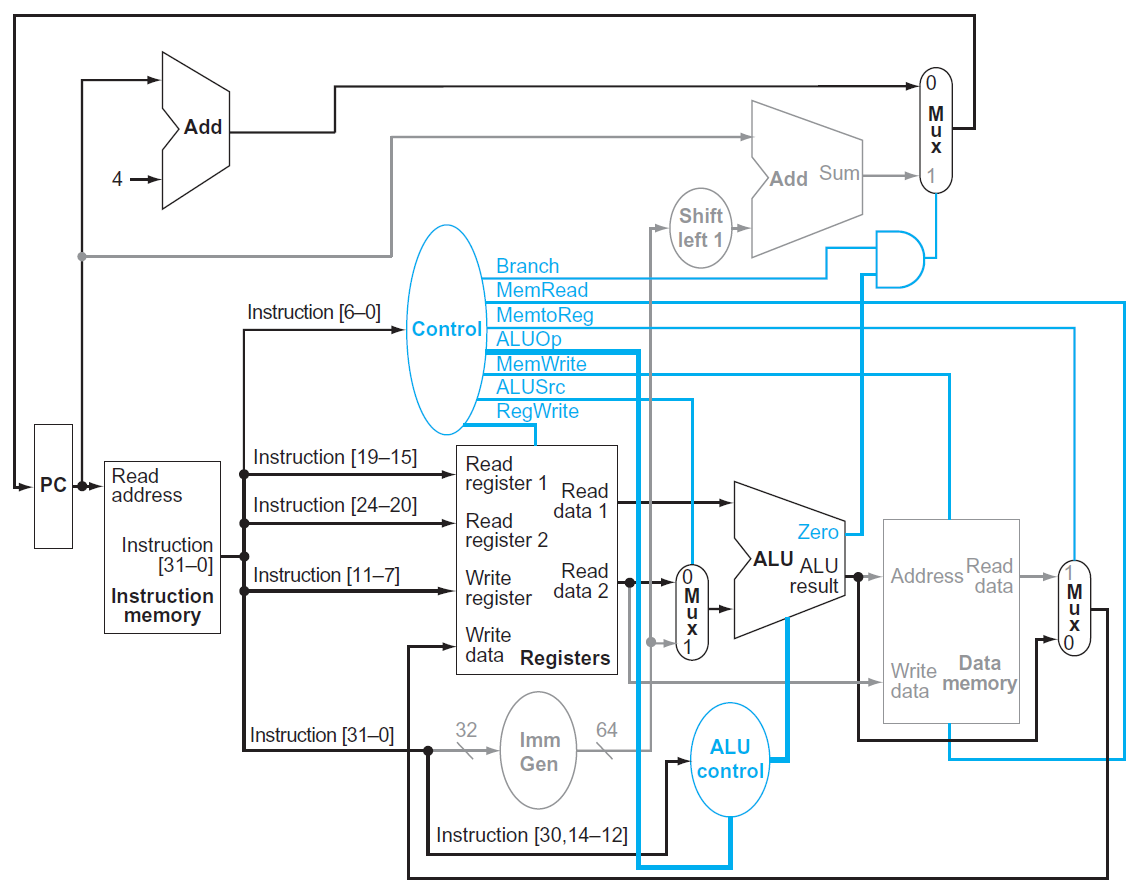
- 加上 control unit,input 是 7-bit opcode,output 控制各種東西
- e.g.
- add
- read address && pc+=4
- instruction decode
- read register 等等
- instruction execution
- ALU
- write data back (to destination register)
- R-type 不用處理到 data memory
- load
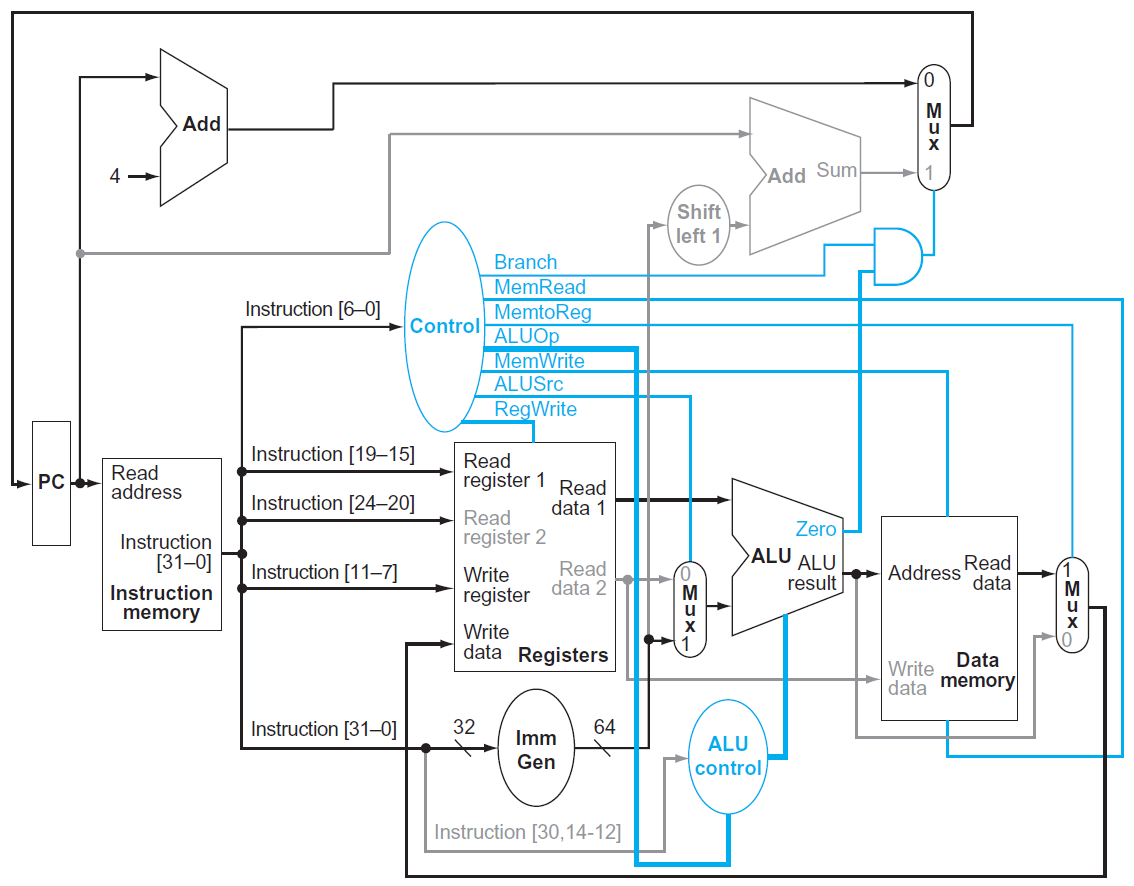
- ALU 算 sum of register 1 & offset → address of data memory
- data from the memory unity write into register file
- beq
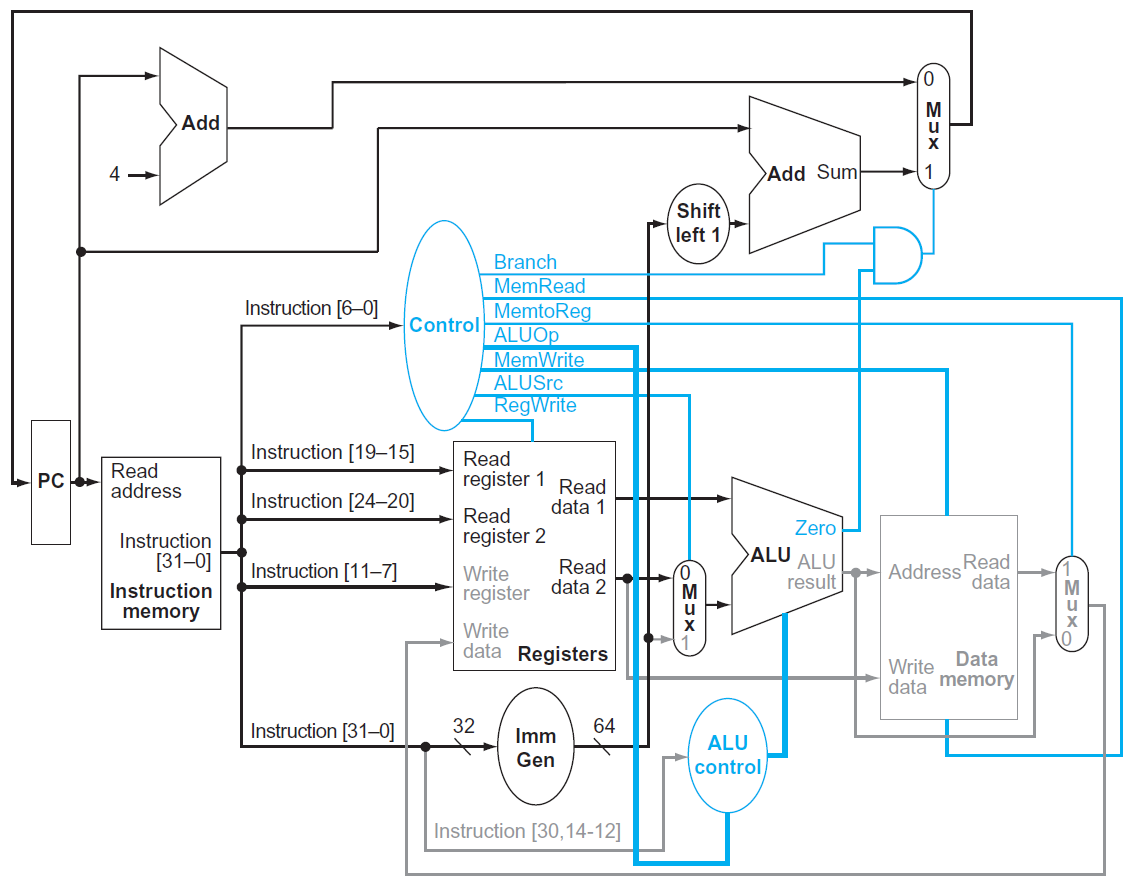
- imm gen 找 offset
- offset slli 1
- imm slli 1 + pc → branch target
- ALU 做 rs1-rs2
- = 0 → PC = branch target
- != 0 → PC = PC+4
- imm gen 找 offset
- add
finalizing control¶
performance issues¶
- clock period determined by worst-case delay (longest path)
- load instruction 最慢
- instruction memory → register file → ALU → data memory register file,5 個 stage 都要跑一遍
- but load instruction 又很常用
- instruction memory → register file → ALU → data memory register file,5 個 stage 都要跑一遍
- solution: pipelining
- load instruction 最慢
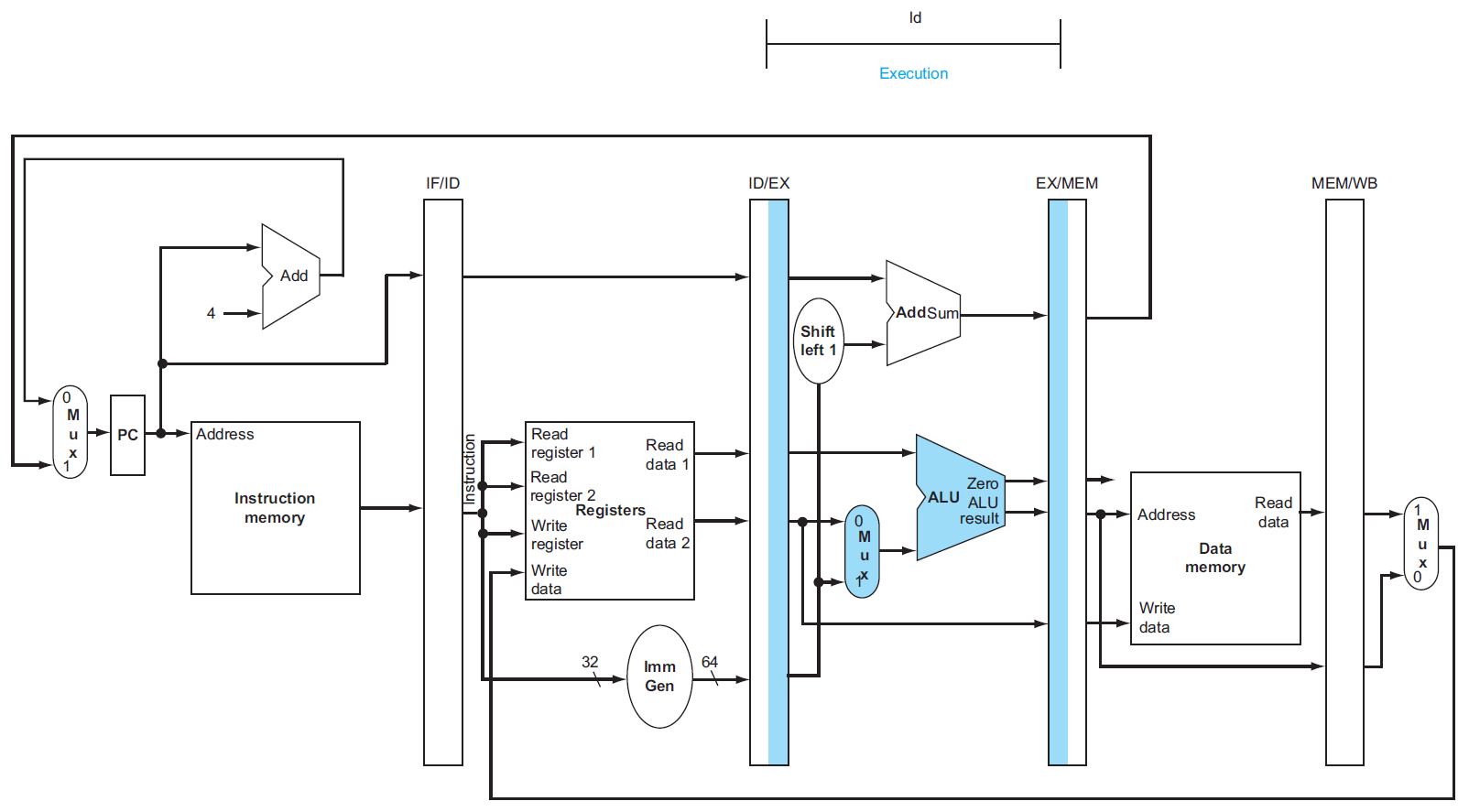
