Coalitional Games for Computation Offloading in NOMA-Enabled Multi-Access Edge Computing¶
my part in 2021.10.29 Game Theory Study Group Presentation: Coalition Game
source: https://ieeexplore.ieee.org/document/8917566
intro¶
- MEC, multi-access edge computing
- aka MeNB ==???==
- provide computing capabilities within the radio access network at the network edge
- low latency
- save energy
- higher reliability
- OMA, orthogonal multiple access
- serve each with an unoccupied subcarrier / time slot
- only use a small fraction of a spectrum sometimes
- NOMA, nonorthogonal multiple access
- UEs can share the same resource block with NOMA
- e.g. OFDM (orthogonal FDM) subcarrier
- transmitter side
- superpose signals from various users
- receiver side
- interference cancellation to decode the signals
- accommodate more UEs than the number of available subcarriers
- key tech for massive connectivities
- e.g. IoT
- can enable grant-free access & flexible scheduling → more UEs served simultaneously → reduce latency
- better than OMA
- can utilize all subcarriers channels
- fairness provisioning (?)
- spectral efficiency
- data rate in a bandwidth in a communication
- tradeoff of subcarrier sharing
- more choice, less waste
- will receive noise from other users on the same subcarrier, resulting to bigger transmission latency & computation overhead
- e.g.
- 1 small but time-sensitive packet & 1 big but latency-tolerant packet, with 2 orthogonal subcarriers → packet 1 & part of packet 2 for UE1, the remaining packet 2 for UE2
- UEs can share the same resource block with NOMA
- UE, user equipment
- existing papers
- single-carrier NOMA-based MEC
- NOMA+MEC → substantially reduce latency & energy consumption
- this paper's contribution