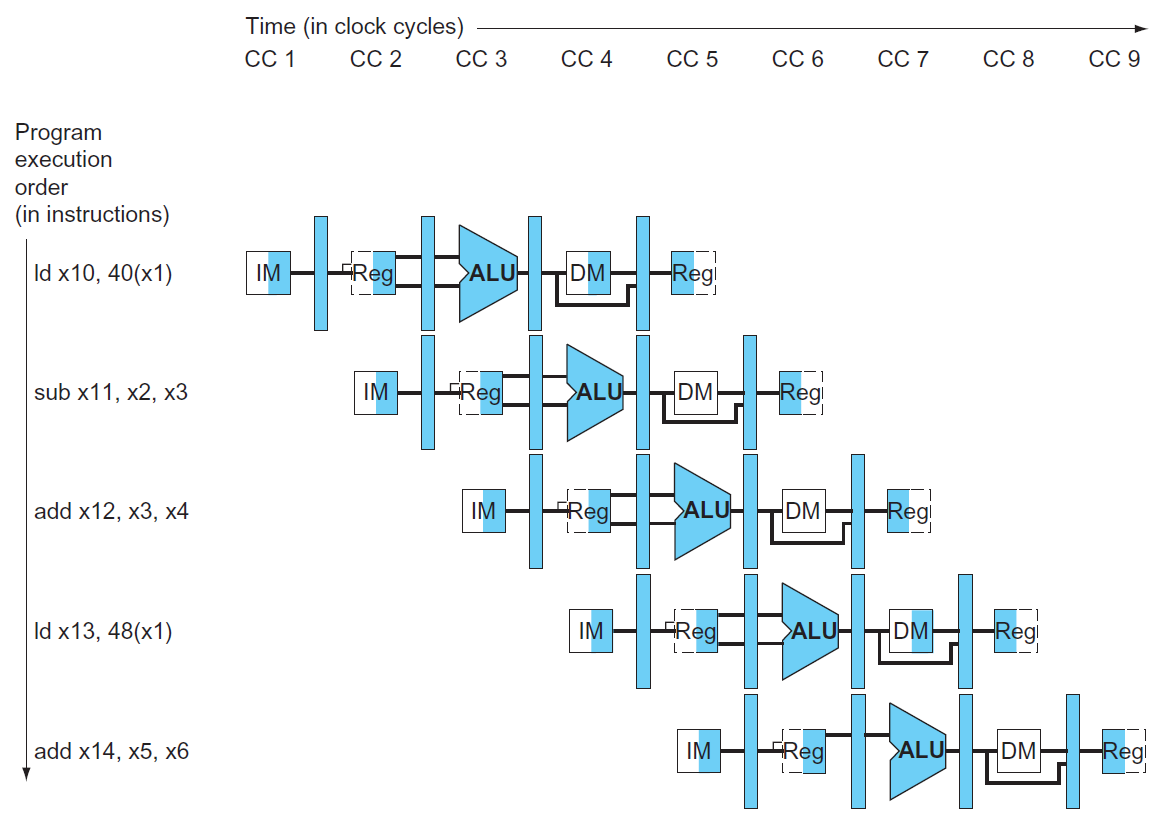
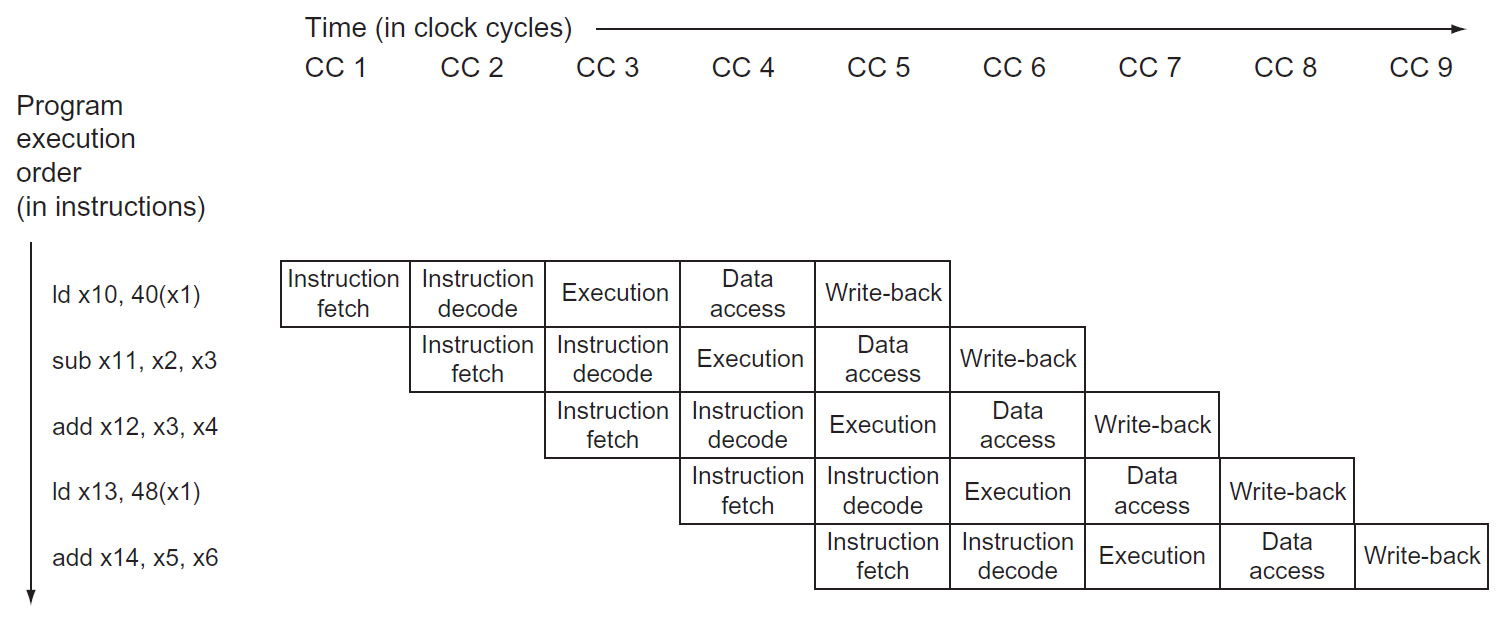
pipelining¶
RISC-V 5-stage pipeline¶
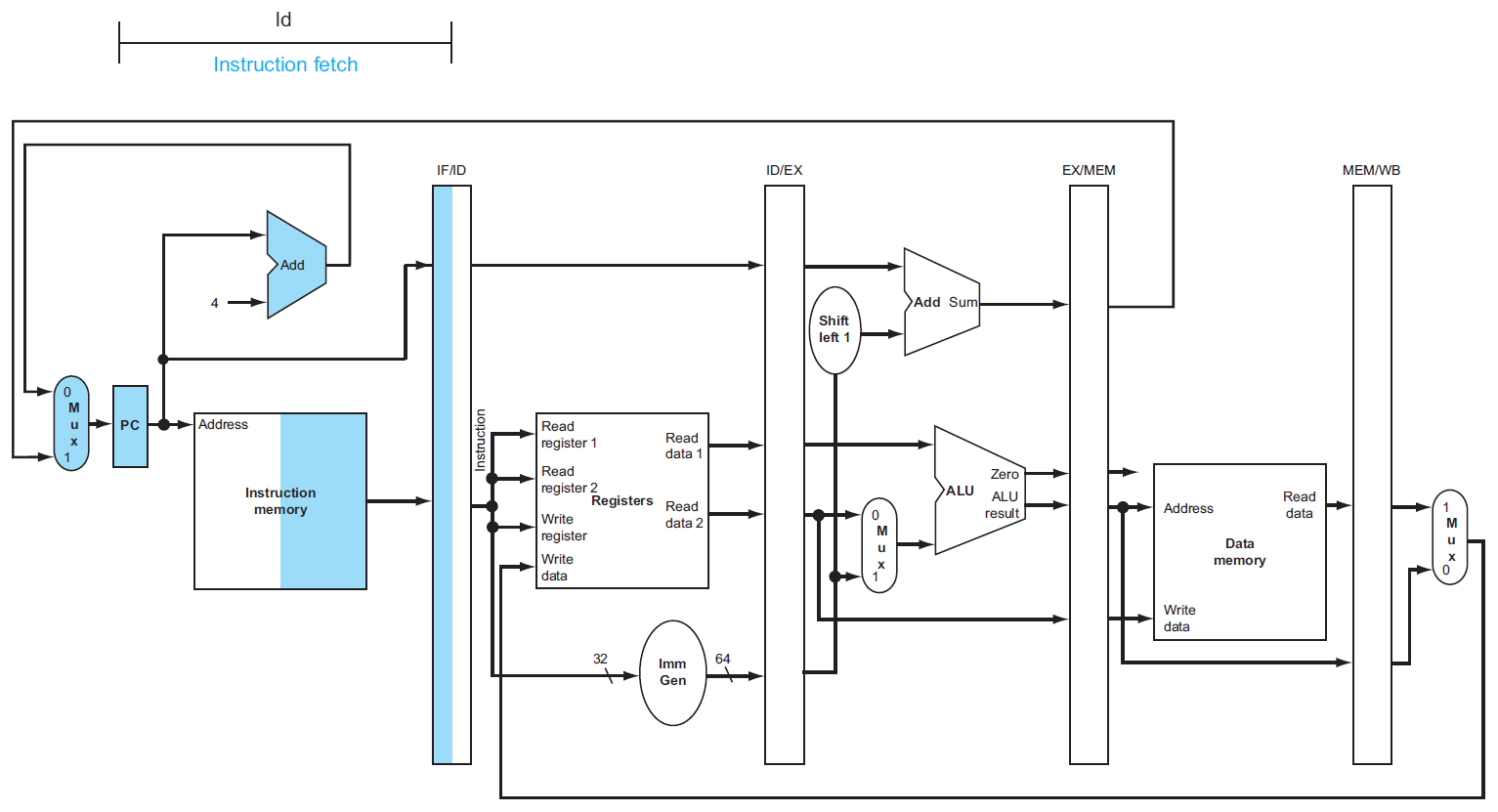
- IF = instruction fetch
- ID = instruction decode & register read
- EX = execute operation OR calculate address
- MEM = access memory operand
- WB = write result back to register
stage utilization of each type
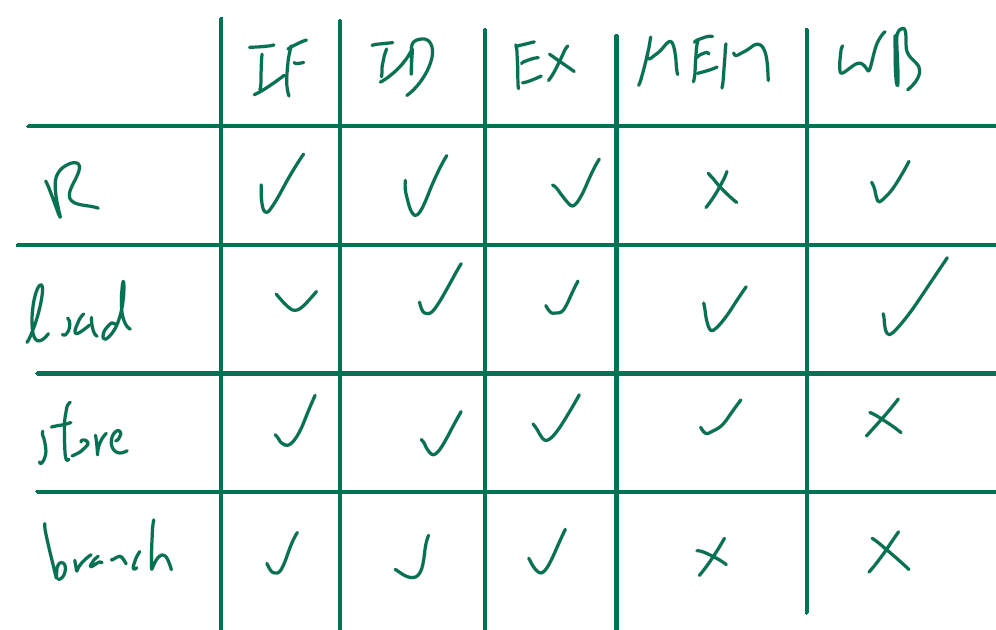
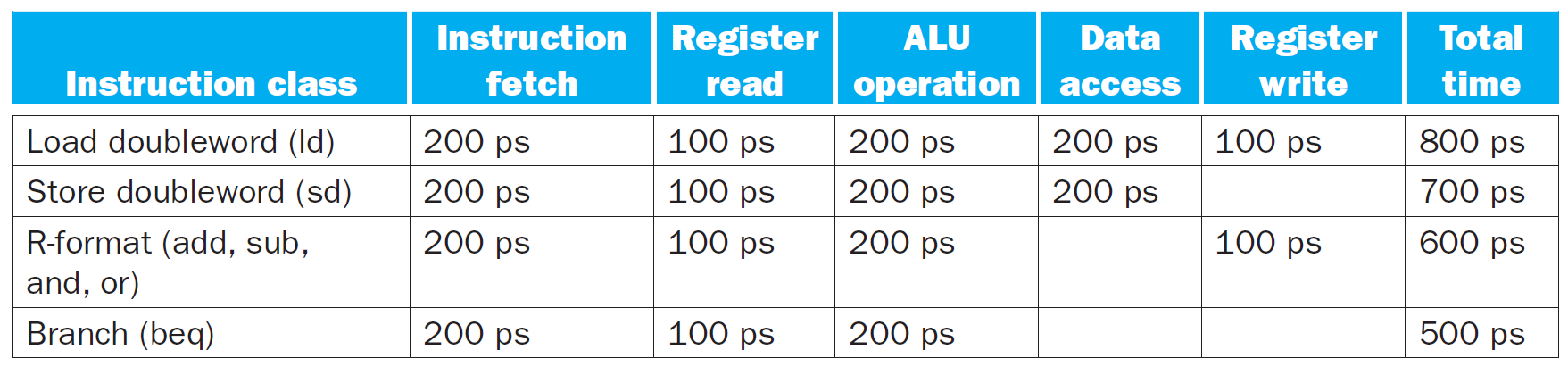
- jump uses WB
- only R don't use sign extender
performance¶
- cycle 數較多,cycle period 較短
- if all stages take the same time, \(T_c\) /= num of stages with pipelining
- e.g.
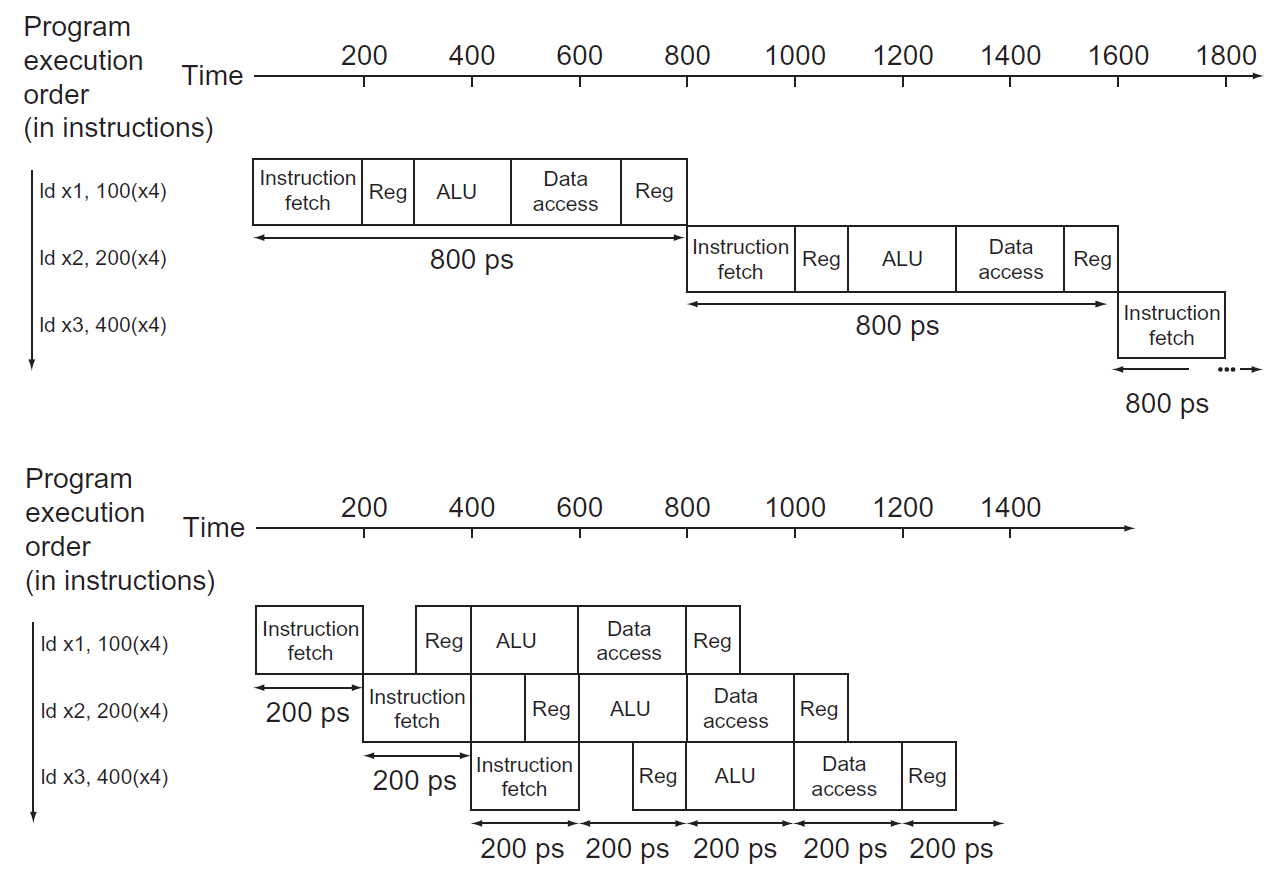
- 如果每個 stage 都花同樣時間,速度就會是 5 倍而非 4 倍
pipeline hazards¶
structural hazard¶
- 資源不夠用
- 一個資源一個時間只能一個人用
- solution: more resources
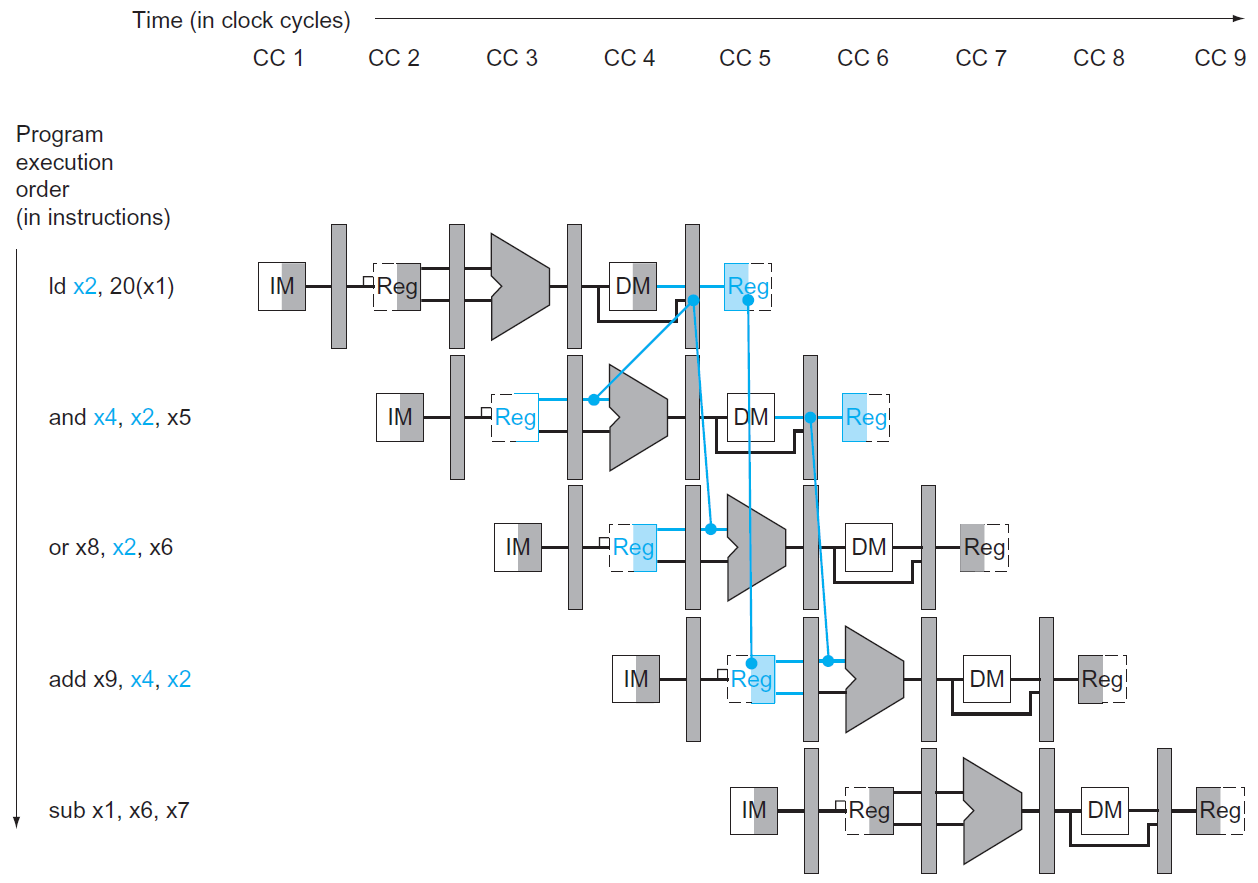
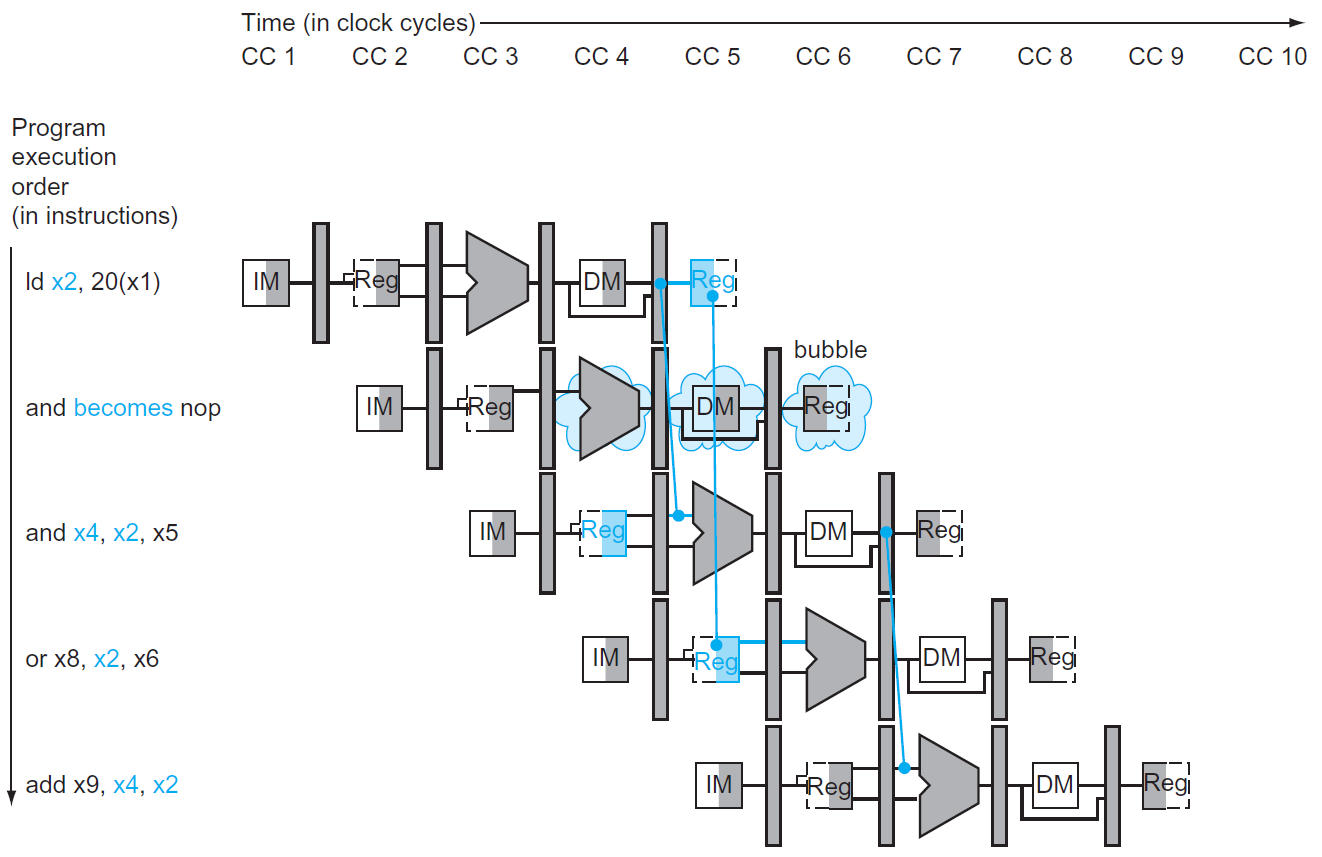
data hazard¶
- current instruction depends on the result of previous instructions → NOP (an operation that does nothing)
- NOP is in code, stall is in hardware
- store won't create hazard
- e.g.
- add x19, x0, x1
sub x2, x19, x3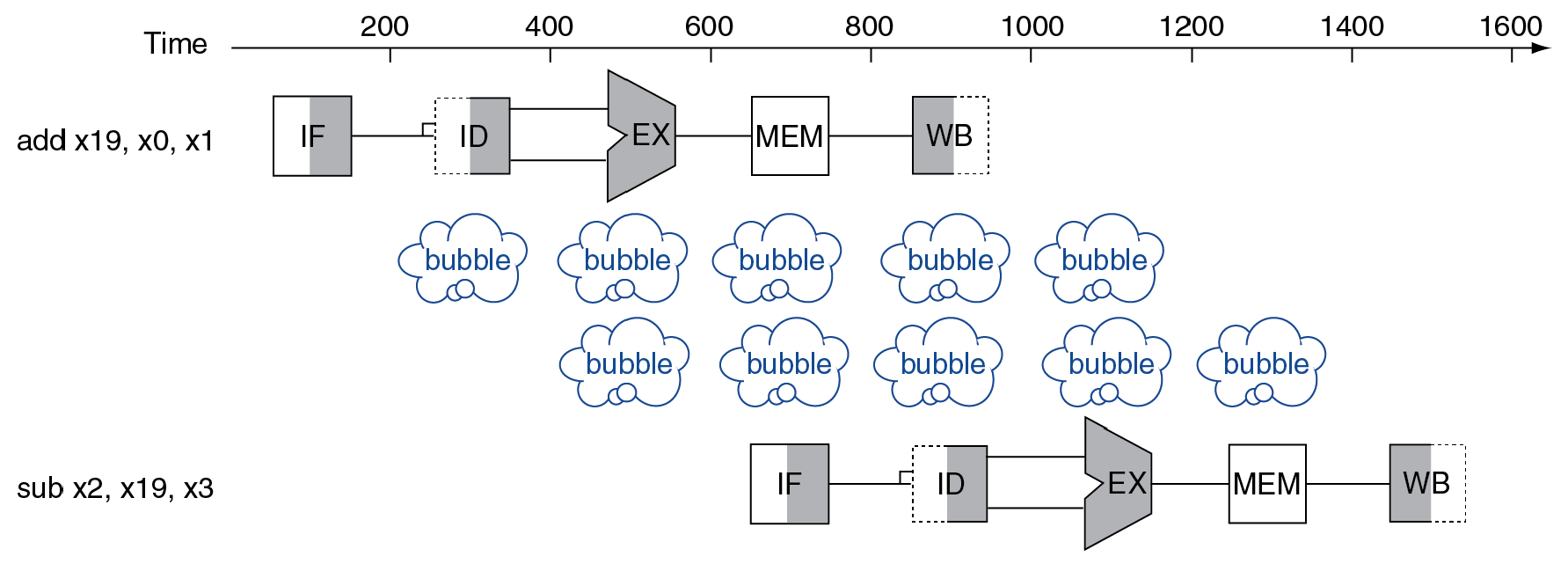
- 要等上一個 WB 才能 ID → 要多等 2 個 cycle
- add x19, x0, x1
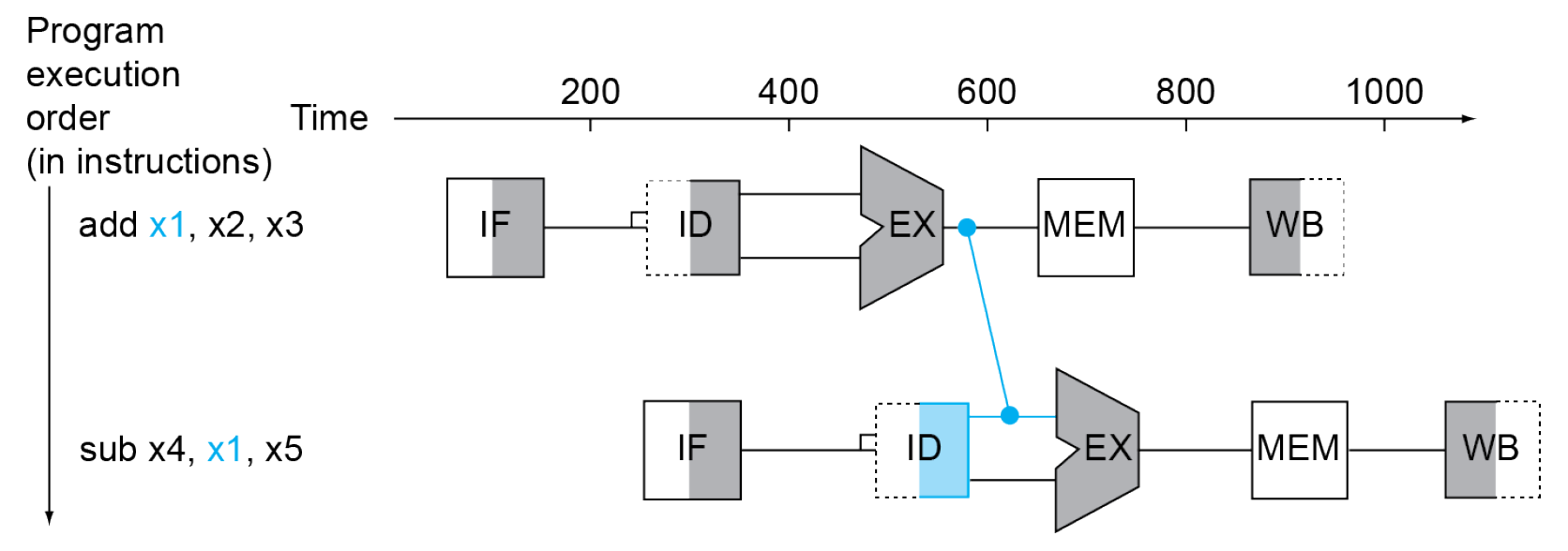
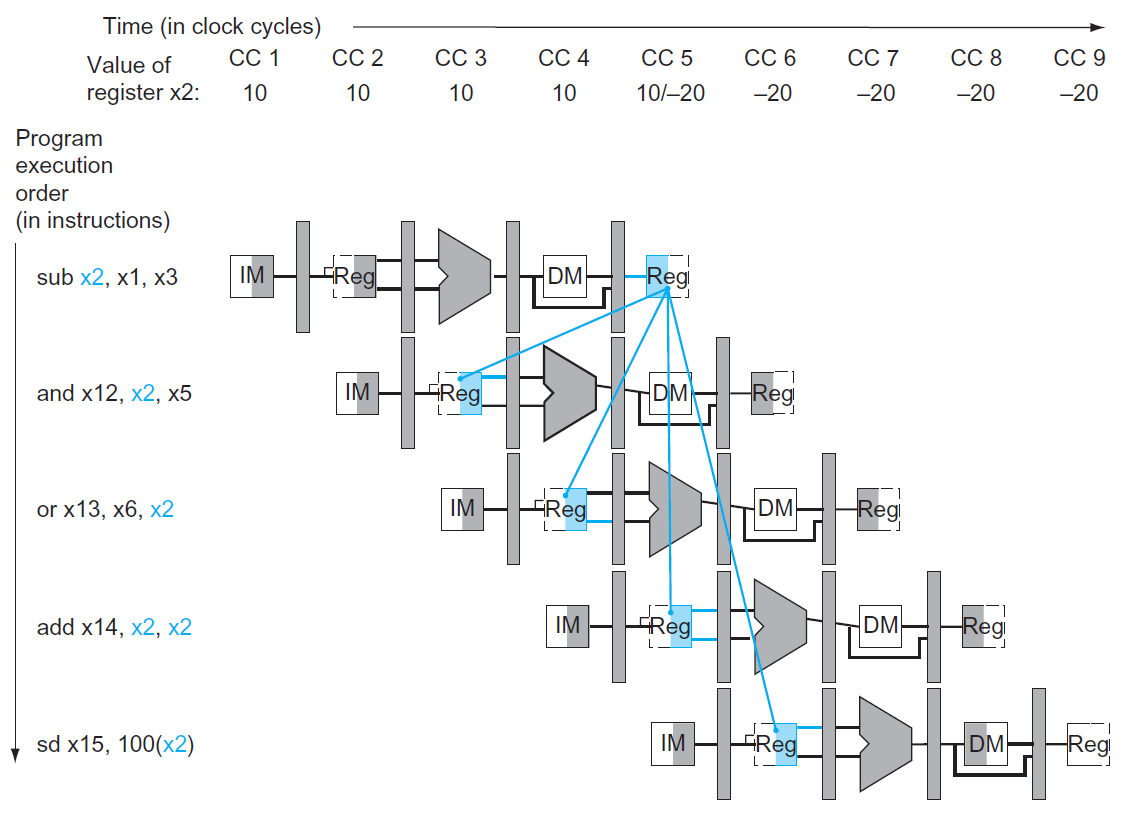
- solution: forwarding/bypassing
- 不等 write back,一生出答案就直接拿
- need extra connection
- e.g.
- load-use data hazard
- 用到的 variable 來自上一個 instruction 的 load
- load 要到 MEM 後才能被使用,while ALU 計算需要在 EX 前拿到值
- need to wait 1 more cycle even with forwarding
- schedule codes to avoid it
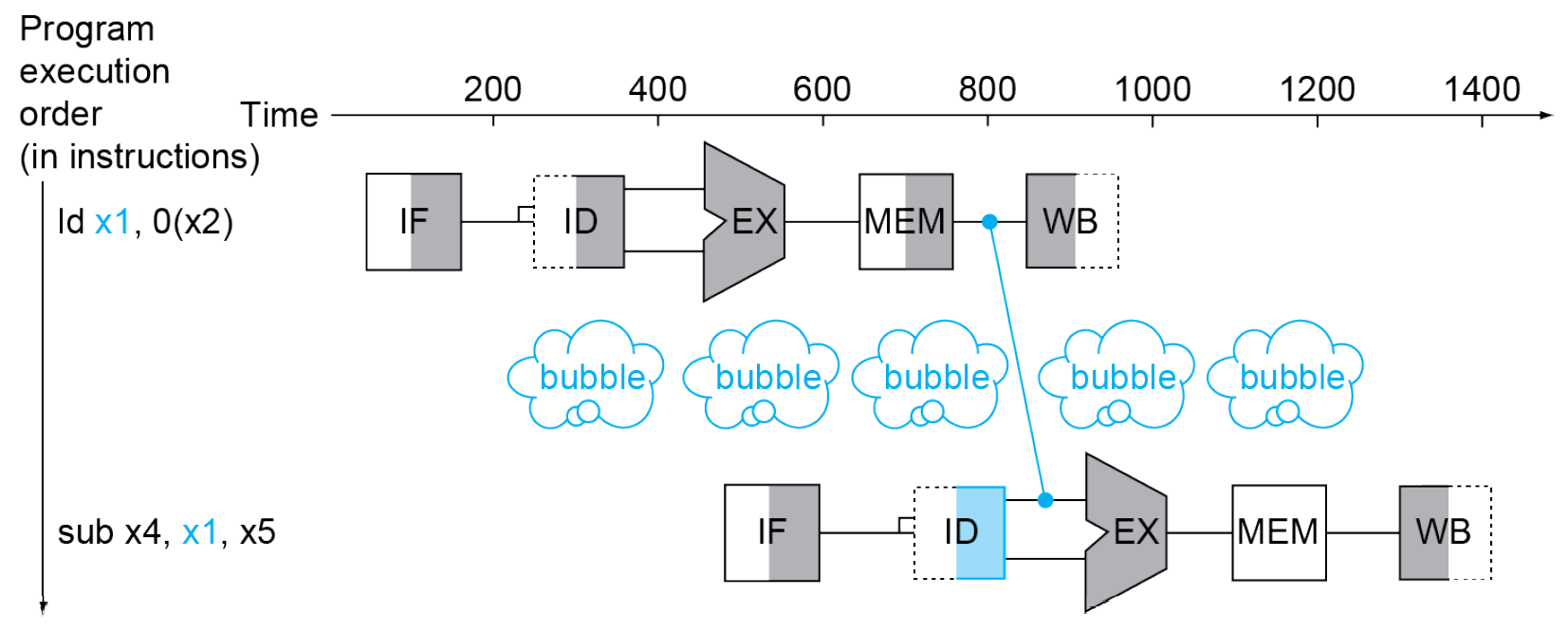

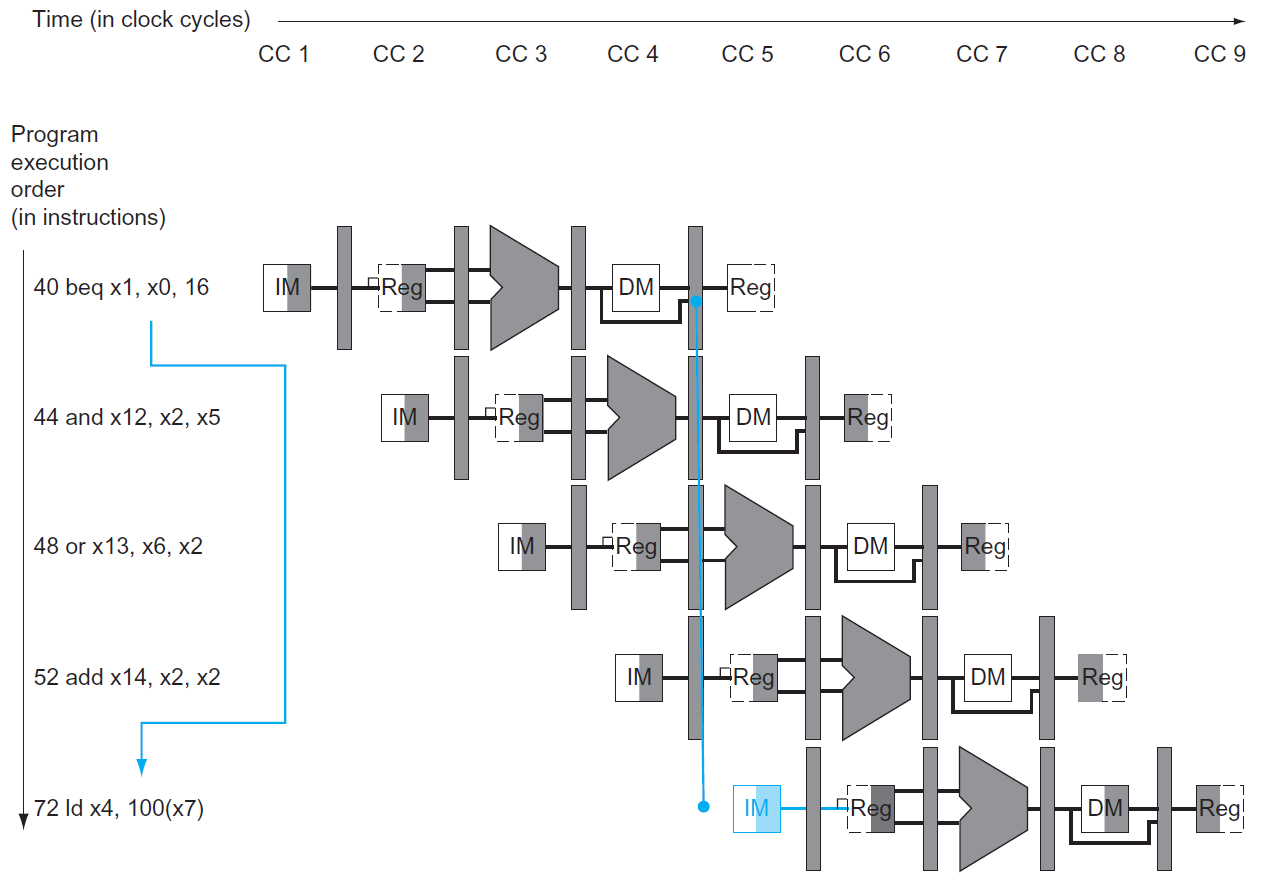
control hazard¶
- depends on branch outcome of previous instruction
- e.g.