- multi-carrier NOMA-based MEC
- more general
- never studied before
- distributed coalition formation game based algorithm
- low time complexity
- convergence guarantee
- aims to minimize total computation
- achieve Nash-equilibrium
- multi-carrier NOMA-based MEC
system model¶
network model¶
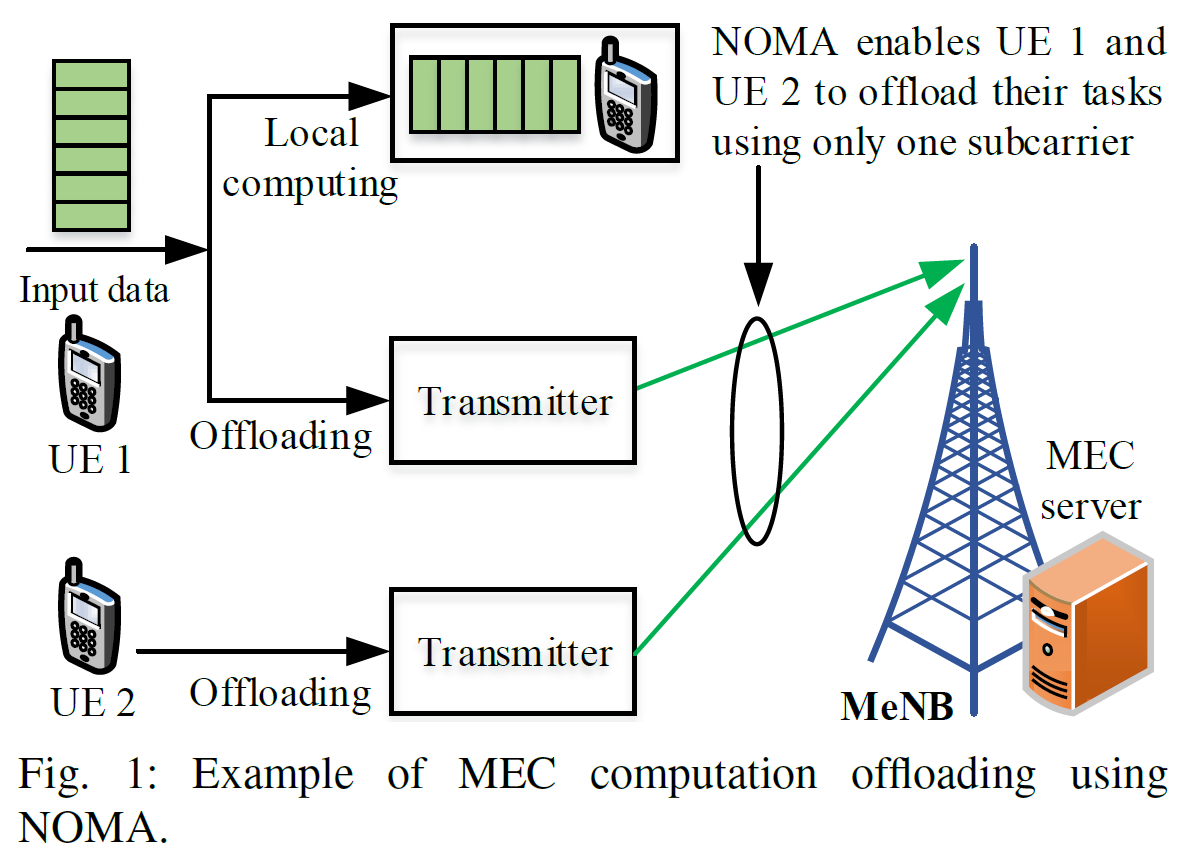 - N UEs
- \(\mathcal{N}=\{1,...,N\}\)
- 1 MEC
- \(\mathcal{S}=\{1,...,S\}\)
- quasi-static Rayleigh fading
- UEs don't change in offloading period & vary independently between 2 periods
- UEs & MeNB has 1 antenna
- NOMA → the signal MeNB receives contain interference signal from co-sharing UEs
- each UE can only use 1 subcarrier
- ==但 intro 的例子裡,big packet 是用兩個?==
- N UEs
- \(\mathcal{N}=\{1,...,N\}\)
- 1 MEC
- \(\mathcal{S}=\{1,...,S\}\)
- quasi-static Rayleigh fading
- UEs don't change in offloading period & vary independently between 2 periods
- UEs & MeNB has 1 antenna
- NOMA → the signal MeNB receives contain interference signal from co-sharing UEs
- each UE can only use 1 subcarrier
- ==但 intro 的例子裡,big packet 是用兩個?==
communication model¶
- offloading decision profile \(A=\{a_{ns}|n\in \mathcal{N},s\in S\}\)
- UE n use subcarrier s → \(a_{ns}=1\)
- UE n don't use subcarrier s → \(a_{ns}=0\)
- 1 UE use 0 or 1 subcarrier → \(\displaystyle{\sum_{s\in S}\leq1,\forall n\in \mathcal{N}}\)
- signal-to-interference-plus-noise ratio (SINR)
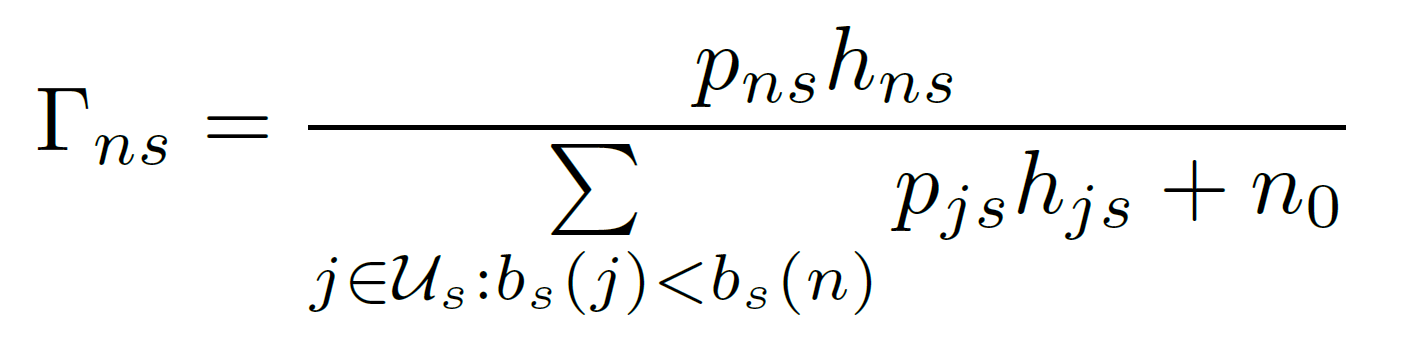
- j with \(b_s(j)<b_s(n)\) isn't decoded by UE n → noise ==(???)==
- uplink channel gain \(h_{ns}\)
- of UE \(n\) on subcarrier \(s\)
- sorted in ascending order
- transmit power \(p_{ns}\)
- of UE \(n\) on subcarrier \(s\)
- noise power \(n_0\)
- achievable transmission rate \(R_n\)
- \(R_{ns}=Blog_2(1+\Gamma_{ns})\) ==(???)==