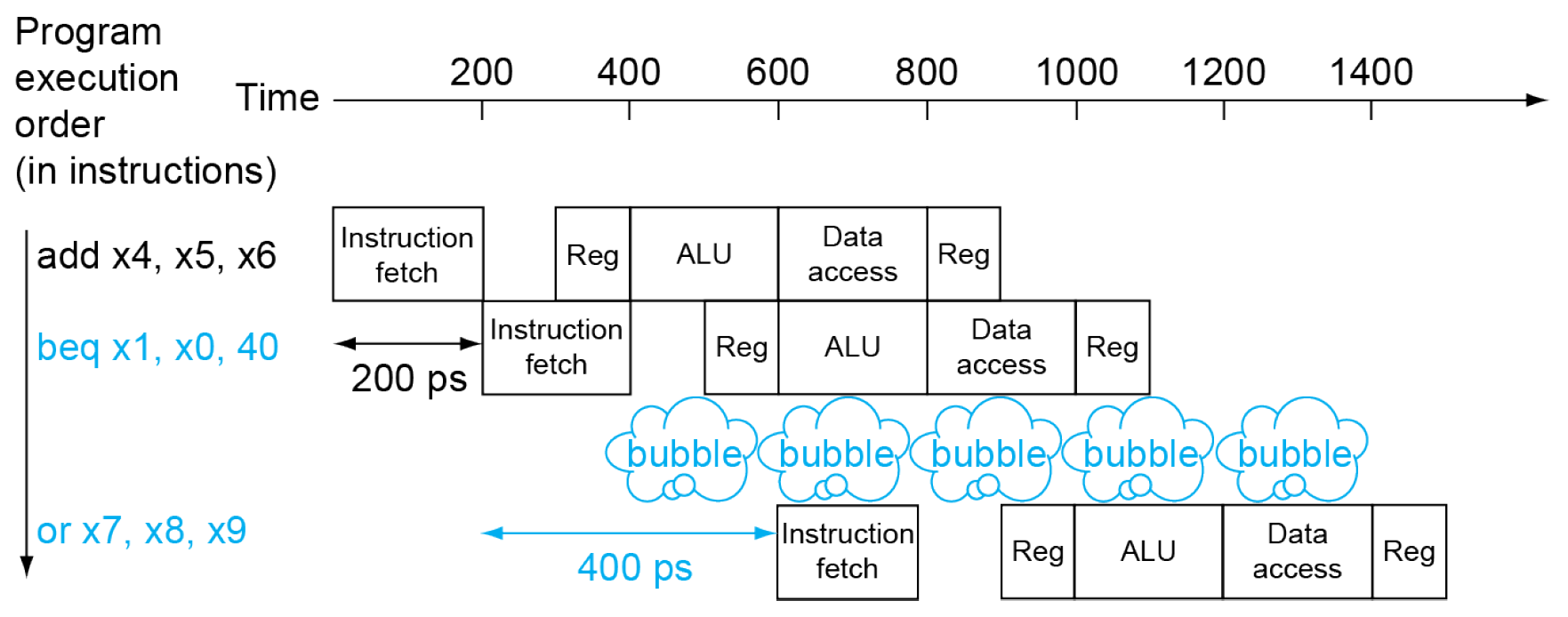
- 要等 beq 判斷(要不要跳)之後才能執行下一個 instruction
- sol: branch prediction
- static branch prediction
- assume branch not taken and do the next instruction immediately, if the branch is taken (assumption incorrect), cancel the instruction
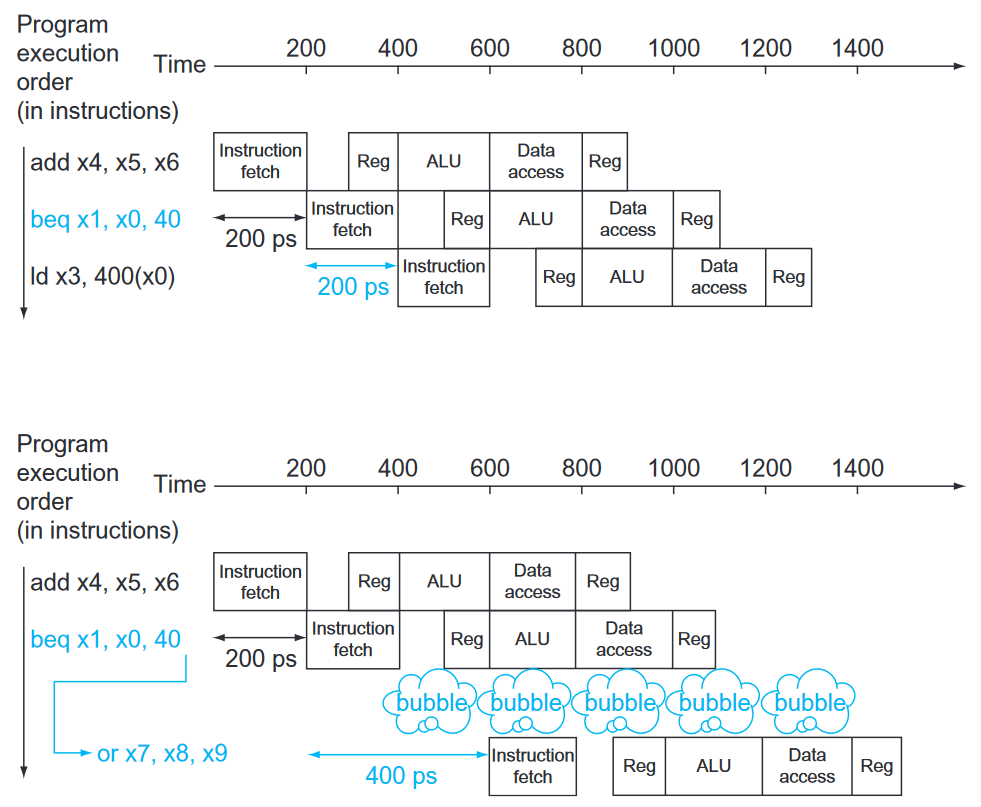
- dynamic
- assumption based on history
- static branch prediction
datapath¶
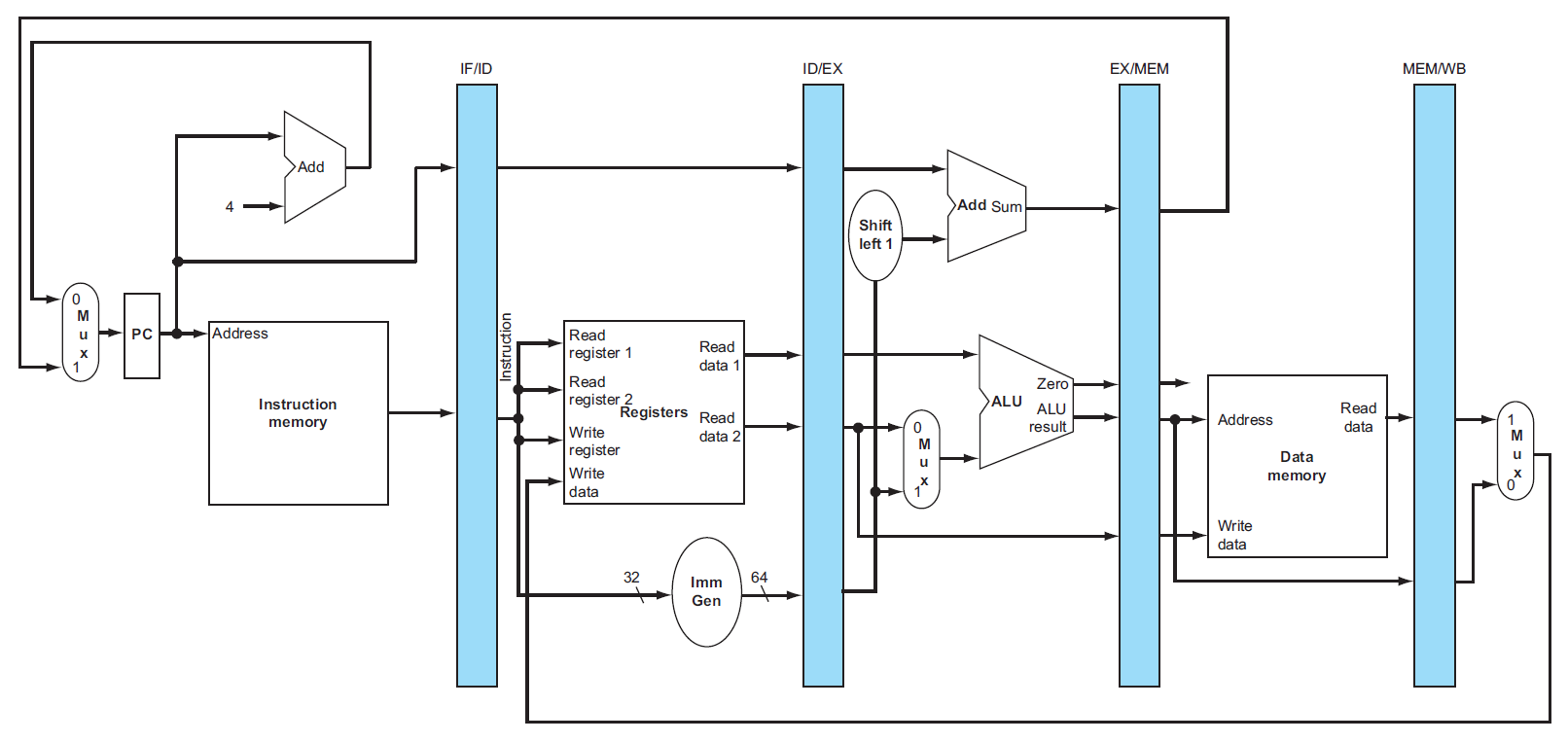
- IF
- ID
- EX
- load
- store
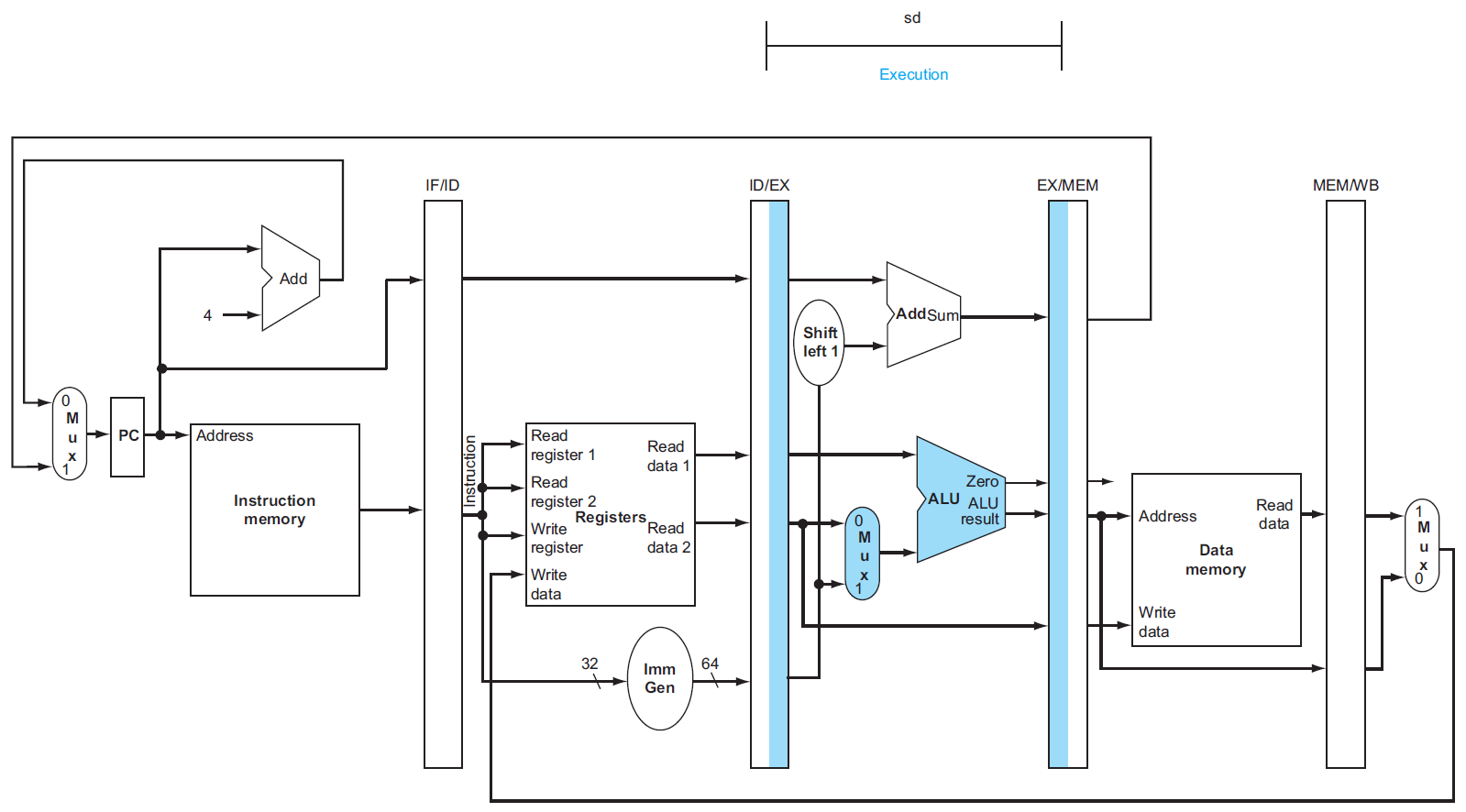
- 2nd register value loaded into EX/MEM
- ???
- load
-
MEM
- load
- store
- load
-
WB
- load
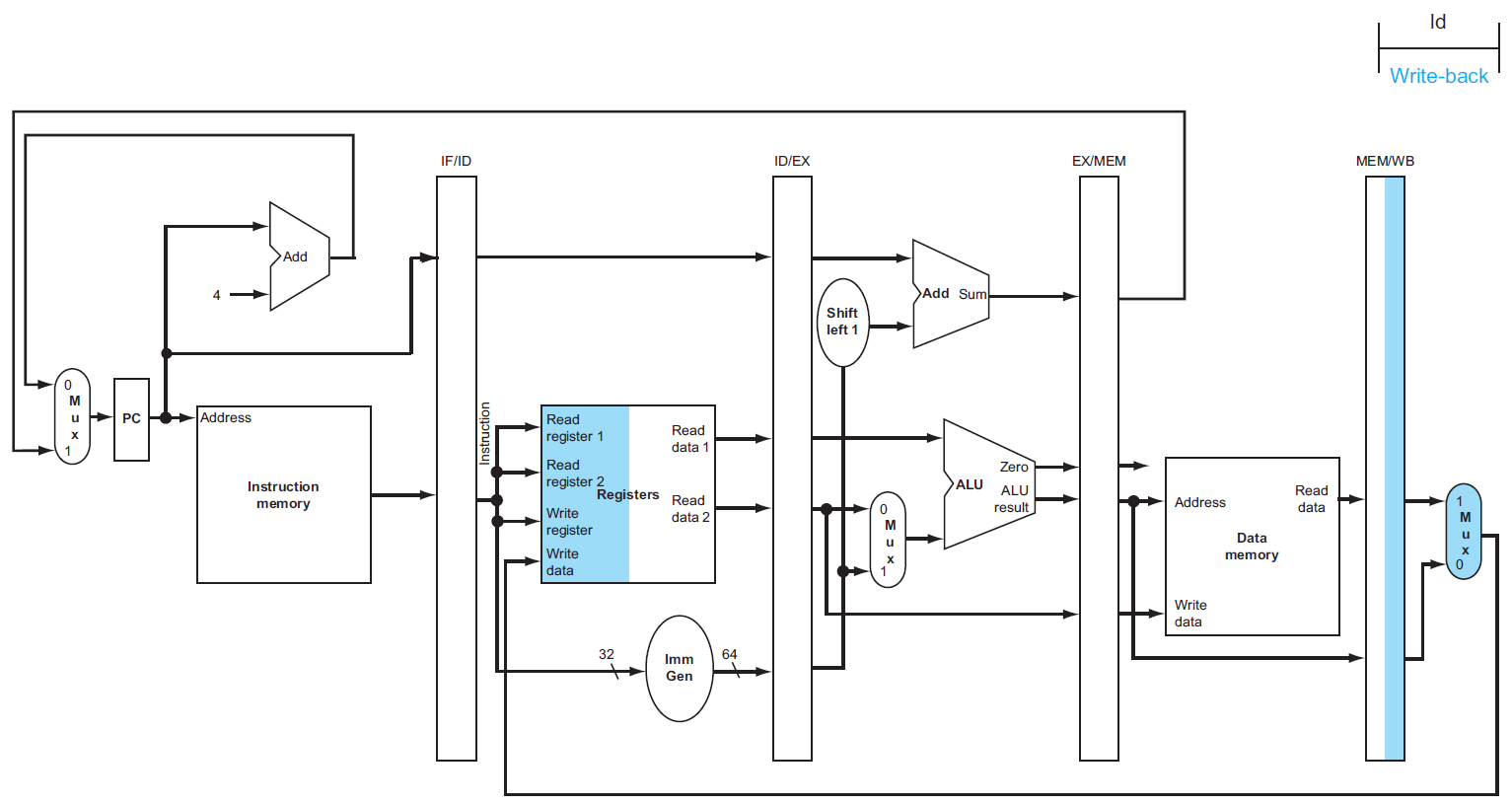
- would be the wrong register number
- correct ver.
- register number passed from ID stage
- 有之後需要用到的 information → 需要 pass along with the datapath
- store
- load
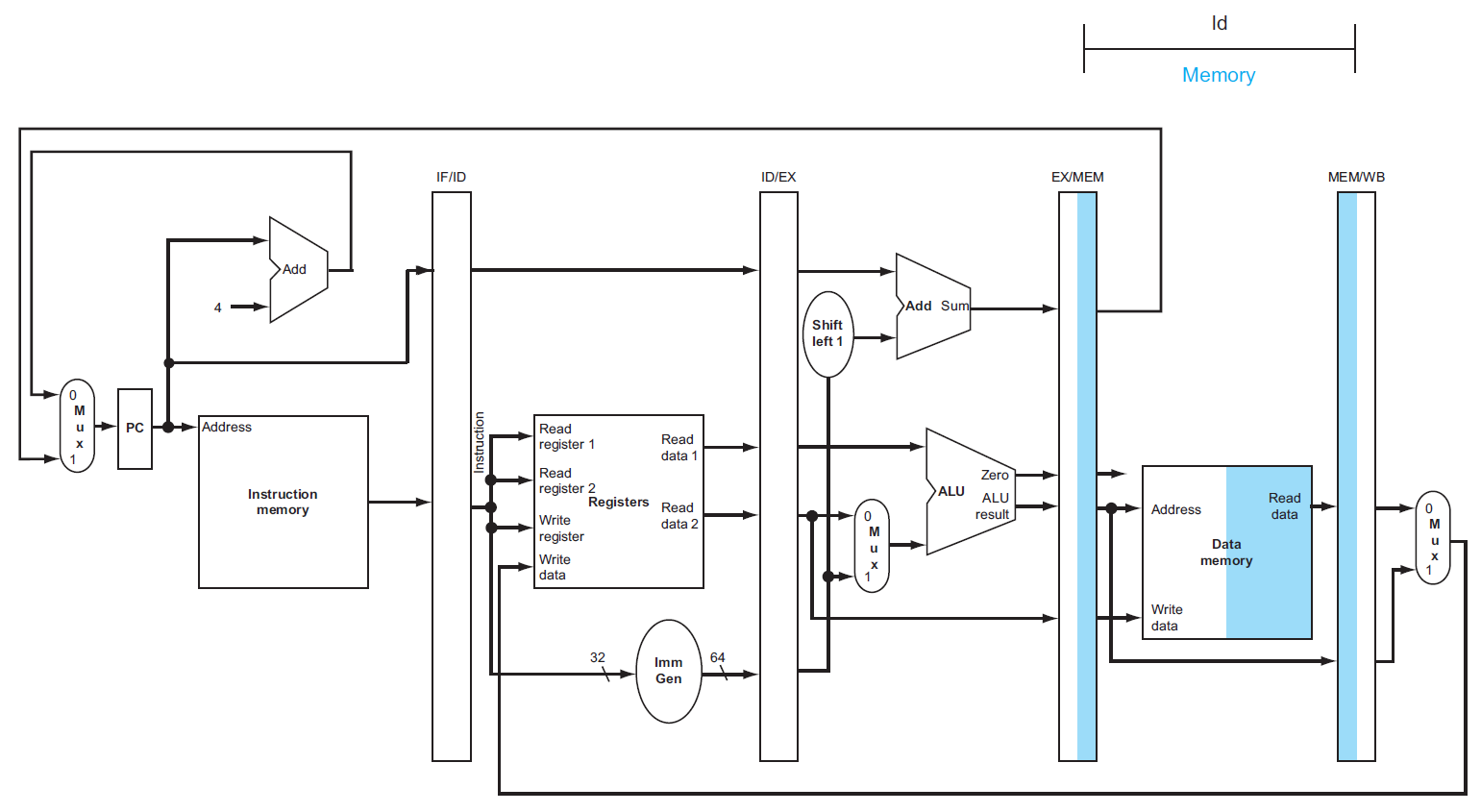
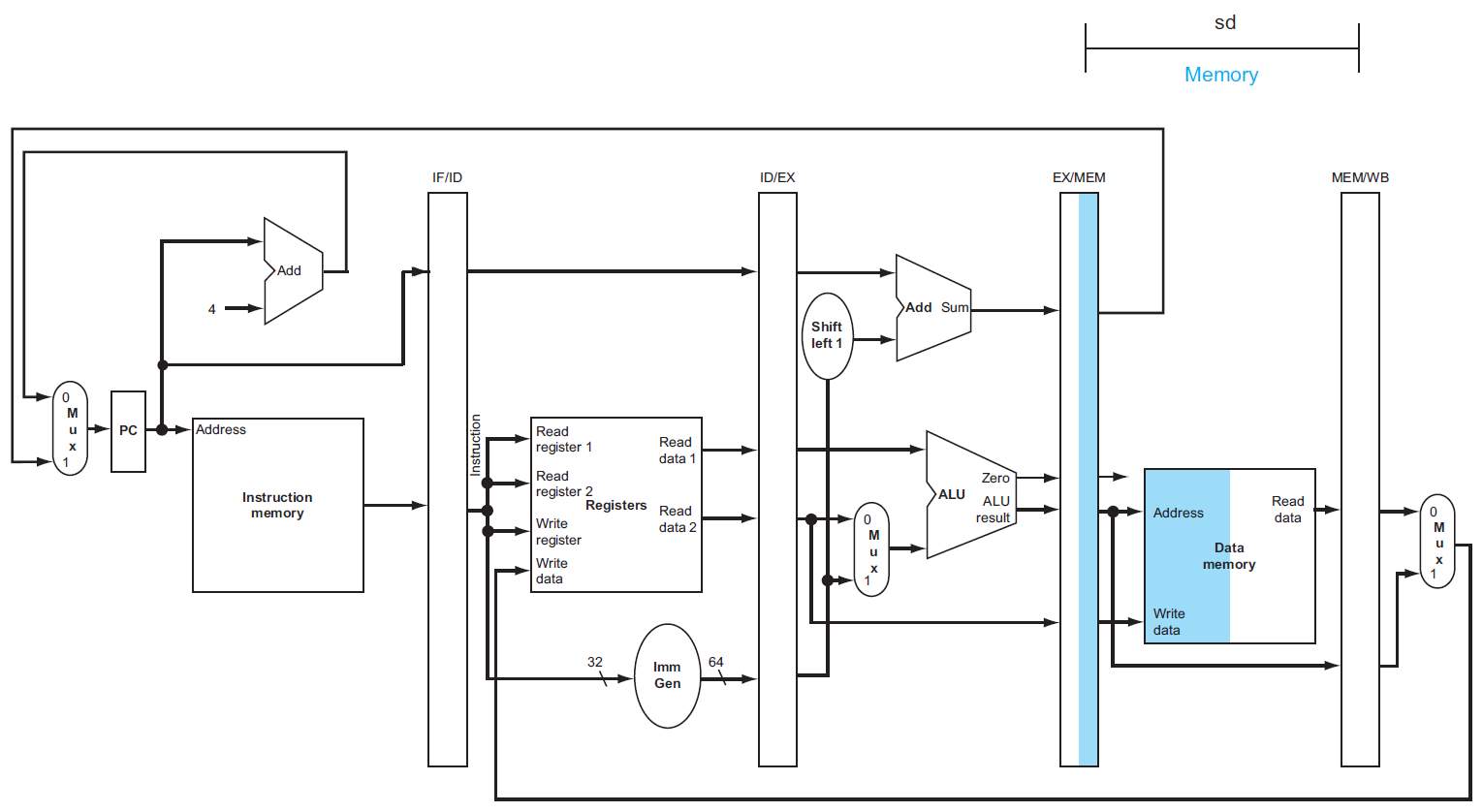
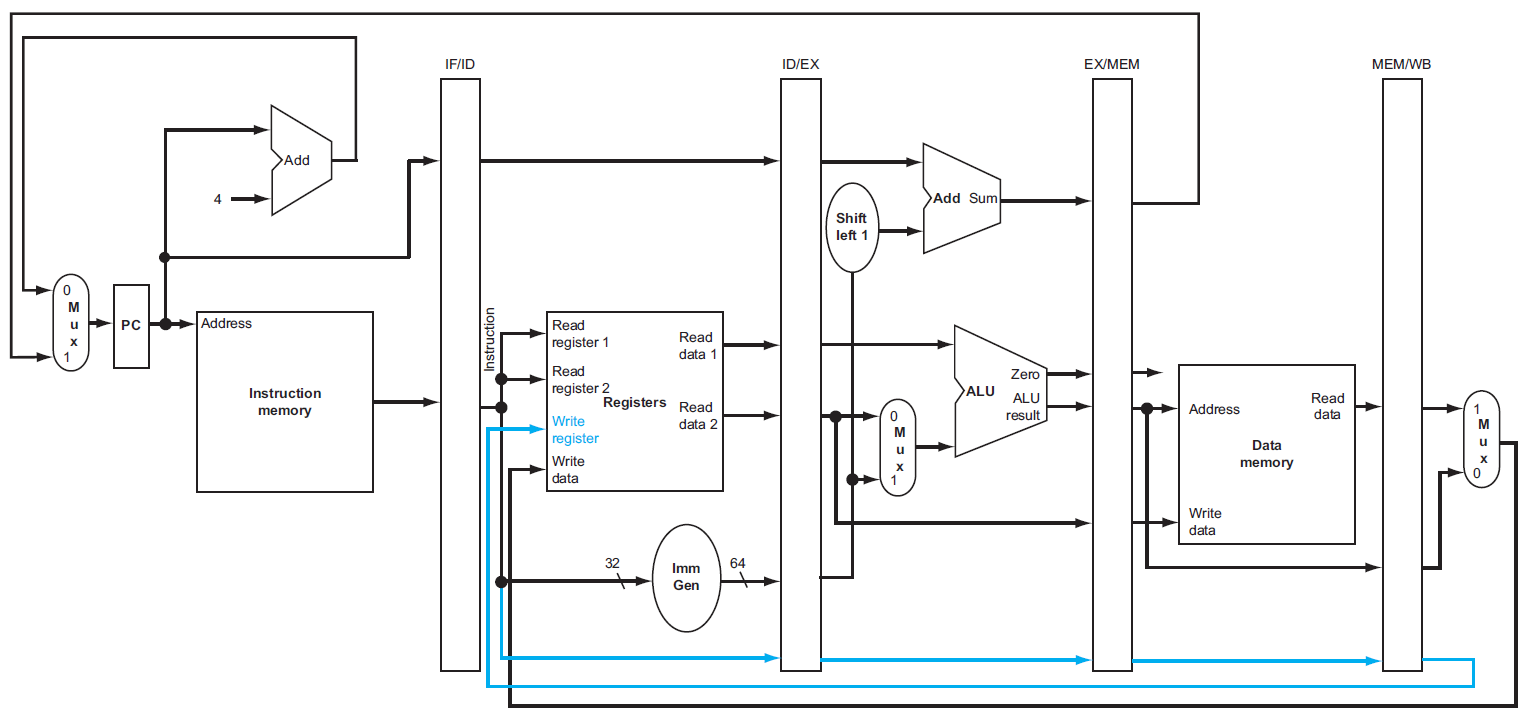
diagram¶
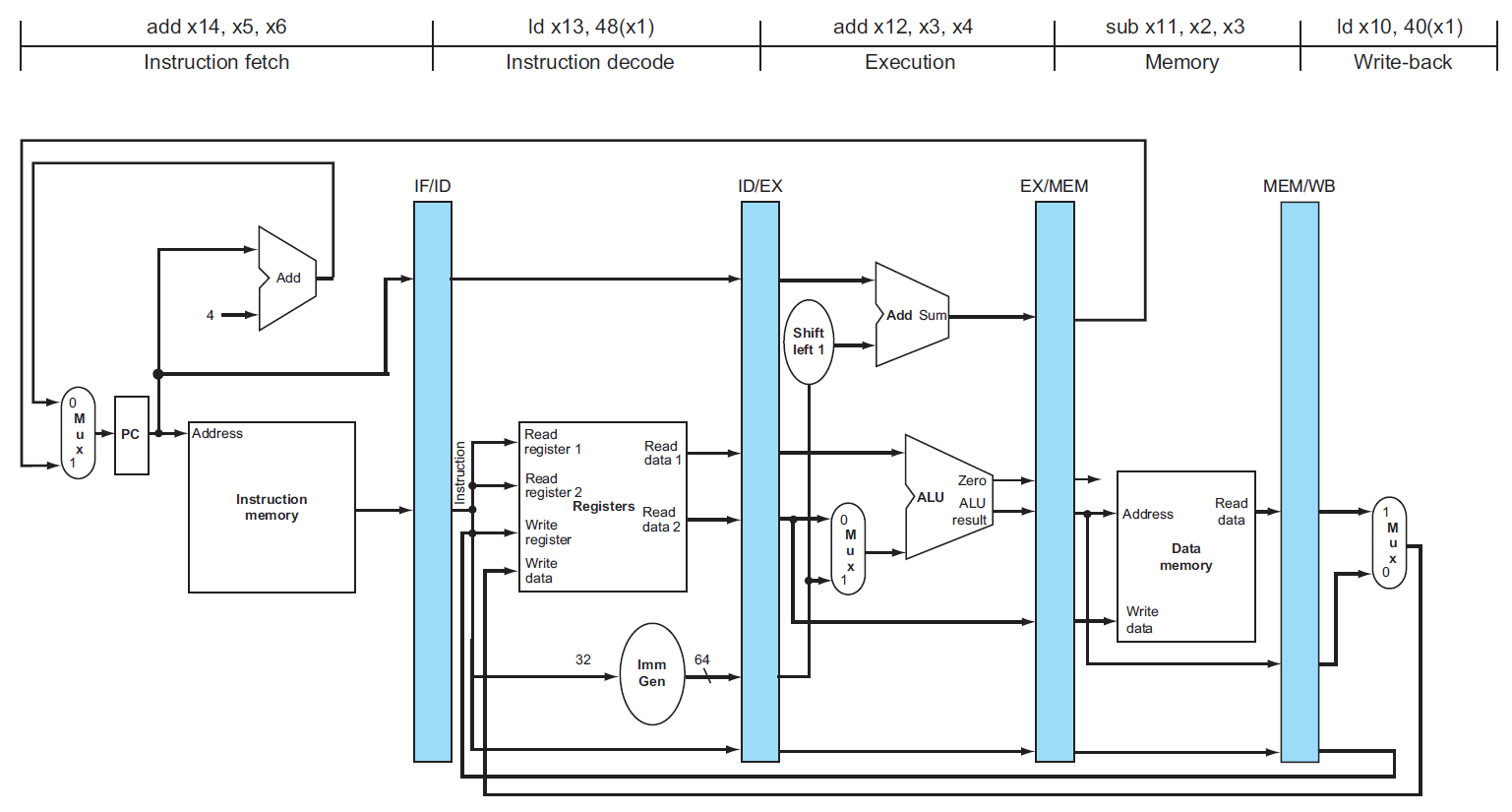
- cycle 5 of previous diagrams
control¶
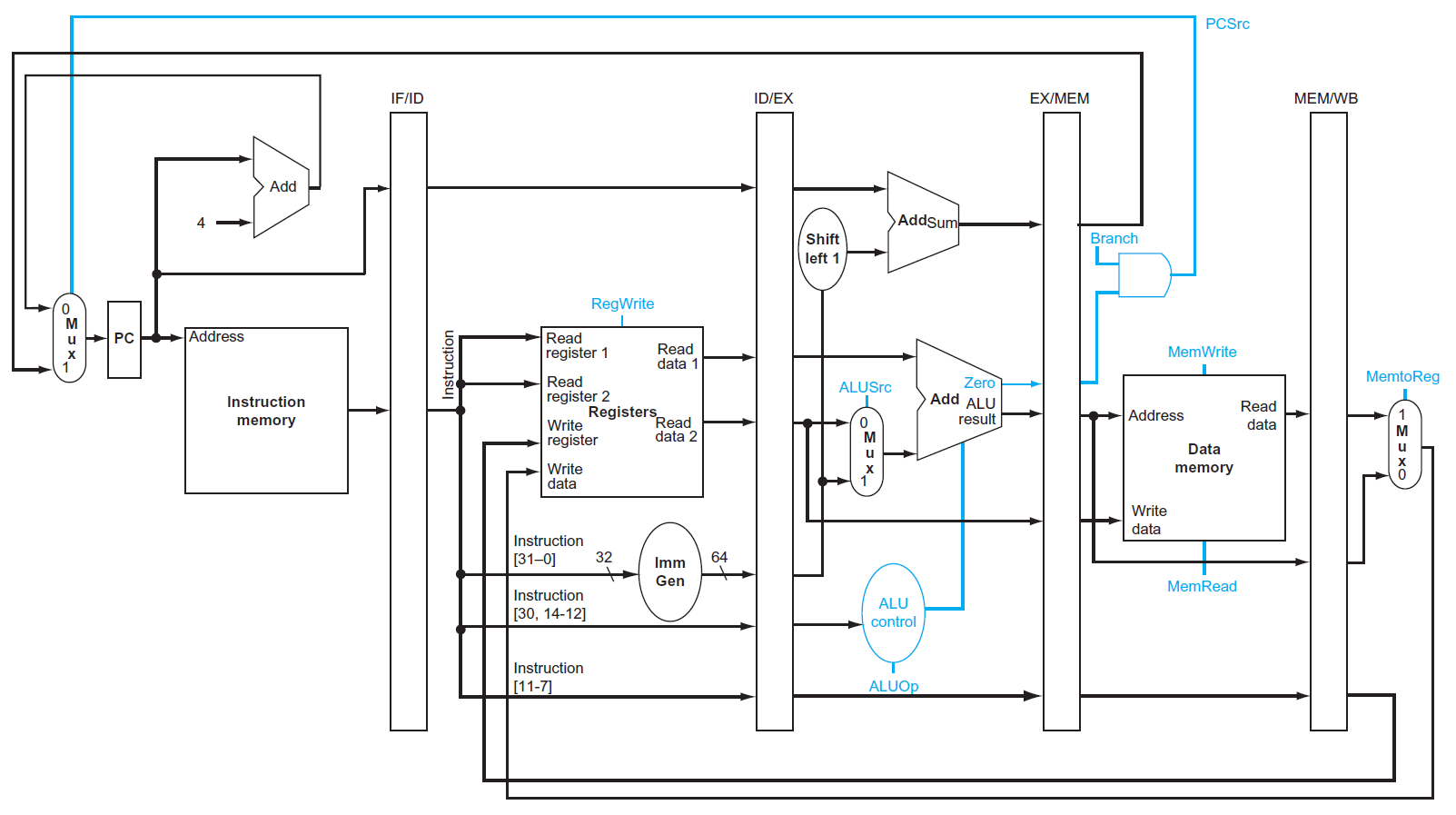
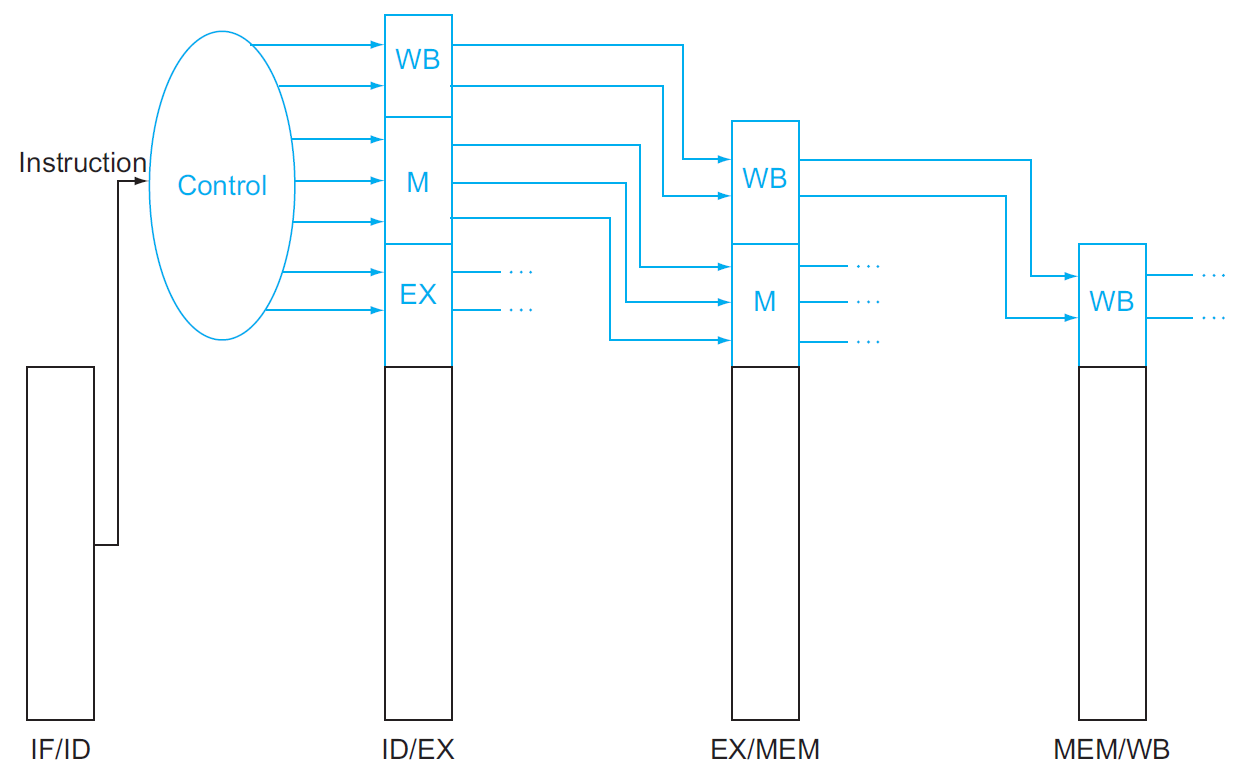
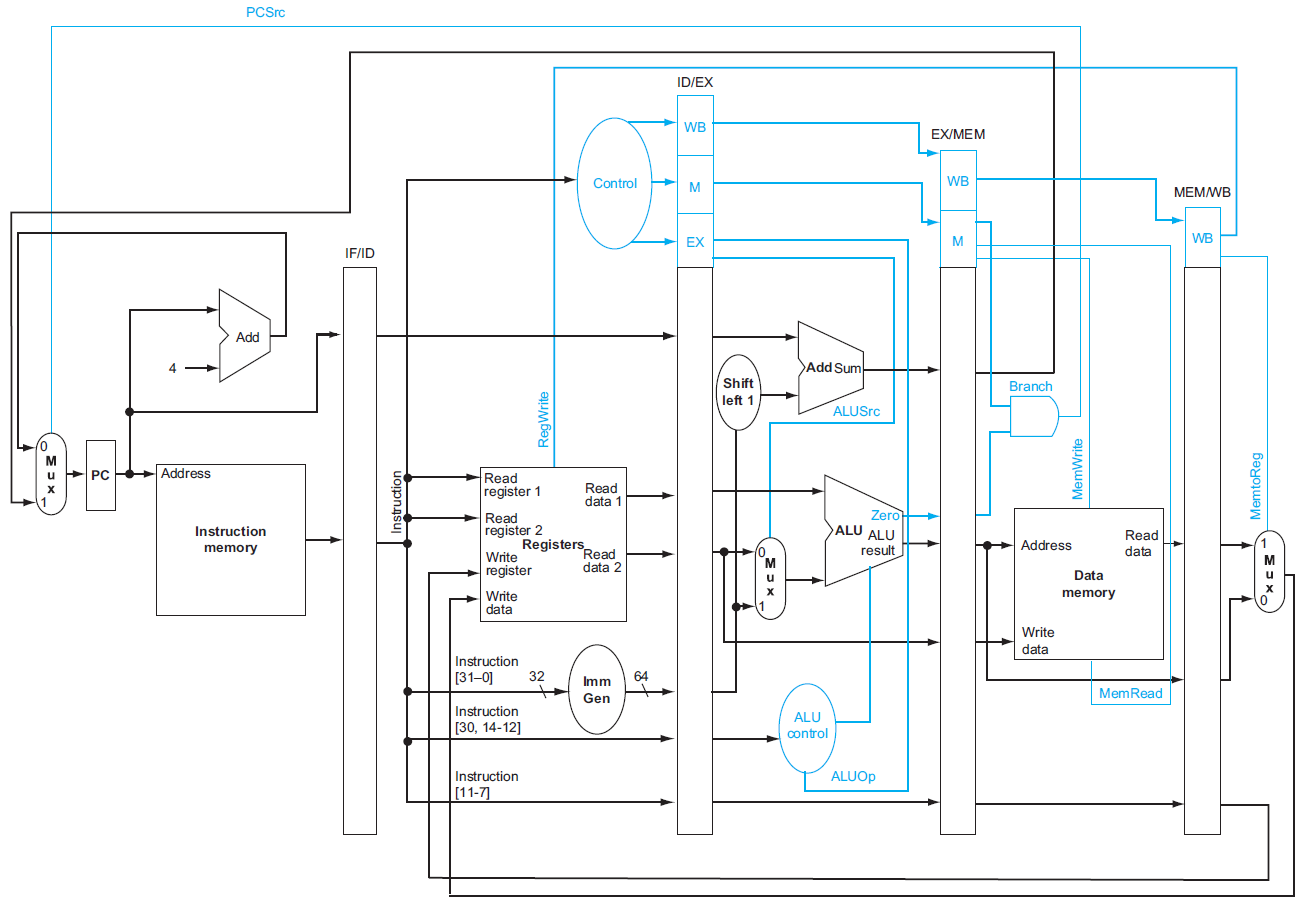
data hazard & forwarding¶
data hazard¶
- EX hazard & MEM hazard
- destination = 前兩個指令的 register
- e.g.
- double hazard
- EX hazard & MEM hazard both happen
- e.g.