- for subcarrier \(s\)
- B = bandwidth of an orthogonal carrier
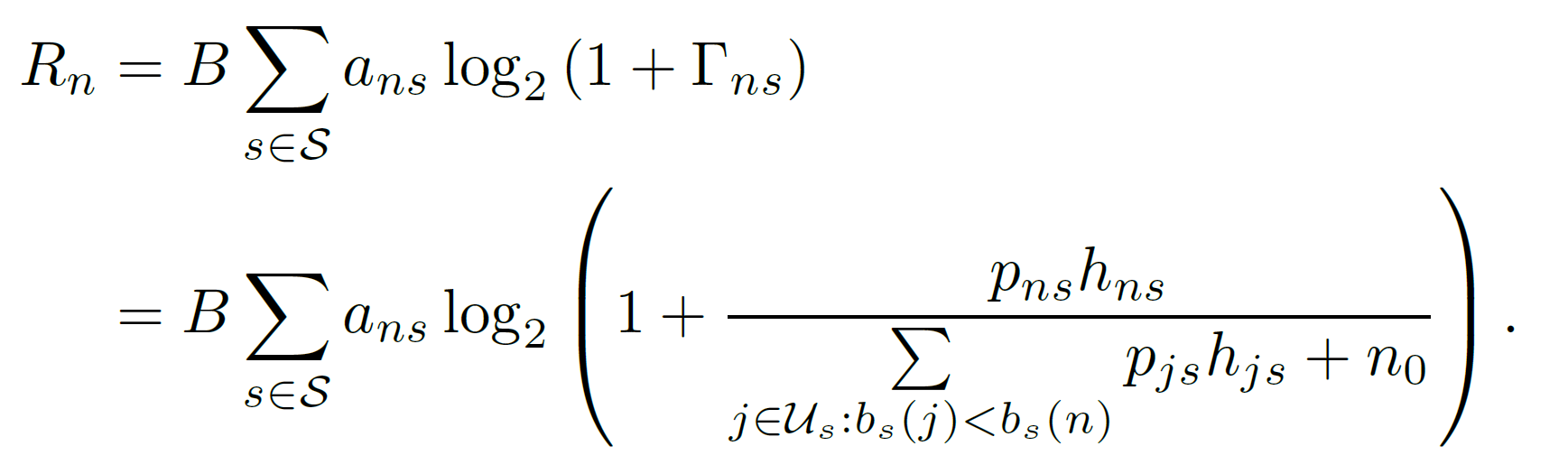
- \(R_n\) = sum(\(R_{ns}\))
- \(R_{ns}=Blog_2(1+\Gamma_{ns})\) ==(???)==
computation model¶
- offloading decision
- local execution
- all in local, no offloading
- full offloading
- all in remote edge server
- partial offloading
- some local some remote`
- binary offloading
- either local or full offloading
- local execution
- local execution → \(x_n=1\)
full offloading → \(x_n=0\) - 1 UE use 0 or 1 subcarrier → \(\displaystyle{\sum_{s\in S}a_{ns}=x_n}\)
- local i.e. use 0 subcarrier → = 0
- computation task \(I_n=\{\alpha_n,\beta_n\}\)
- \(\alpha_n\) = data size of \(I_n\)
- \(\beta_n\) = required CPU cycles to finish \(I_n\)
local execution¶
- completion time \(T^l_n=\dfrac{\beta_n}{f^l_n}\) = execution time
- \(f^l_n\) = UE n's local computing capability
- energy consumption \(E^l_n=\kappa\beta_n(f^l_n)^2\)
- \(\kappa_n\) = constant factor dependent on hardware architecture
- computation overhead \(Z^l_n=\lambda^t_nT^l_n+\lambda^e_nE^l_n\)
- \(\lambda^t_n,\lambda^e_n\) = weighted parameters, decided by UE's offloading decision
- e.g. latency-sensitive → set \(\lambda^t_n\) higher
- \(\lambda^t_n,\lambda^e_n\) = weighted parameters, decided by UE's offloading decision
full offloading¶
- completion time = uplink transmission time + execution time
\(T^r_n=\dfrac{\alpha_n}{R_n}+\dfrac{\beta_n}{f^l_n}\)- \(f_n\) = remote computing resources
- MEC give each UE a fixed amount of \(f_n\)
- data size / transmission rate + CPU cycles / computing resource
- \(f_n\) = remote computing resources
- total energy consumption = task offloading + remote computing + result downloading
- UE's energy consumption = task offloading