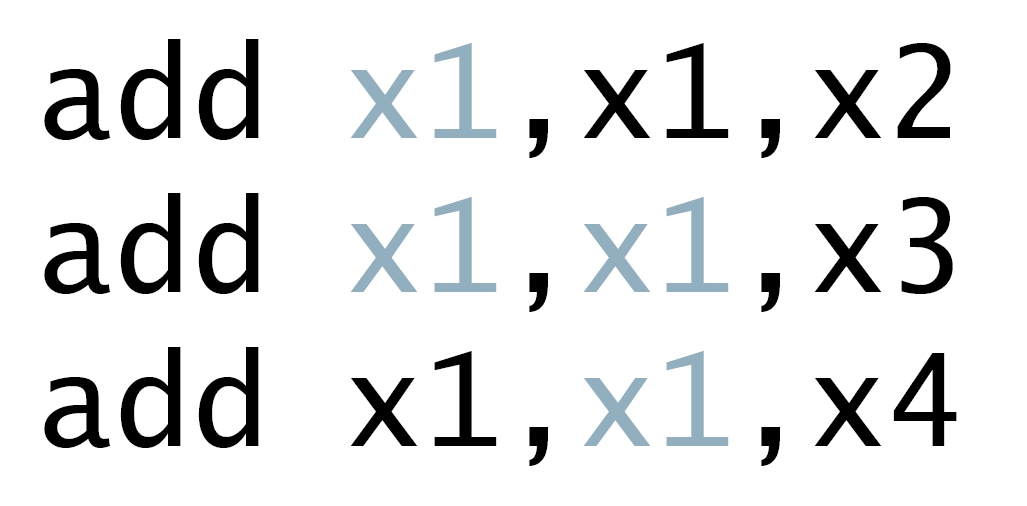
- 1a & 2a
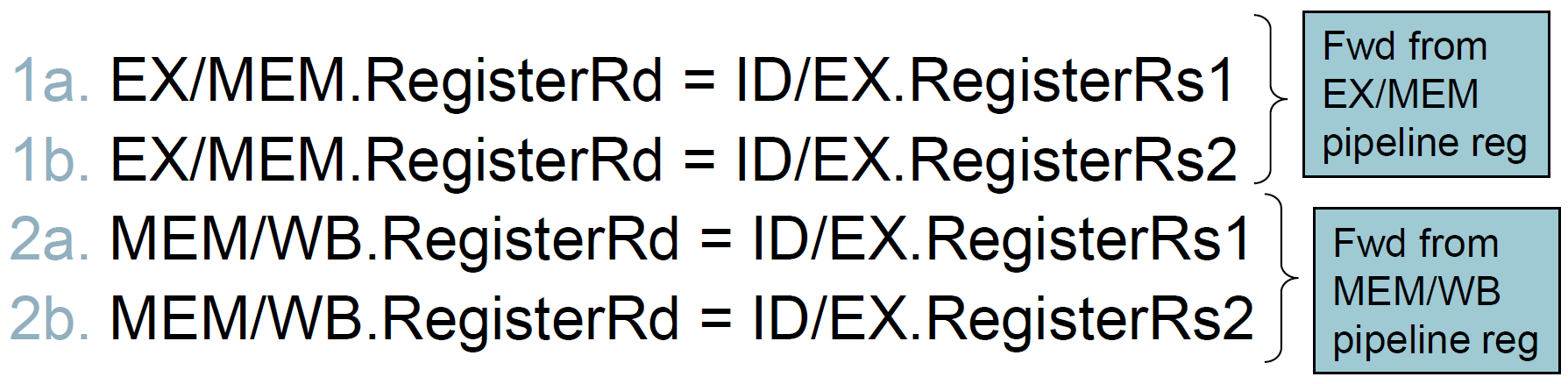
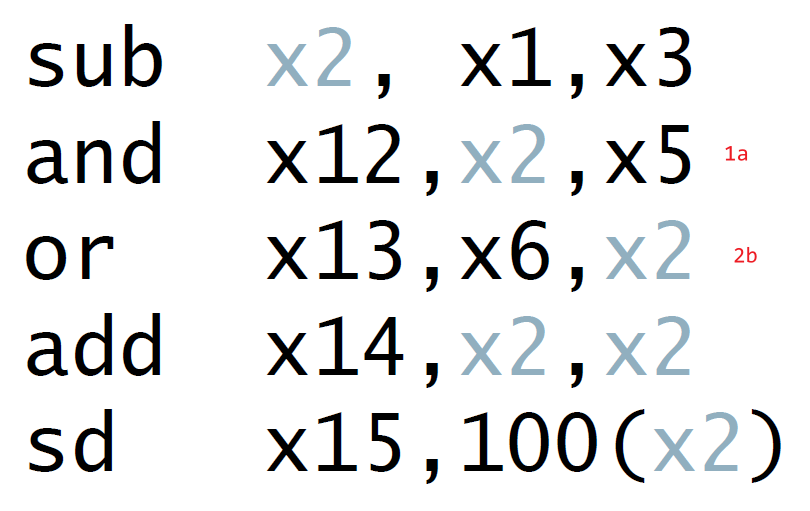
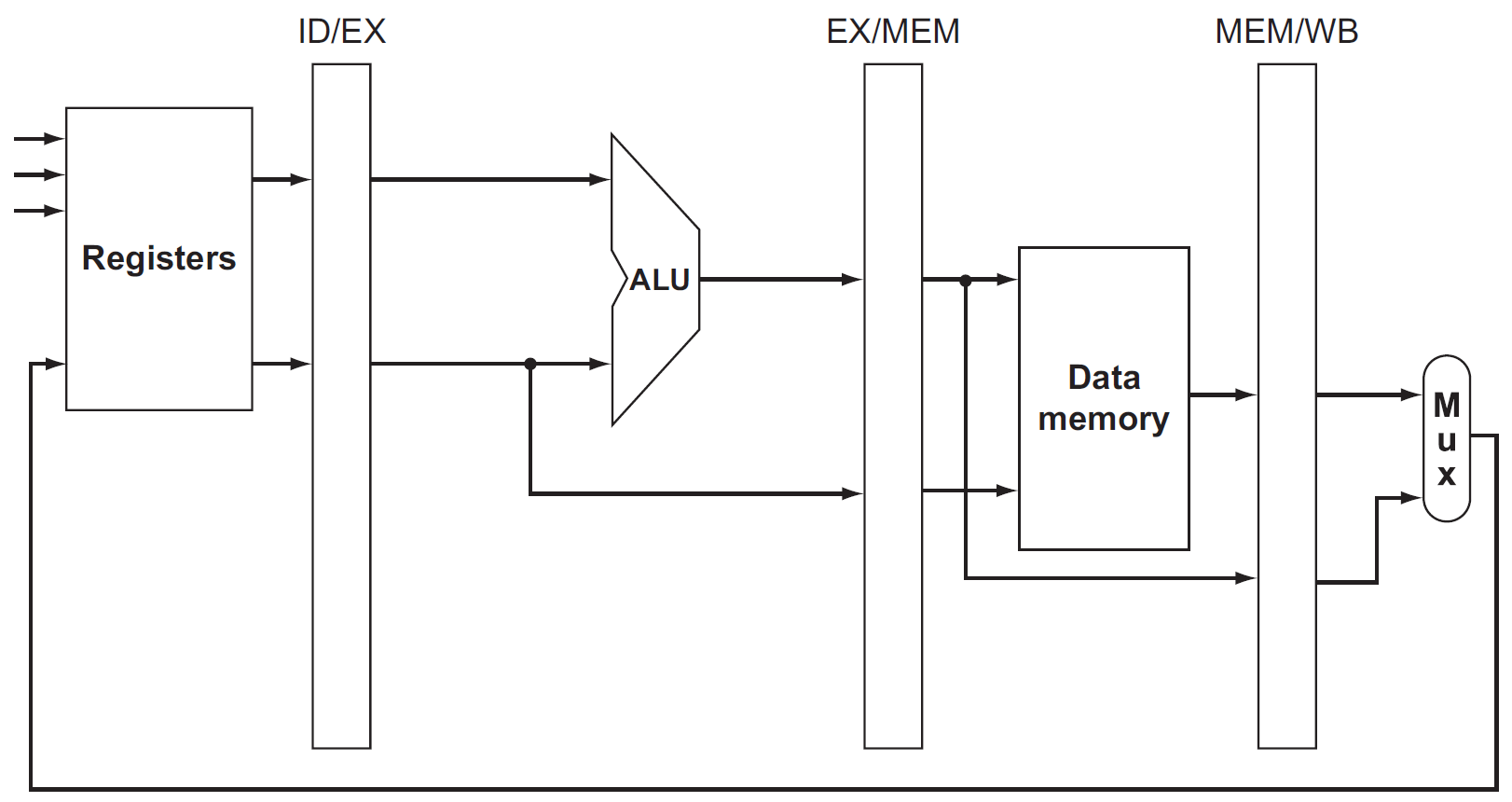
forwarding¶
- without forwarding
- with forwarding
- need forwarding when
- EX/MEM or MEM/WB will write to a register && RD != x0 && RD = RS of ID/EX
- EX hazard
- MEM hazard

- blue part: only forward this type when no EX hazard to avoid double hazard
- control
- 哪一種 hazard → mux control
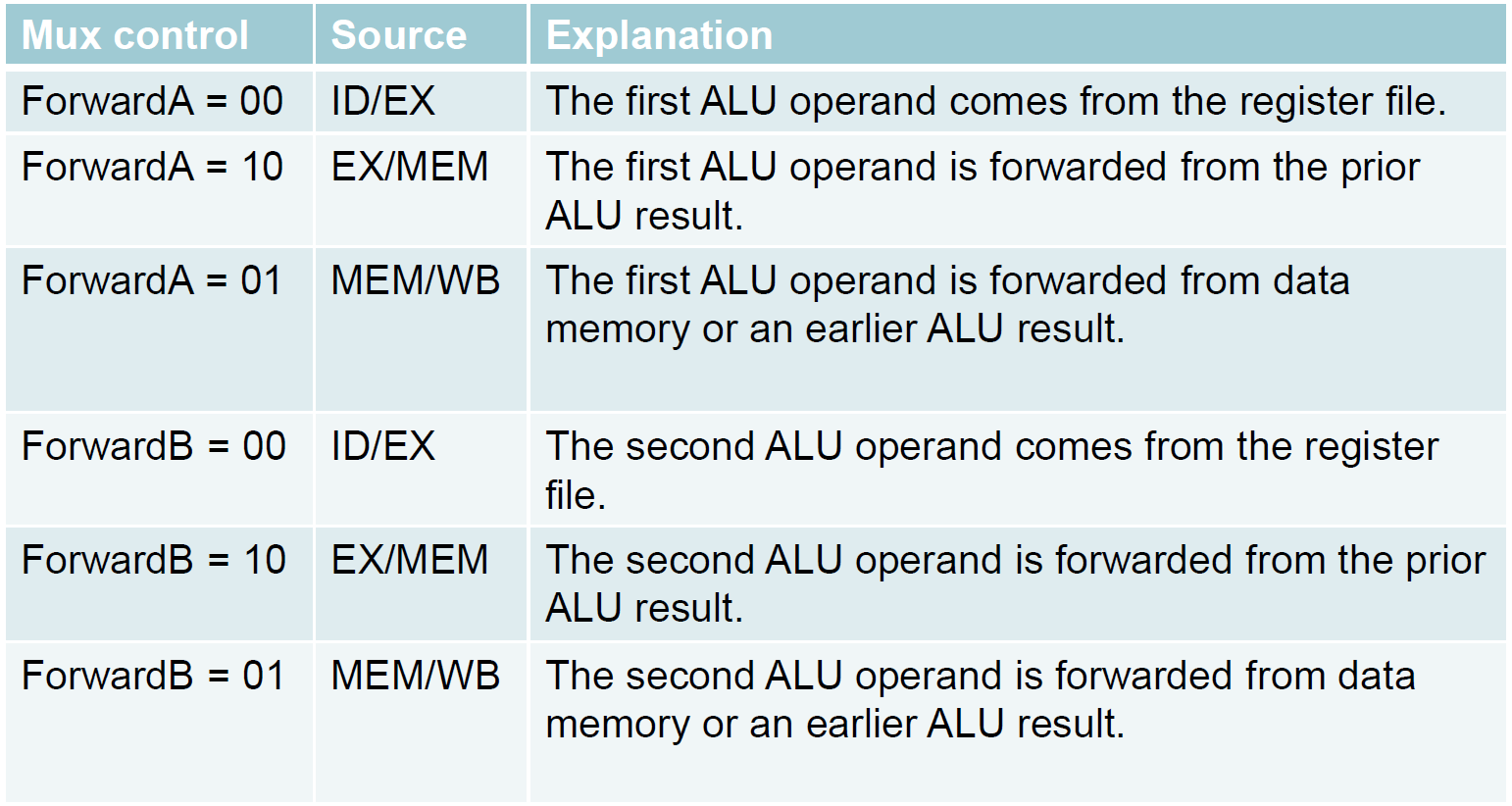
- 1a → ForwardA = 10
- 2a → ForwardA = 01
- 1b → ForwardB = 10
- 2b → ForwardB = 01
- datapath
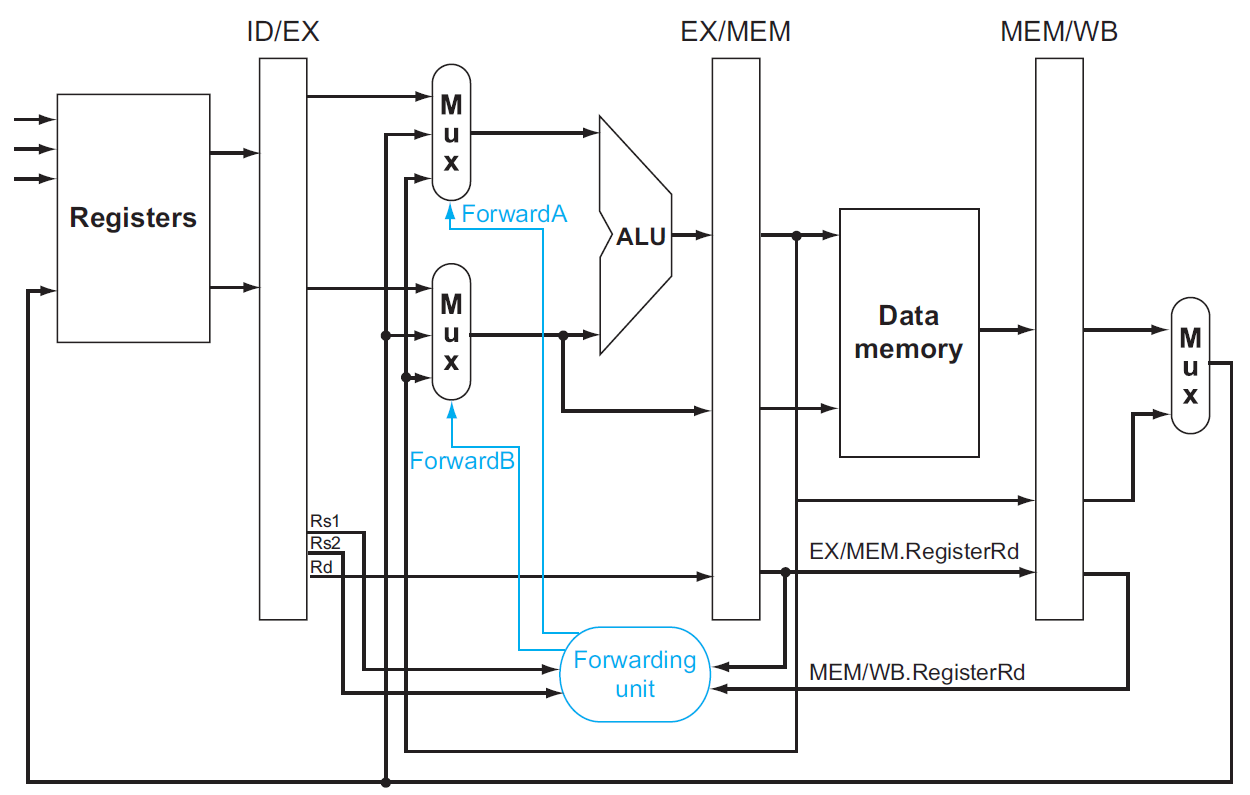

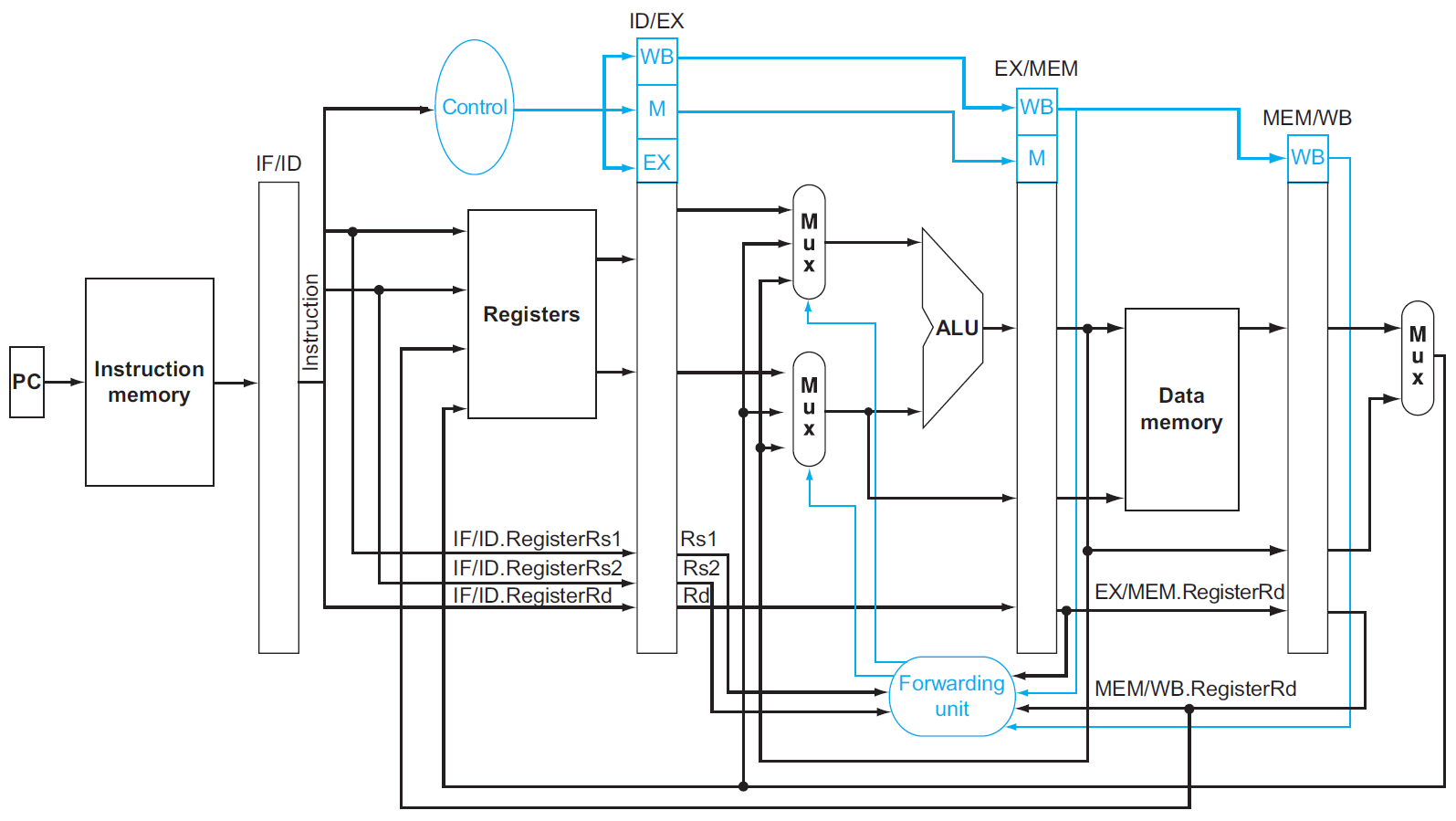
stalling¶
- hazard detection unit
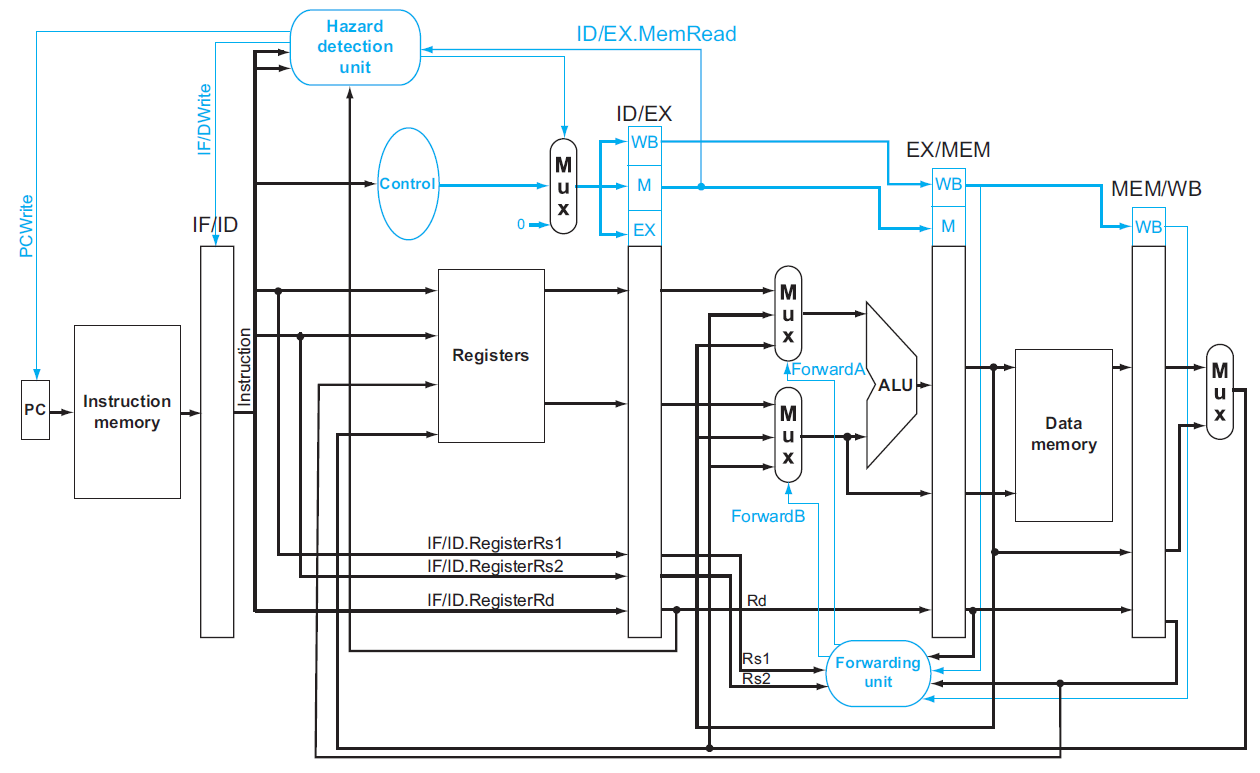
- operate at ID stage
- have hazard → stall
- load-use data hazard 只能 stall → nop i.e. do nothing
control hazards¶
dynamic branch prediction¶
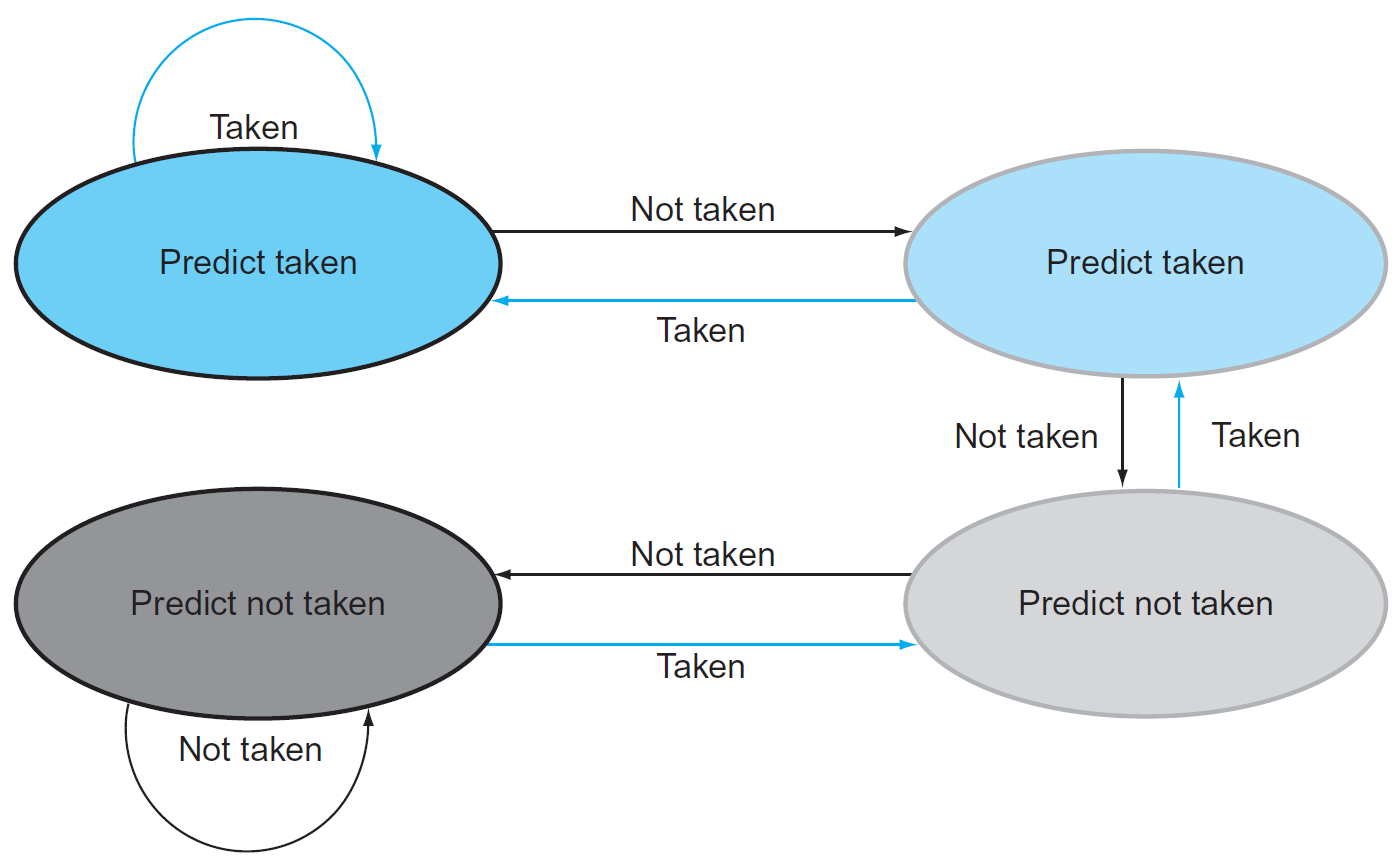
- 1-bit predictor
- 2-bit predictor
- wrong prediction twice → change
exceptions¶
- flush instructions
- handling exception
instruction level parallelism, ILP¶
- to increase ILP
- deeper pipeline
- less work per stage → shorter clock cycle
- multiple issue
- multiple pipeline
- multiple instructions per cycle
- CPI < 1, IPC = 1/CPI > 1
- deeper pipeline
Static Multiple Issue¶
- two-issue pipeline
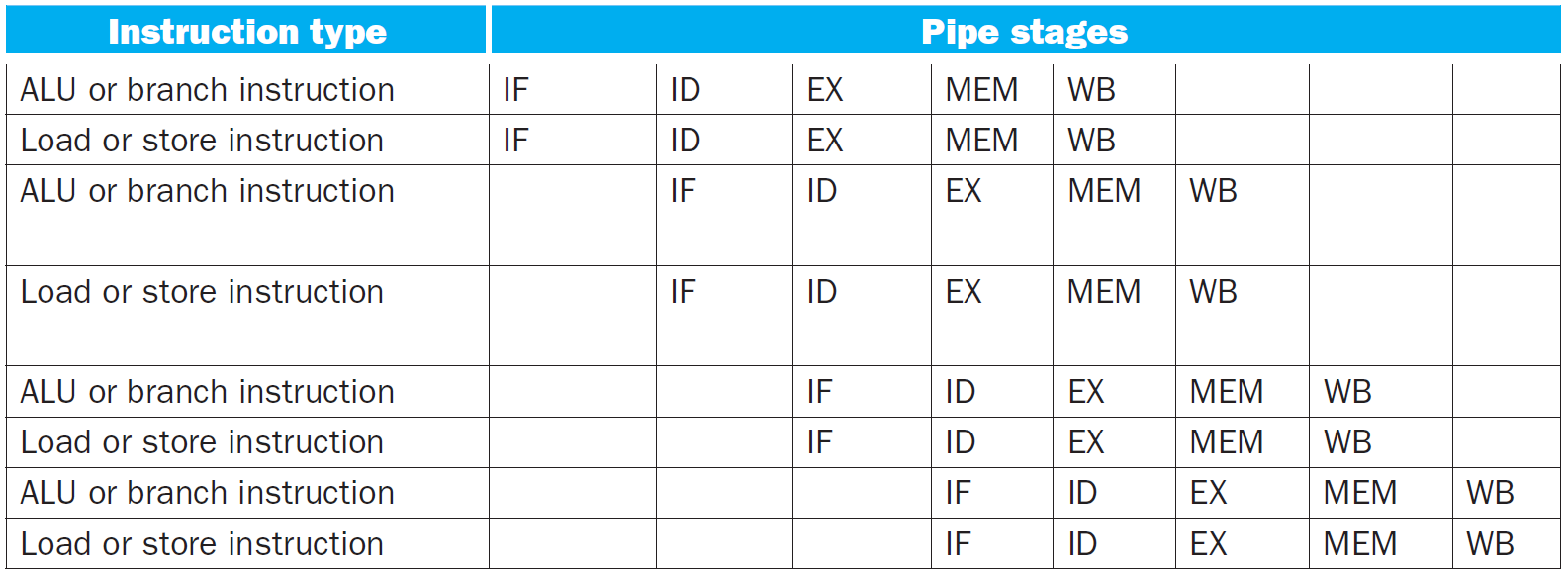
- 一邊 ALU/branch 一邊 load/store
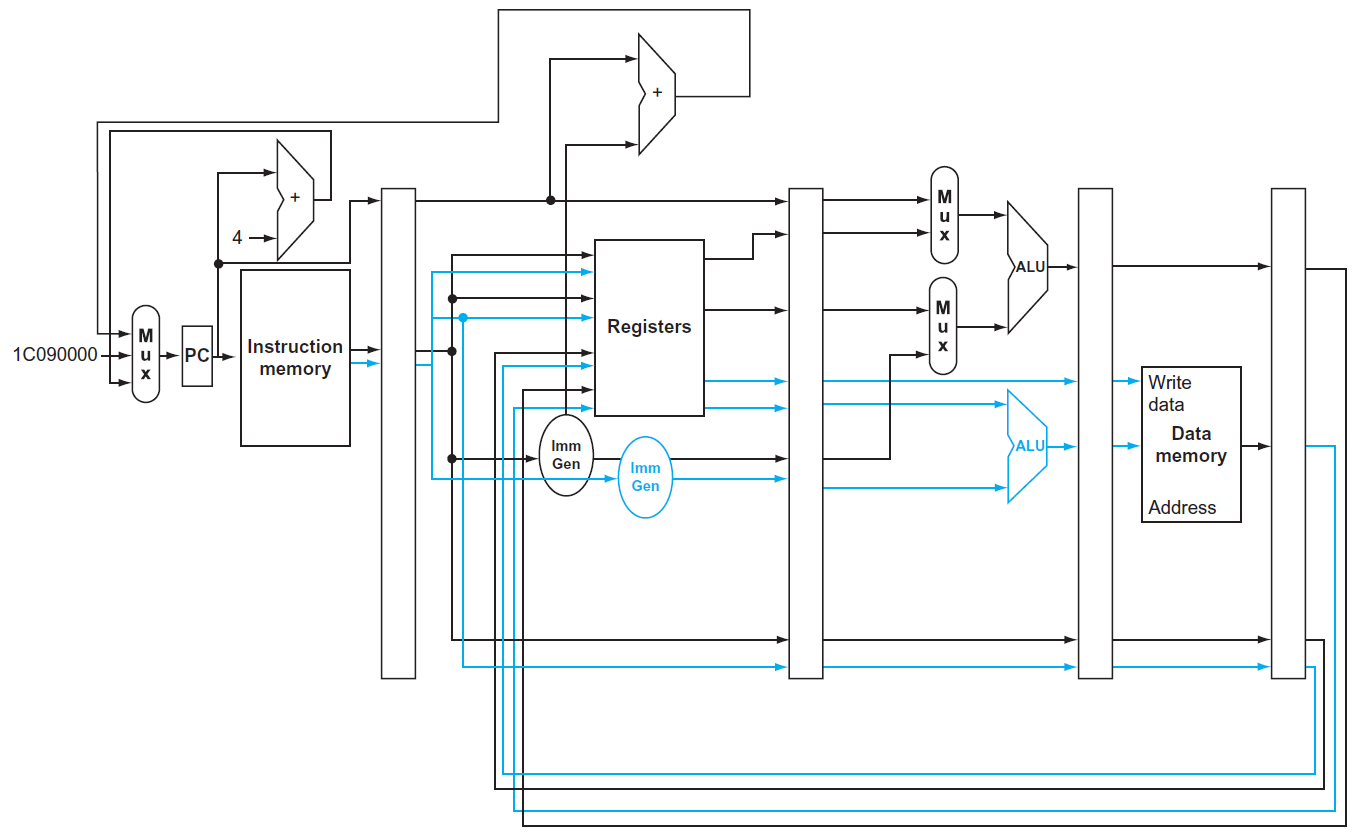
- need extra hardware
- more instructions executing in parallel to avoid hazard
- EX data hazard
- can't forward ALU result to load/store, need to stall (?)
- load-use data hazard
- load result can't be used at next cycle (?)
- EX data hazard
- scheduling
- loop unrolling
- replicate loop body multiple times → more things to fill in the blanks, and can 化減

- e.g.



Dynamic Multiple Issue¶
- dynamic multiple-issue processors = superscalar processors
- dynamic pipeline scheduling
- can execute instructions out of order
- e.g.
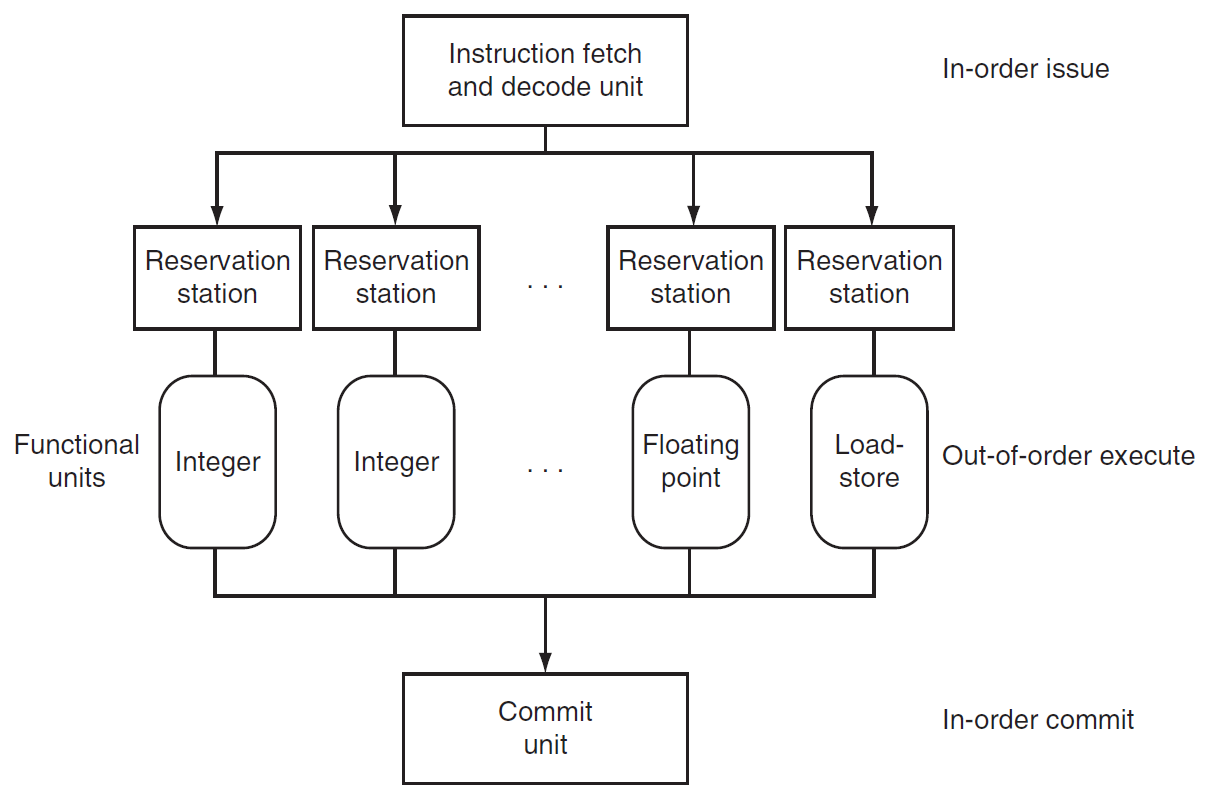

problems¶

load & store 會用到 data memory,so 其他的 IF stage 不能跟 ld & sd 的 MEM stage 衝到

Ch5 Memory Hierarchy¶
intro¶
- locality
- temporal locality
- 時間上很近的會很常被用到
- loop
- spatial locality
- 空間上很近的會很常被用到
- sequential instructions
- temporal locality