\(E^r_n=\dfrac{p_n}{\varsigma_n}T^t_n=\dfrac{p_n}{\varsigma_n}\dfrac{\alpha_n}{R_n}\) ==(???)==- \(\varsigma_n\) = UE power amplifier efficiency
- computation overhead \(Z^r_n=\lambda^t_nT^r_n+\lambda^e_nE^r_n\)
problem formulation¶
- goal: minimize total computation overhead
- total computation overhead \(Z(A)=\displaystyle{\sum_{n\in \mathcal{N}}(x_nZ^r_n+(1-x_n)Z^l_n)}\)

- mixed-integer programming (MIP) problem
- binary & integer variables ==(???)==
- NP-hard → limited applications
- mixed-integer programming (MIP) problem
coalition game¶
- UE's decision: execute locally OR through a subcarrier
- N UEs & S subcarriers → S+N coalitions (可能 execute 的地方有 S+N 個,N locally & S in subcarriers)
- coalitions \(\mathcal{F}=\{\mathcal{F_1,...,\mathcal{F}_{S+N}}\}\)
- \(\cup^{S+N}_{j=1}\mathcal{F}_j=\mathcal{N}\)
- \(\mathcal{F}_j\) with \(1\leq j\leq S\) → the set of UEs using subcarrier j
- \(\mathcal{F}_j\) with \(S+1\leq j\leq S+N\) → UE j executes locally
- more UEs using 1 subcarrier → more complex to cancel interference → transmission latency & computation overhead increase → SINR reduces, lower channel gains
- \(\mathfrak{R}\) = real-valued coalition payoff function
- coalition \(\mathcal{F}_k\) with \(1\leq k\leq S\)
- total computation overhead by all UEs
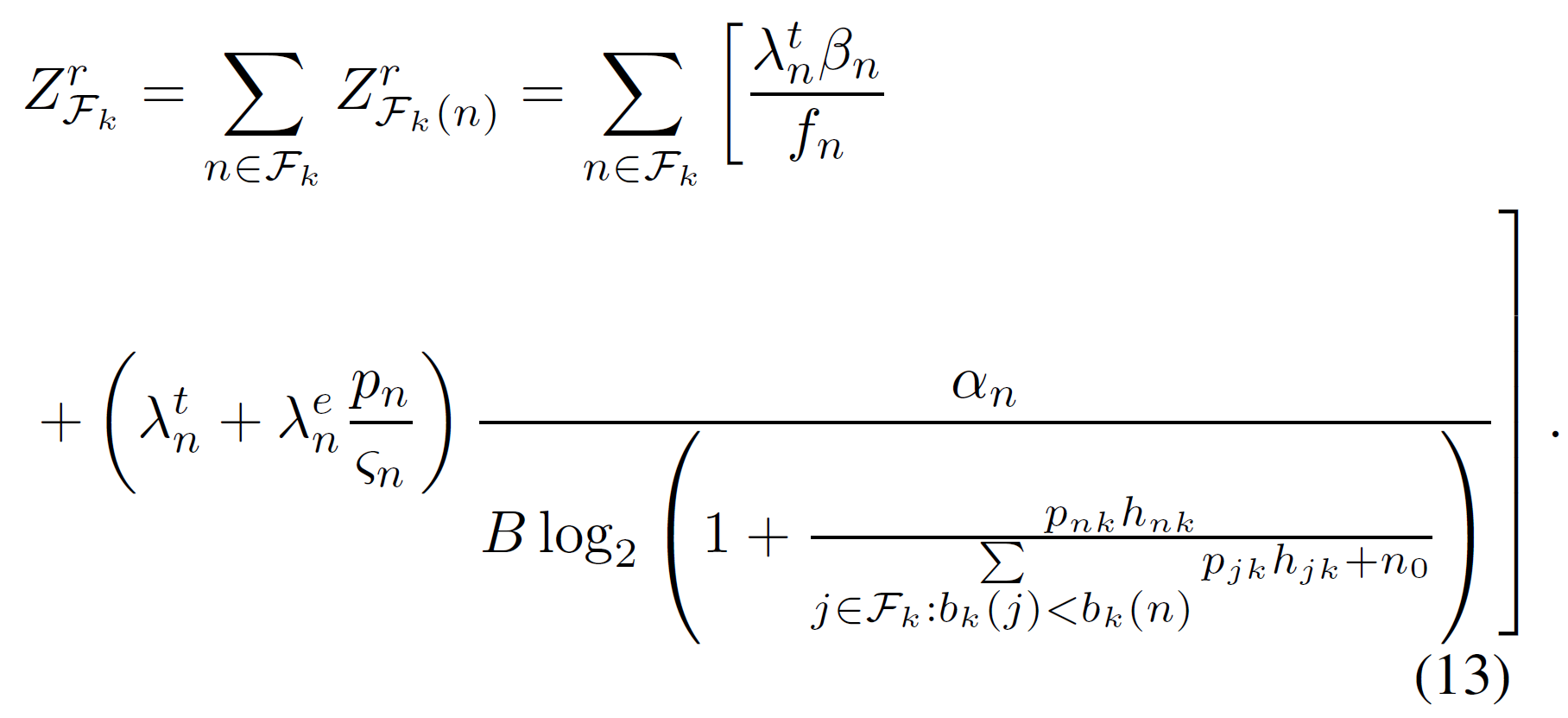
- \(Z^r_n =\lambda^t_nT^r_n+\lambda^e_nE^r_n\)
\(=\lambda^t_n(\dfrac{\alpha_n}{R_n}+\dfrac{\beta_n}{f^l_n})+\lambda^e_n\dfrac{p_n}{\varsigma_n}\dfrac{\alpha_n}{R_n}\) - \(R_n =R_{nk}=Blog_2(1+\Gamma_{ns})\)
- \(Z^r_n =\lambda^t_nT^r_n+\lambda^e_nE^r_n\)
- utility \(\mathfrak{R}(\mathcal{F}_k)\) = computation if executed locally - computation if in coalition
- total computation overhead by all UEs
- coalition \(\mathcal{F}_k\) with \(S+1\leq k\leq S+N\)
- utility \(\mathfrak{R}(\mathcal{F}_k)=0\)
- utility = how much computation overhead you save comparing to local execution
- utility \(\mathfrak{R}(\mathcal{F}_k)=0\)
- \(\mathcal{F}_s\) is strictly preferred to \(\mathcal{F}_k\) \(\iff\) utility of \(\mathcal{F}_s\) with UE n + utility of \(\mathcal{F}_k\) without UE n is greater than the reverse situation for all n && no other UE j in \(\mathcal{F}_s\) and \(\mathcal{F}_k\) is negatively affected by UE n joining
- ==???只看得出來不是負的而無法看出 not negatively affected???==
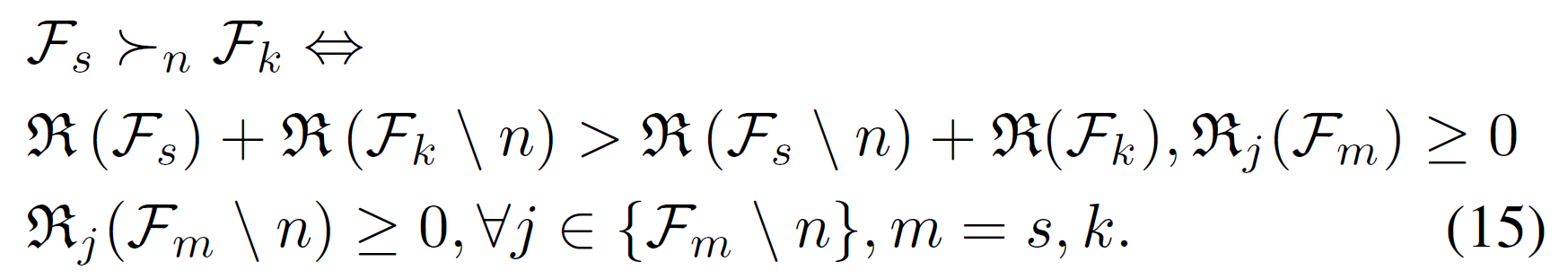
- switch from k to s
- \(I_n\) executed locally → \(\mathcal{F_{S+n}}=\{n\}\) i.e. the UE executing locally in n is n && \(\mathcal{F_{S+n}}\cap \mathcal{F_k}=\emptyset\) \(\forall k\neq (S+n)\)
- \(I_n\) executed in subcarrier s → \(\mathcal{F_{S+n}}=\emptyset\) i.e. the UE executing locally in n is nothing && \(n\in\mathcal{F_{s}}\) i.e. the UEs executed in subcarrier s includes n
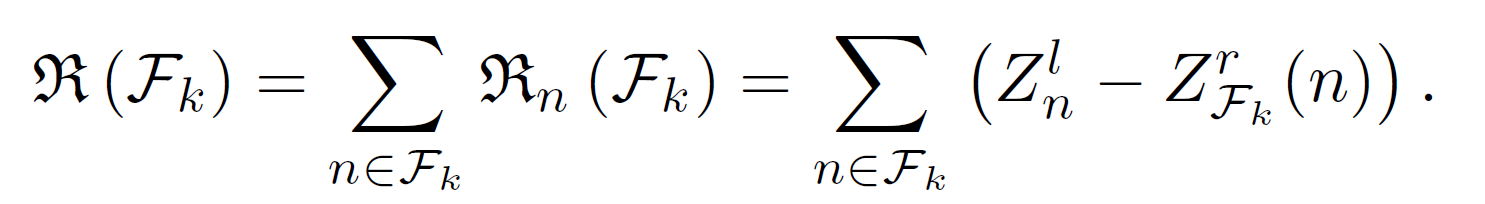
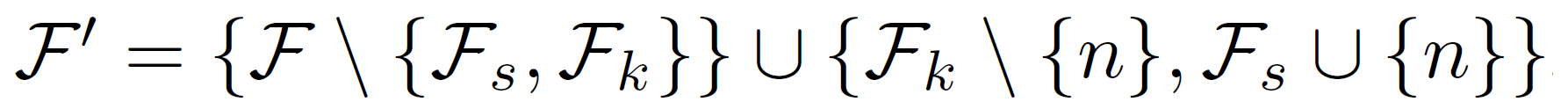
algorithm¶

- keep switching until stable
- num = unsuccessful consecutive switch operations i.e. how many iterations since last switch
- algorithm terminates when num = 10 x amount of UEs
analysis¶
- convergence: a final Nash-stable partition \(\mathcal{F}_{fin}\) is guaranteed
- \(\because\) each switch creates a new partition and the number of partitions is finite
- stability: \(\mathcal{F}_{fin}\) is Nash-stable
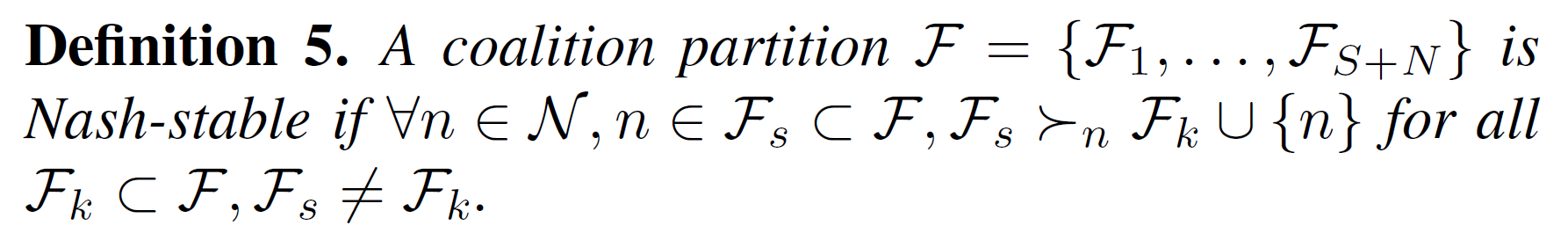
- trivial
- complexity \(\in O(\)number of iterations\()\)
- at most 1 switch in each iteration
simulation results¶
settings¶
- UEs randomly positioned within the range of MeNB coverage
- min distance between UE & MeNB = 5m
- pathloss of distance d from UE to MeNB \(L(d)=15.3+37.6log(d)\)