- memory hierarchy
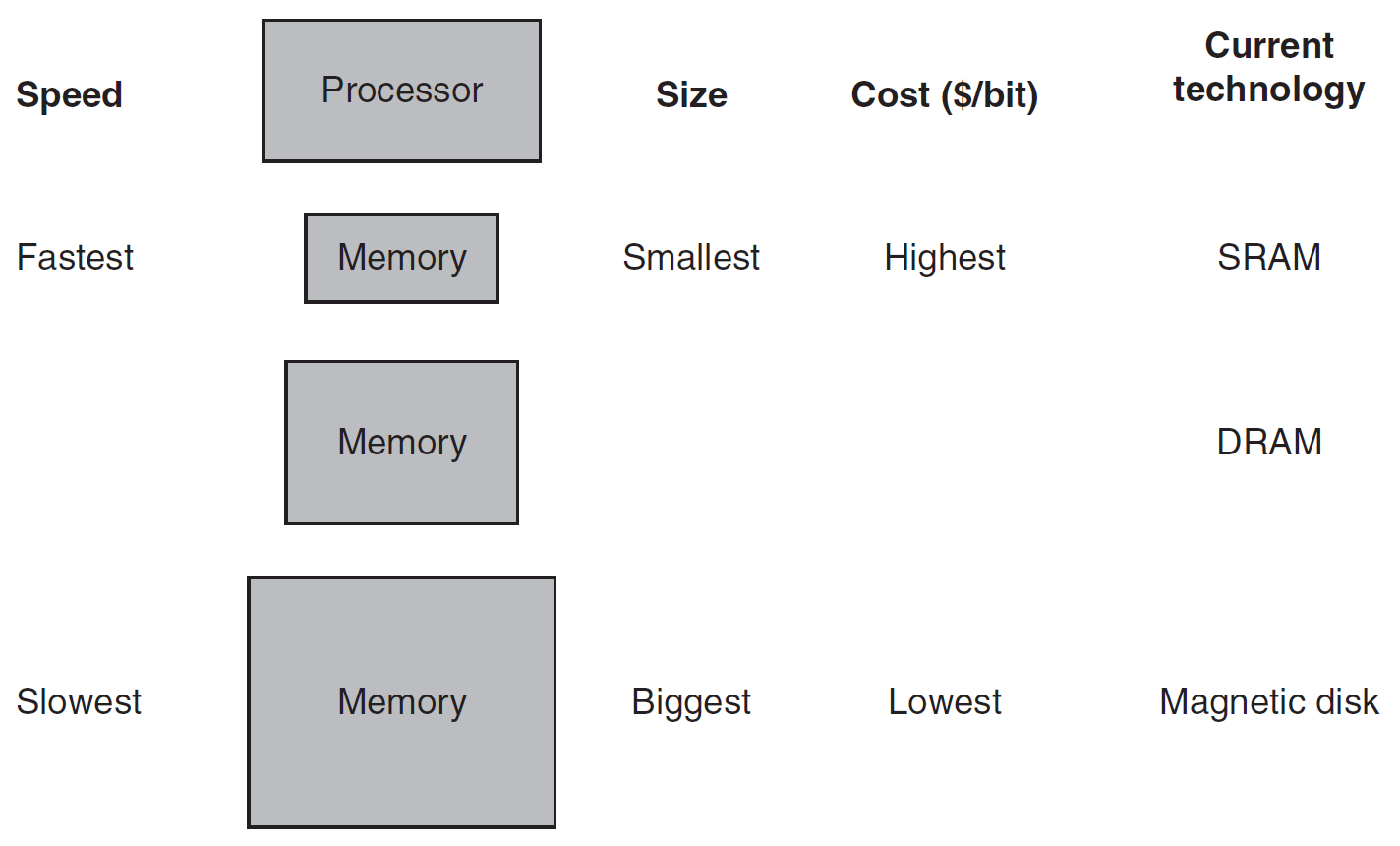
- faster → more expensive → smaller
- upper level
- closer to processor
- faster, more expensive, smaller
- lower level
- slower to access, bigger capacity
- line/block: min unit of info
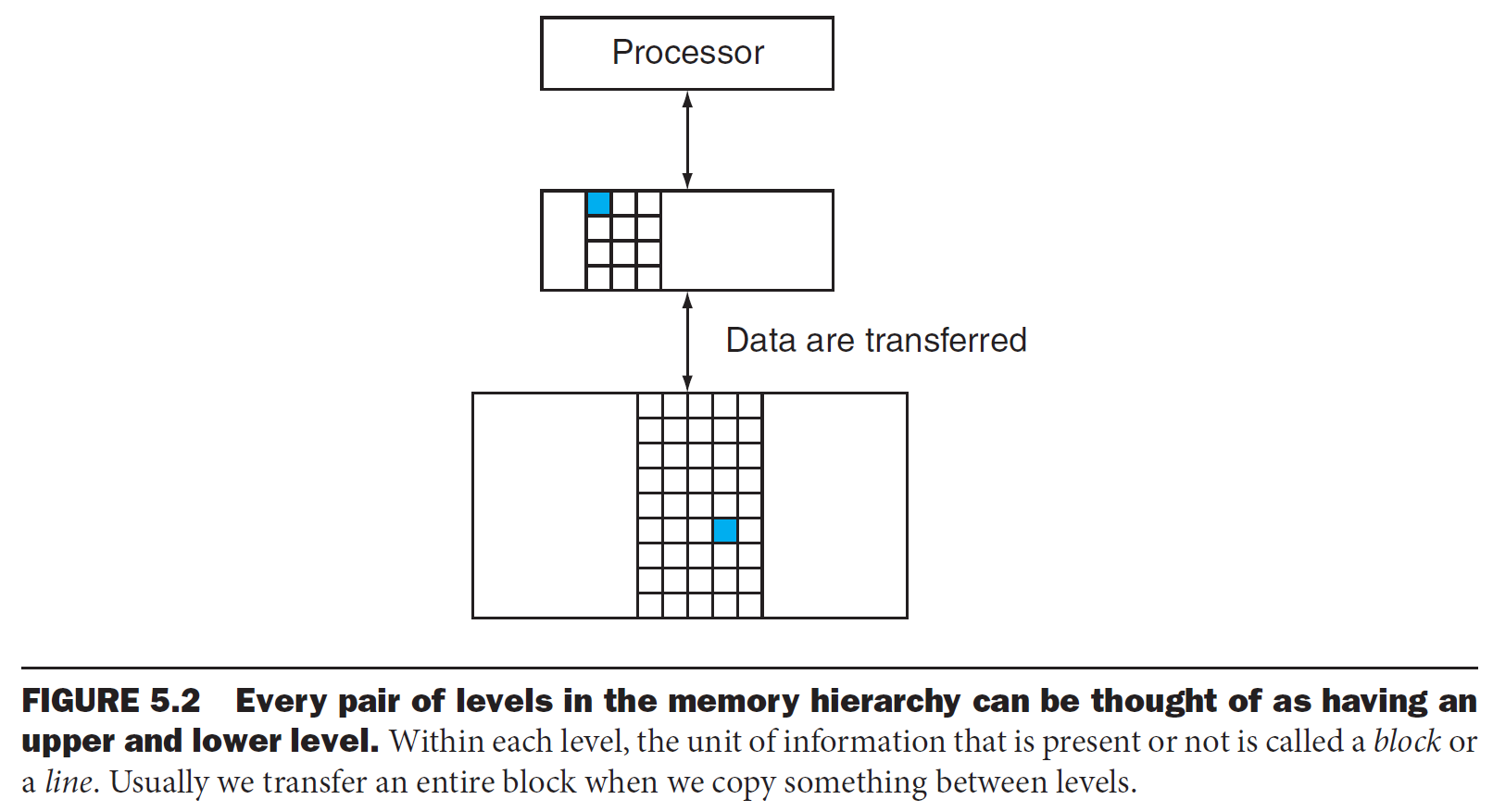
- data requested is in upper level → hit
- hit rate = # found in upper level / # access
- hit time = time to access upper level
- data request is not in upper level → miss
- mis rate = # not found in upper level / # access
- miss penalty = total time to fetch the requested block to the requested level
- access time + transmit time

memory¶
- DRAM
- slow
- smaller area used per bit → cheaper
- SRAM
- fast
- expensive
- used in upper levels
cache¶
- the memory between processor & main memory
- direct mapped cache
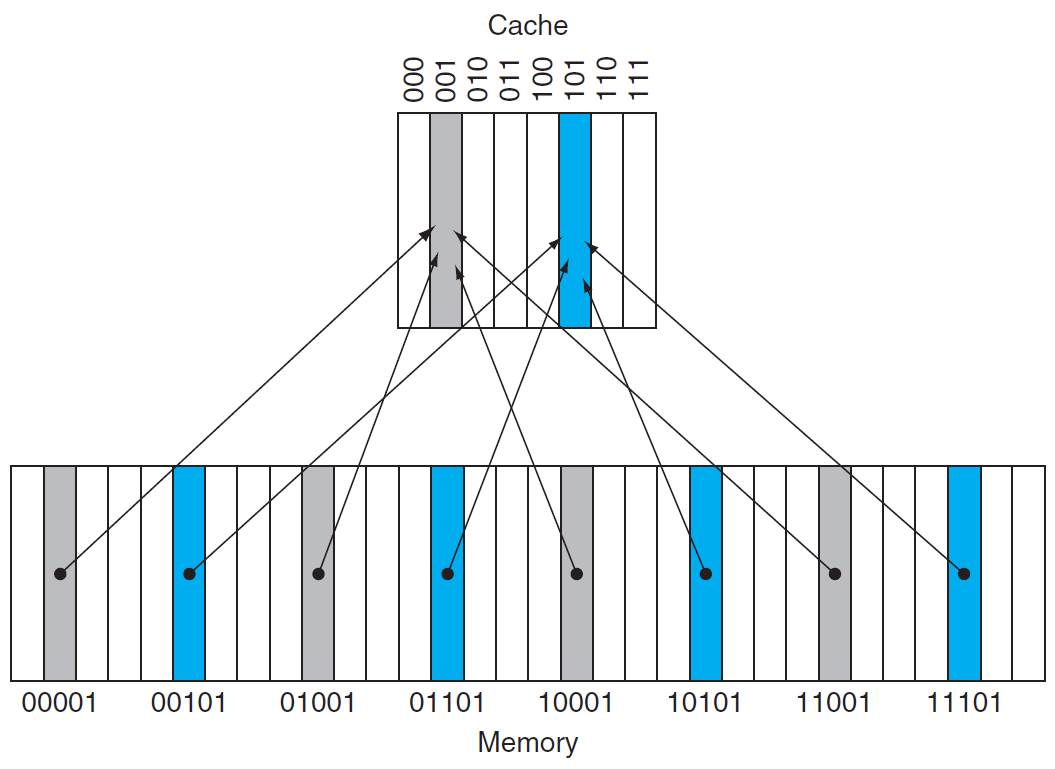
- map with block address % num of blocks
i.e. n entries/blocks → map with lower \(log_2n\) bits
- tag
- contain upper portion of block address (block address = {tag}{index})
- valid bit
- contain valid address or not
- not valid → don't match

- total size calculation
- cache size = \(2^{n+m}\) words = \(2^n\) blocks
- e.g. 16KiB = \(2^{14}\) bytes = \(2^{12}\) words
- block size = \(2^m\) words
- word size = address size = \(2^k\) bytes
- 32 bit address → 1 word = 32 bits = \(2^2\) bytes
- 64 bit address → 1 word = 64 bits = \(2^3\) bytes
- tag size (bits) = address size (bits) - (n+m+k) = address size (bits) - \(log_2\) cache size (bytes)
- offset = block offset + byte offset = lg of how many bytes per block
- block offset = lg of how many words per block
- 2-word block → block offset = 1
- byte offset = lg of how many bytes per word
- block offset = lg of how many words per block
- 1 valid bit
- total size = \(2^n\) x (block size + tag size + valid size) bits
- every block need original + tag & valid bits
- i.e. 原本的 cache size 加上 tag & valid 總共所需的 bits
- e.g.
- cache size = \(2^{n+m}\) words = \(2^n\) blocks
- cache miss = search for a data in cache but find nothing
- miss rate = # miss / # all access
- e.g.
- block size vs. miss rate
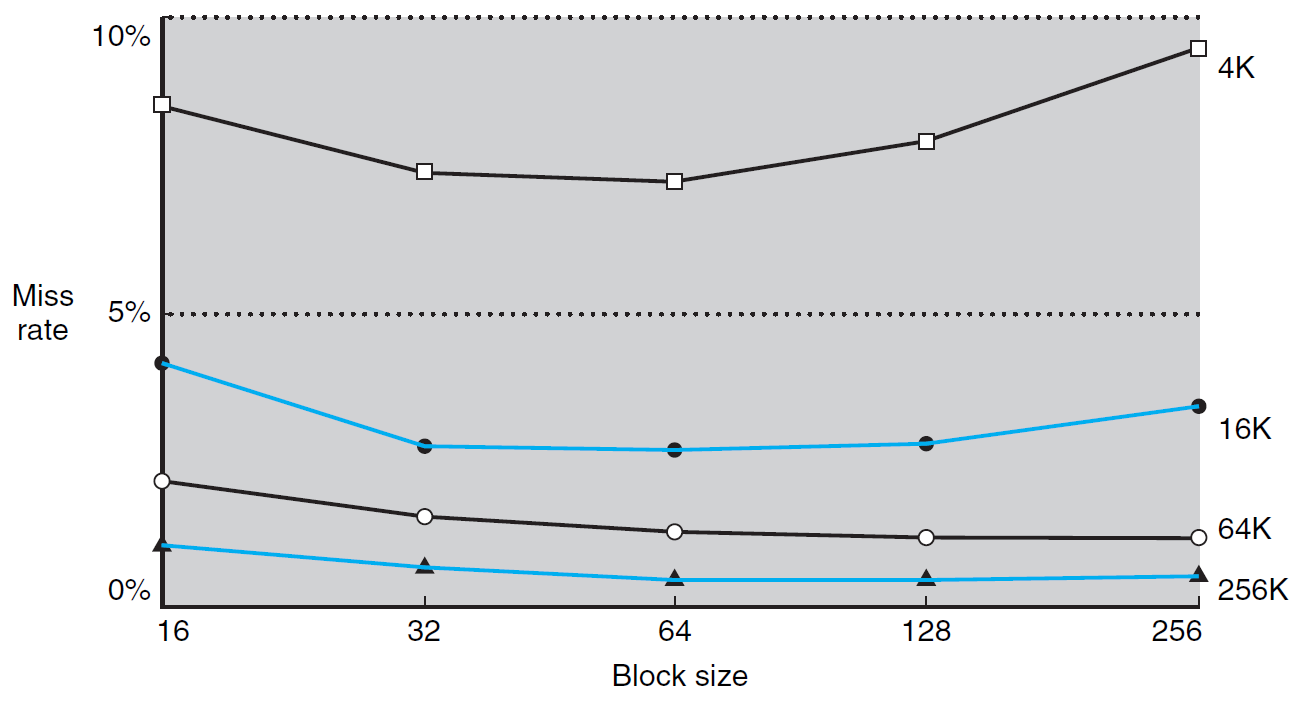
- larger block size → spatial locality → lower miss rate