- noise power \(n_0\) = -100dB
- transmit power = 100mW
- subcarrier bandwidth B = 1MHz
- computation model: facial recognition app
- \(\alpha_n=420KB\)
- \(\beta_n=1000\) megacycles
- local computing capability \(f^1_n\) random from \(\{0.5, 0.8, 1.0\}GHz\)
- MEC allocates 1GHz for each offloading UE → \(f_n=1GHz\)
- UE weights \(\lambda^t_n=\lambda^e_n=0.5\)
- 3 schemes
- LCO, local computing only
- COO, computation offloading only
- HOO, heuristic orthogonal offloading
- OMA
- a subcarrier can only be used by 1 UE
- typically S<N → S UEs with highest computational gain from offloading use all the subcarriers, while the other N-S UEs compute locally
- proposed #algorithm
- each UE can choose between executing locally or offloading to remote
- each UE has S+1 options → \(\in O(N^{S+1})\) → only simulate N=4~9 in this paper
vs. optimal scheme¶
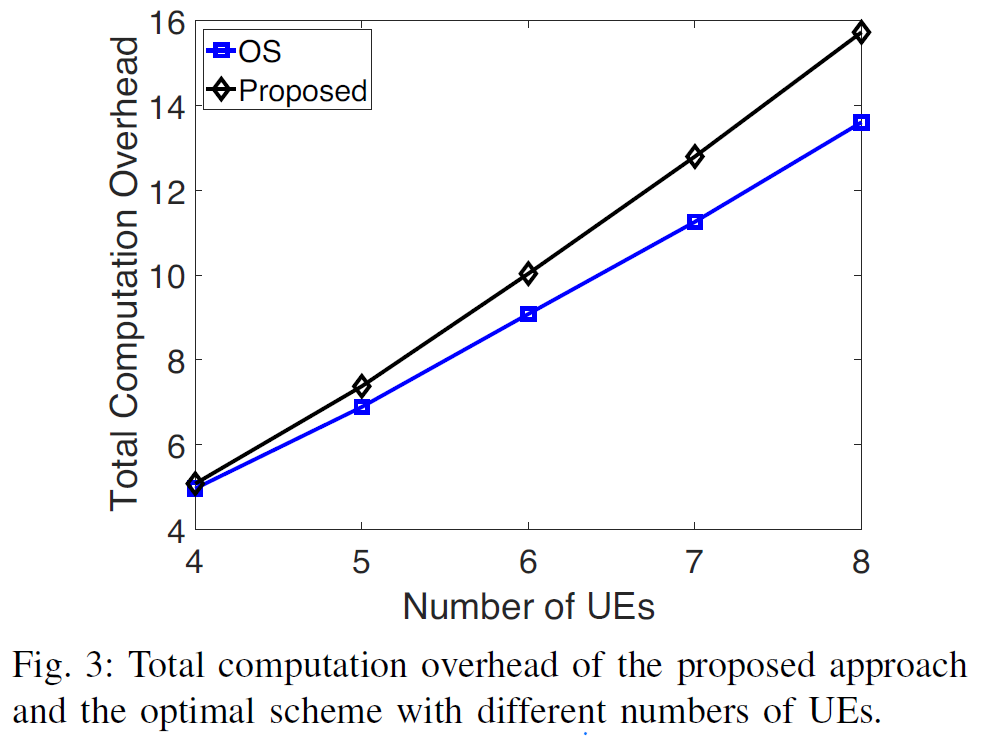 perform close to the optimal scheme
perform close to the optimal scheme
% of offloading UEs¶
vs. number of UEs¶
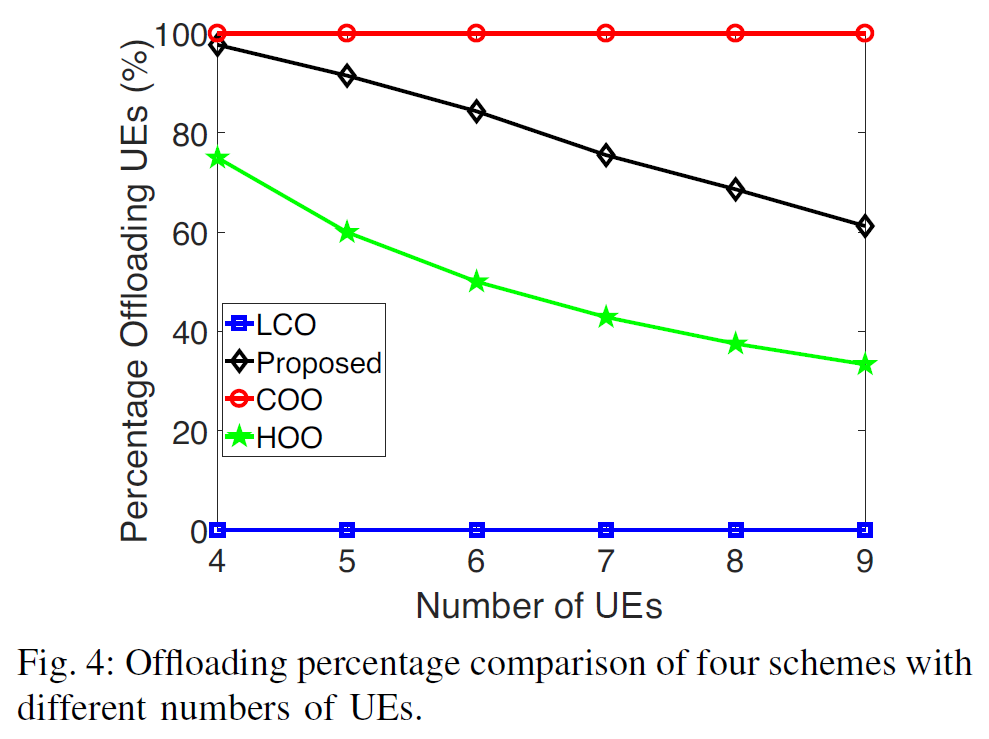 - fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- more UEs → more competition for subcarriers → less favorable offloading is
- NOMA (proposed) enables more UEs to benefit from offloading than OMA (HOO) does
- fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- more UEs → more competition for subcarriers → less favorable offloading is
- NOMA (proposed) enables more UEs to benefit from offloading than OMA (HOO) does
vs. number of coalitions¶
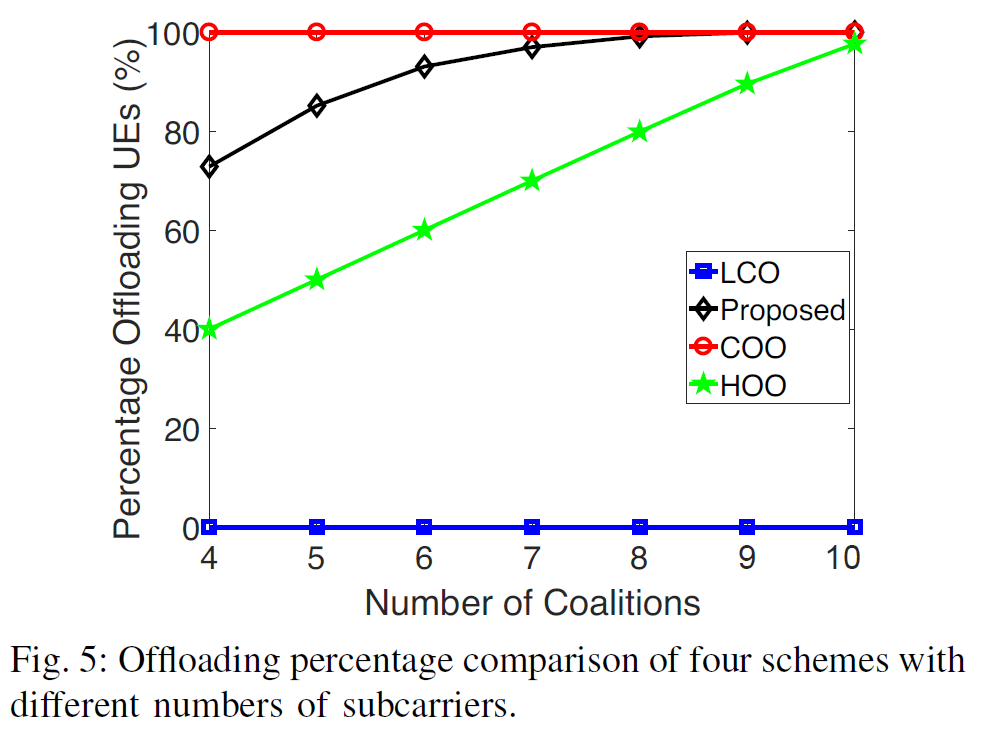 - fix number of UEs to 10 i.e. \(N=10\)
- more subcarriers → more choice for UEs → more favorable offloading is
- NOMA (proposed) enables more UEs to benefit from offloading than OMA (HOO) does
- fix number of UEs to 10 i.e. \(N=10\)
- more subcarriers → more choice for UEs → more favorable offloading is
- NOMA (proposed) enables more UEs to benefit from offloading than OMA (HOO) does
total computation overhead¶
vs. number of UEs¶
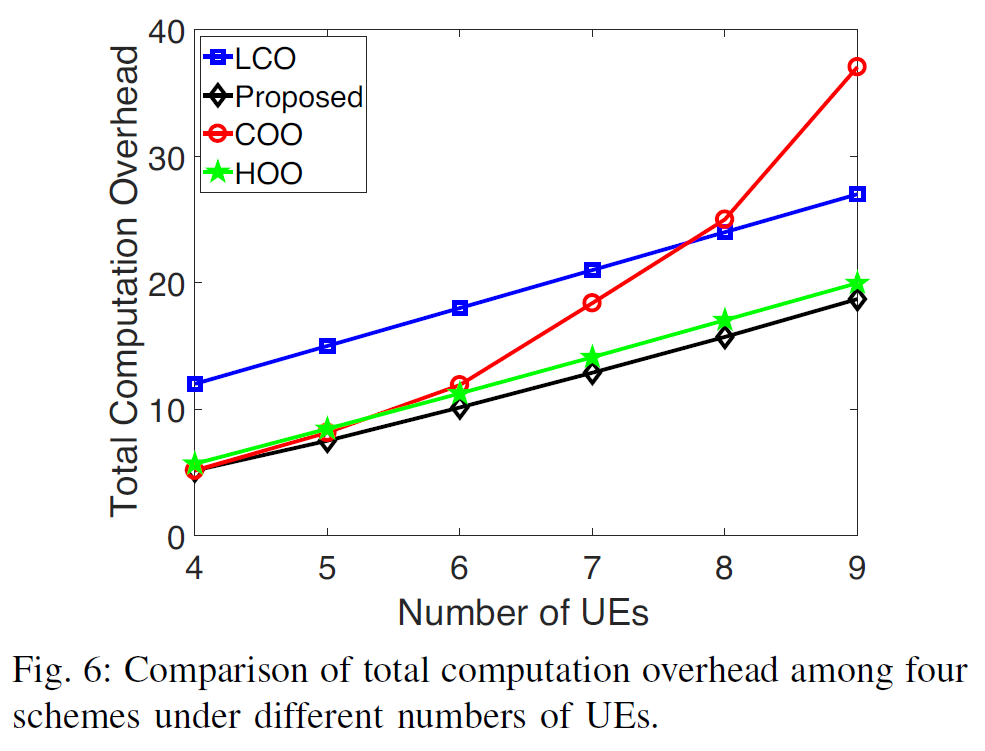 - fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- proposed scheme has smallest computation overhead
- more UEs → more computation overhead
- in COO (100% offloading),
- fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- proposed scheme has smallest computation overhead
- more UEs → more computation overhead
- in COO (100% offloading),
more UEs
→ more UEs sharing the same subcarrier
→ more intra-coalition interference
→ total computation overhead increases more dramatically with UE increasing than in other schemes
→ LCO (100% local) better than COO with large number of UEs
vs. number of coalitions¶
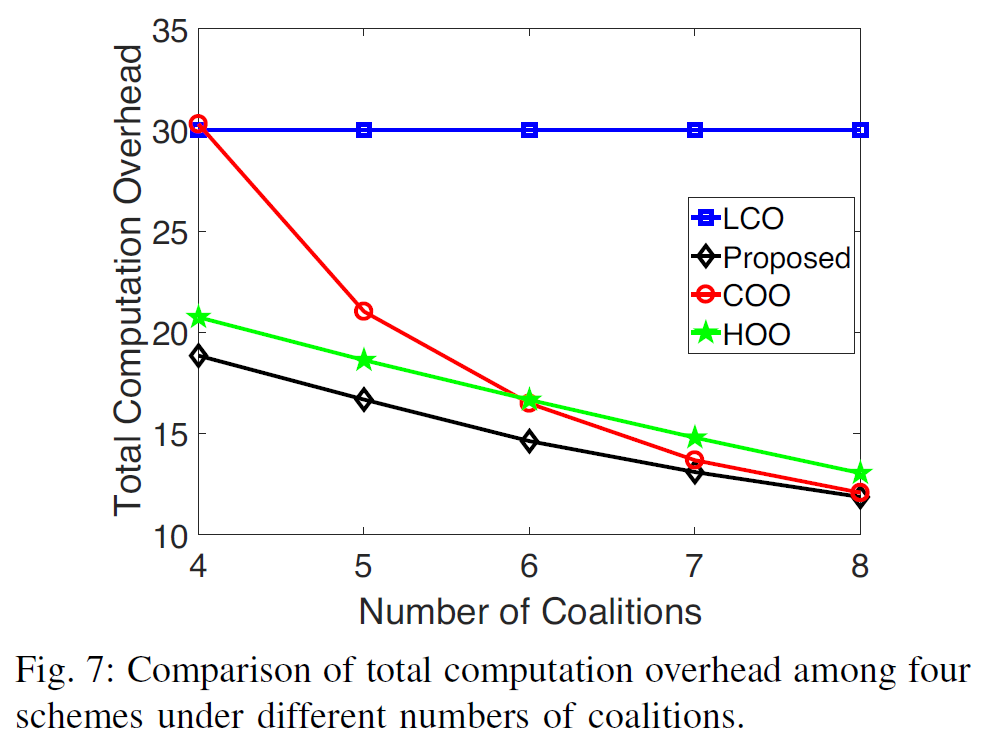 - fix number of UEs to 10 i.e. \(N=10\)
- proposed scheme has smallest computation overhead
- if offloading is available, more subcarriers → better chance for an UE to choose the preferred subcarrier → less computation overhead
- more subcarriers → less difference between the three offloading-available schemes
- fix number of UEs to 10 i.e. \(N=10\)
- proposed scheme has smallest computation overhead
- if offloading is available, more subcarriers → better chance for an UE to choose the preferred subcarrier → less computation overhead
- more subcarriers → less difference between the three offloading-available schemes
vs. remote computing resources¶
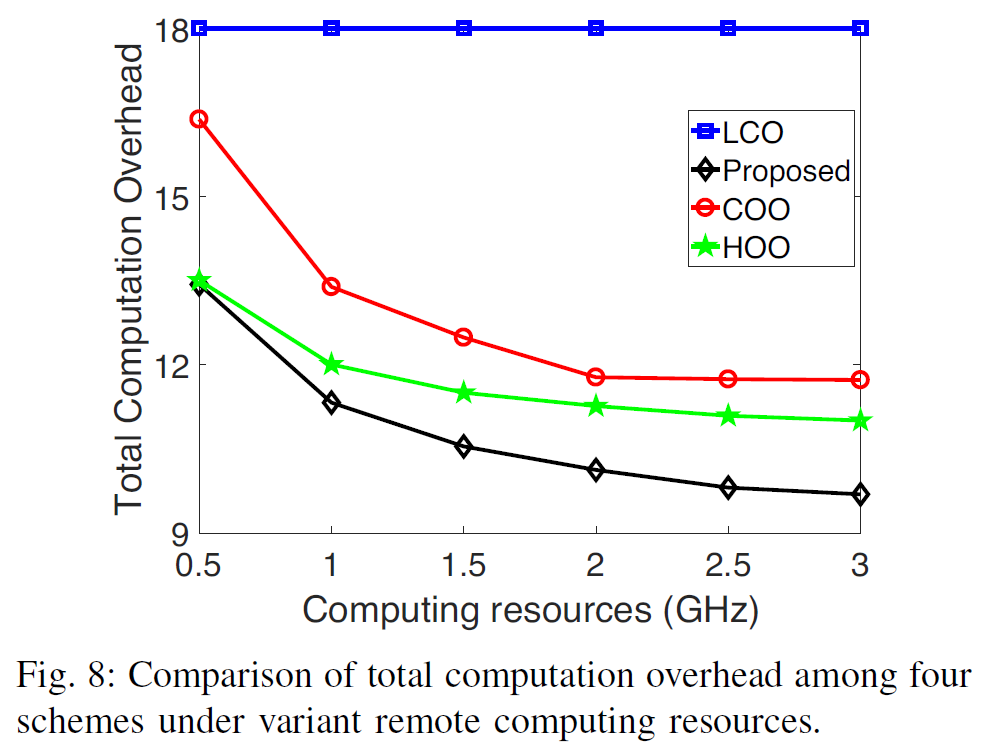 - fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- fix number of UEs to 6 i.e. \(N=6\)
- proposed scheme has smallest computation overhead