- larger block size → fewer blocks can be held in cache → more competition, blocks would be bumped out of cache before all words is accessed → higher miss rate
- larger block size → hit time increases → slower
- larger block size → transfer time increase → bigger miss penalty
- miss → CPU pipeline stall → fetch block from lower level

- AMAT (average memory access time) = hit time + miss rate x miss penalty


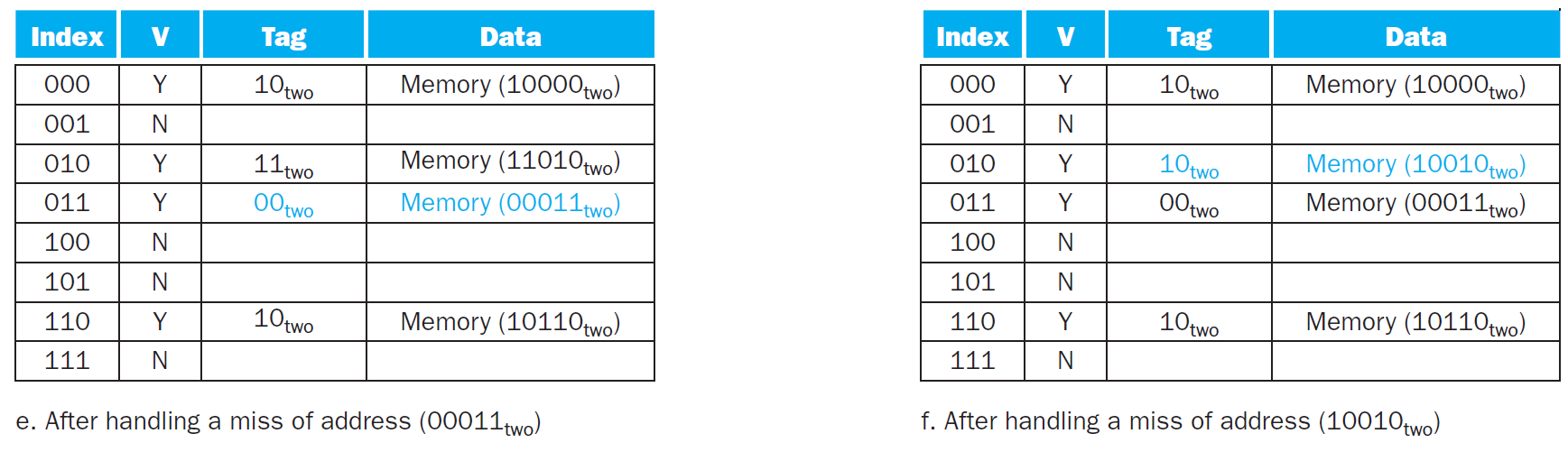
associative cache¶
- fully associative cache
- a block can be placed anywhere
- need to search all entries to find a block
- 1 comparator for each entry → costly
- set associative cache
- n-way → n blocks in each set, each block can placed in any block of that set
- indexed by (# block) % (# of set)
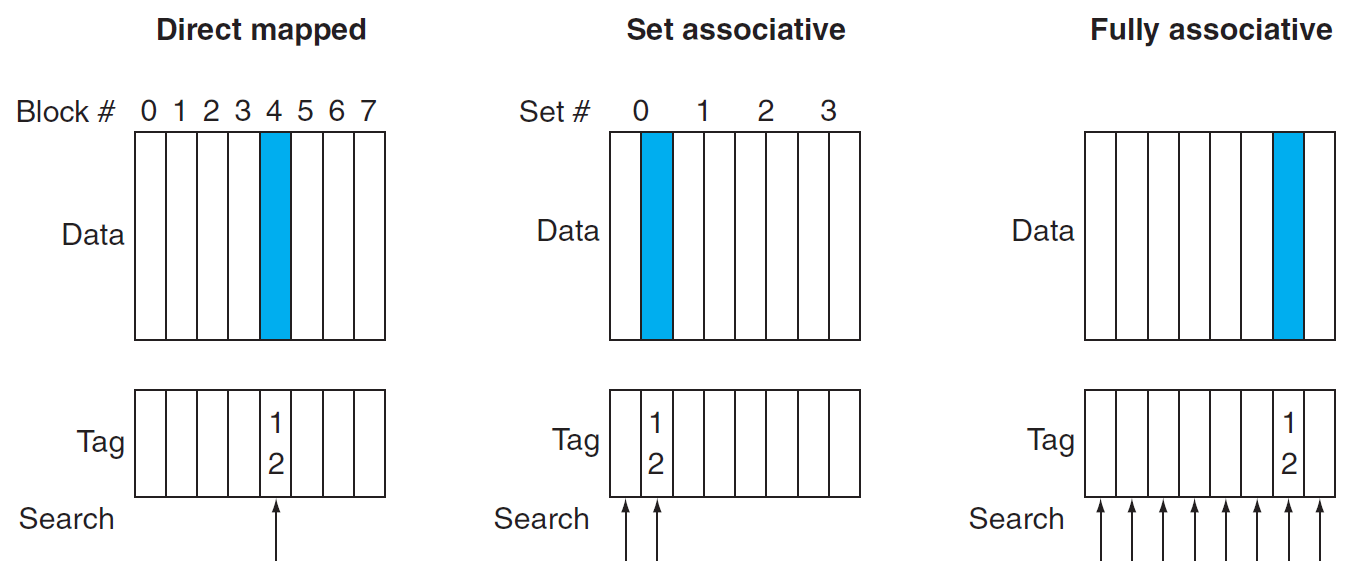
- middle: 2-way set associative cache i.e. each set has 2 blocks, so need to search 2 blocks
- replace policy
- least recently used (LRU)
- not scalable, hard for n-way with big n
- random
- same performance for whatever n
- least recently used (LRU)
- high associative → low miss rate
- e.g.
miss¶
- compulsory miss
- first time access, not in cache yet
- capacity miss
- cache capacity not enough to contain all blocks, so some is replaced
- conflict miss
- multiple blocks compete for same set
- in set-associative & direct-mapped caches

multilevel cache¶
- not in 1st level cache → search 2nd level cache
- higher miss penalty if not found in any level of cache
- 2-level
- primary
- focus on low hit time
- L-2
- focus on low miss rate
- primary
dependable memory hierarchy¶
- MTTF
- mean time to failure
- AFR
- annual failure rate
- 1 year / MTTF
- MTTR
- mean time to repair
- MTBF
- mean time between failures
- MTTF + MTTR
- availability = \(\dfrac{MTTF}{MTBF}\)
- improving MTTF
- fault avoidance
- fault tolerance
- use redundancy
- fault forecasting
- replace before failure
Hamming SEC/DED¶
- SEC, single error correcting
- DED, double error detecting code
- hamming distance
- min distance between 2 different bits
- e.g. 11111, 10101 → 2
- min distance between 2 different bits
- ECC
- mark \(2^k\)th bits as parity bits
- bit 0001 → check bits ending with 1
- bit 0010 → check bits ending with 01
- etc.
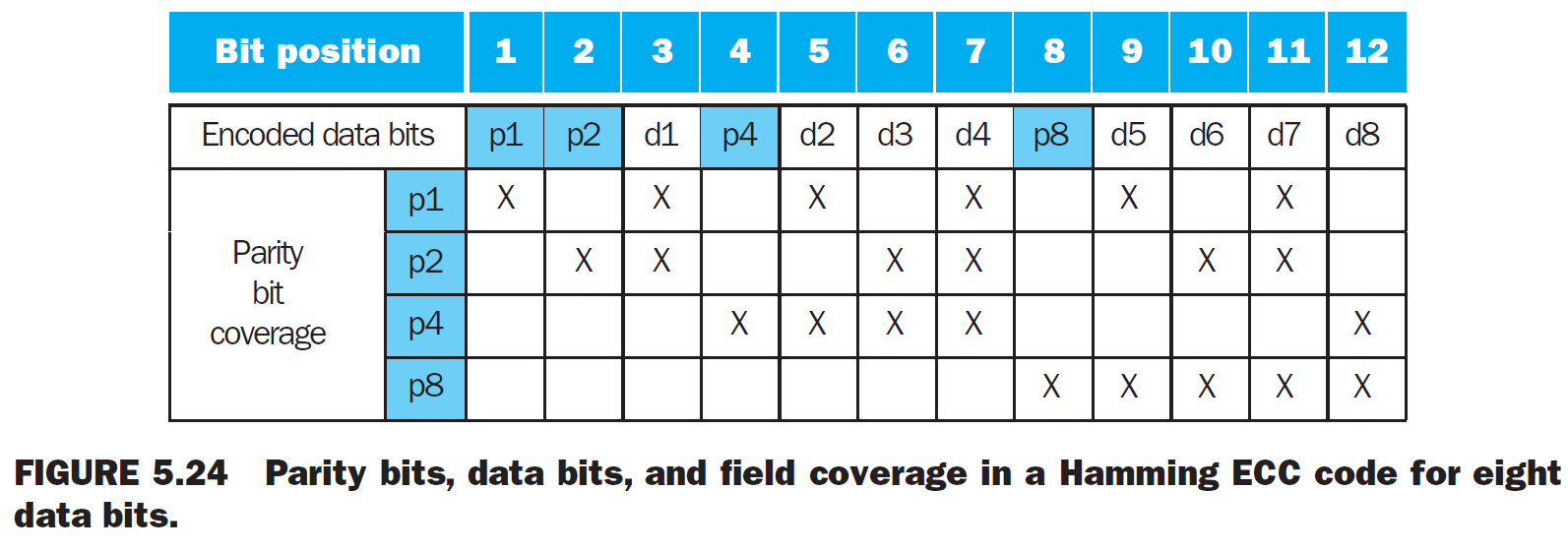
- parity (p8p4p2p1) is (1010)\(_2\) = 10 → bit 10 has error → invert bit 10 to correct it