- fix number of coalitions/subcarriers to 3 i.e. \(S=3\)
- fix number of UEs to 6 i.e. \(N=6\)
- proposed scheme has smallest computation overhead
vs. transmit power¶
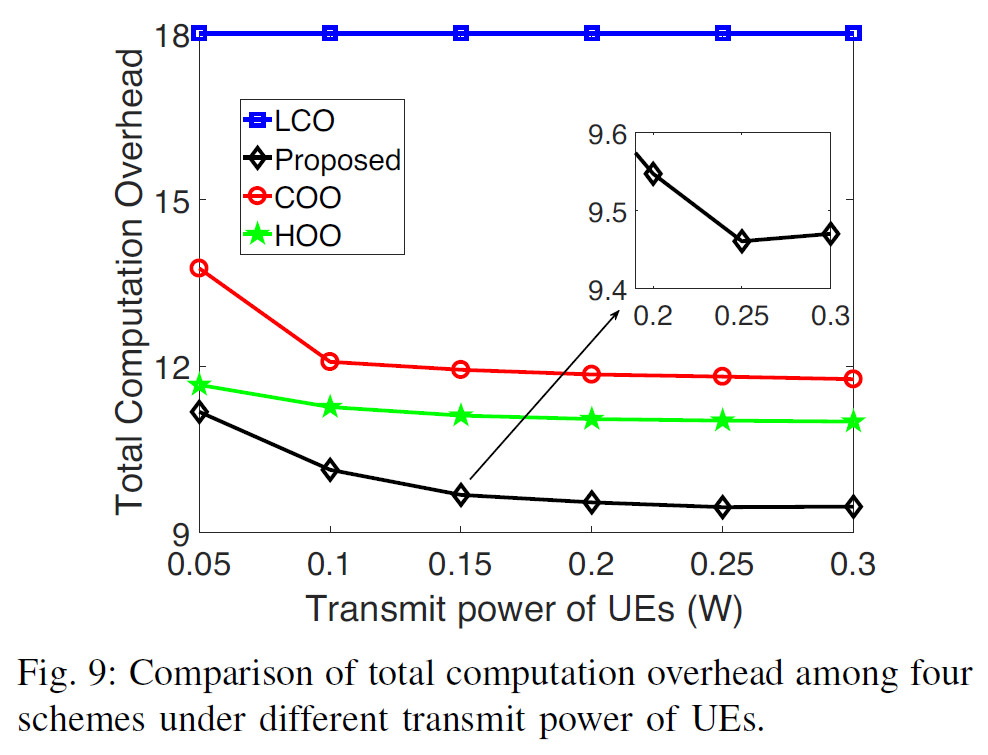
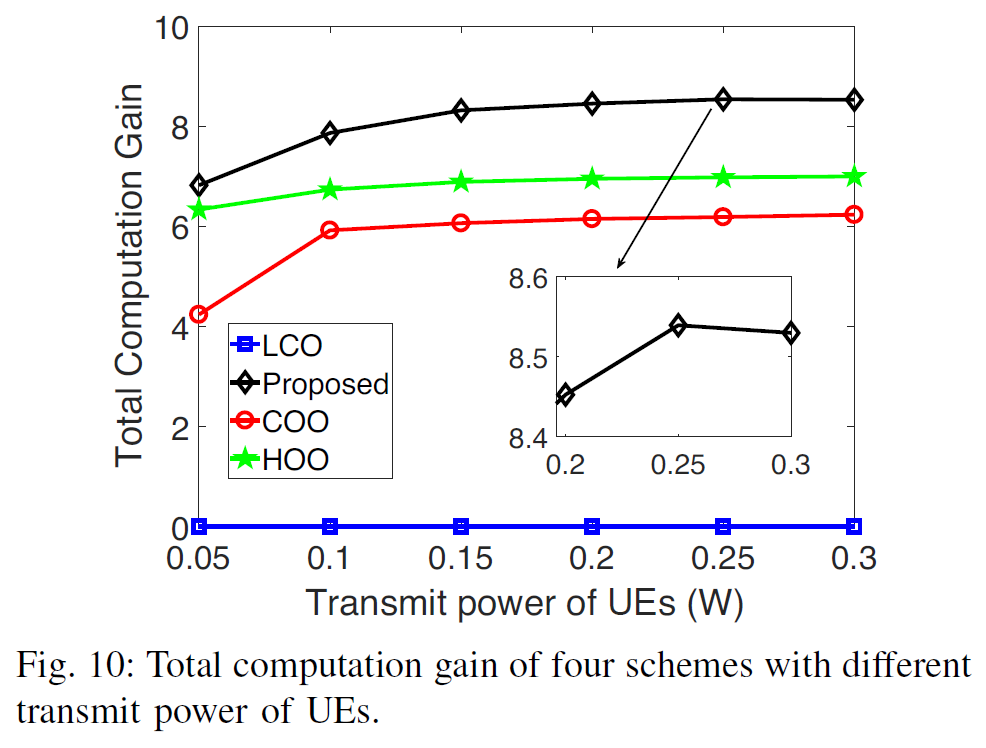 - proposed scheme has smallest computation overhead
- more transmit power → higher transmission rate → uplink transmission time & remote computation overhead reduce
- when transmit power is sufficiently large, inter-coalition interference is severe → transmission rate drops → computation overhead increases (0.2W-0.3W in Fig. 9) ==???==
- computation gain = how much computation you save from choosing offloading over local execution so LCO's computation gain = 0
- proposed scheme has smallest computation overhead
- more transmit power → higher transmission rate → uplink transmission time & remote computation overhead reduce
- when transmit power is sufficiently large, inter-coalition interference is severe → transmission rate drops → computation overhead increases (0.2W-0.3W in Fig. 9) ==???==
- computation gain = how much computation you save from choosing offloading over local execution so LCO's computation gain = 0
convergence rate¶
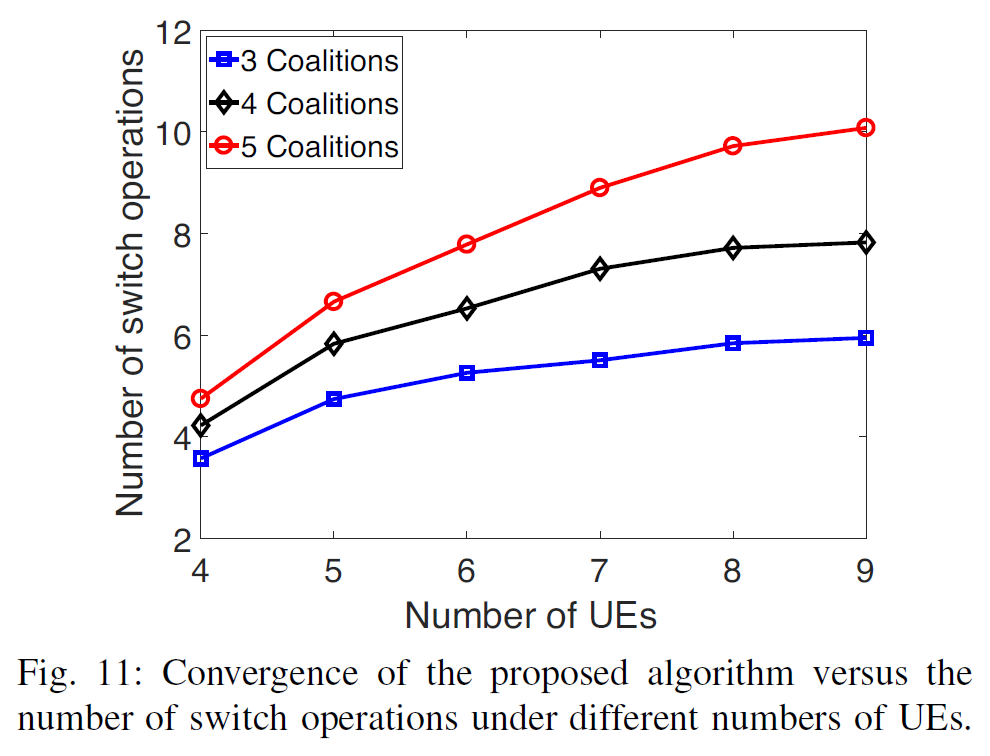 - more subcarriers → more options for subcarriers with good channel condition to reduce uplink transmission rate → converges slower
- converges rapidly
- more subcarriers → more options for subcarriers with good channel condition to reduce uplink transmission rate → converges slower
- converges rapidly
conclusion¶
- proposed algorithm is competitive to the optimal scheme (from 暴力搜索)
- proposed scheme beats the other 3 schemes in terms of offloading percentage, computation overhead & convergence rate